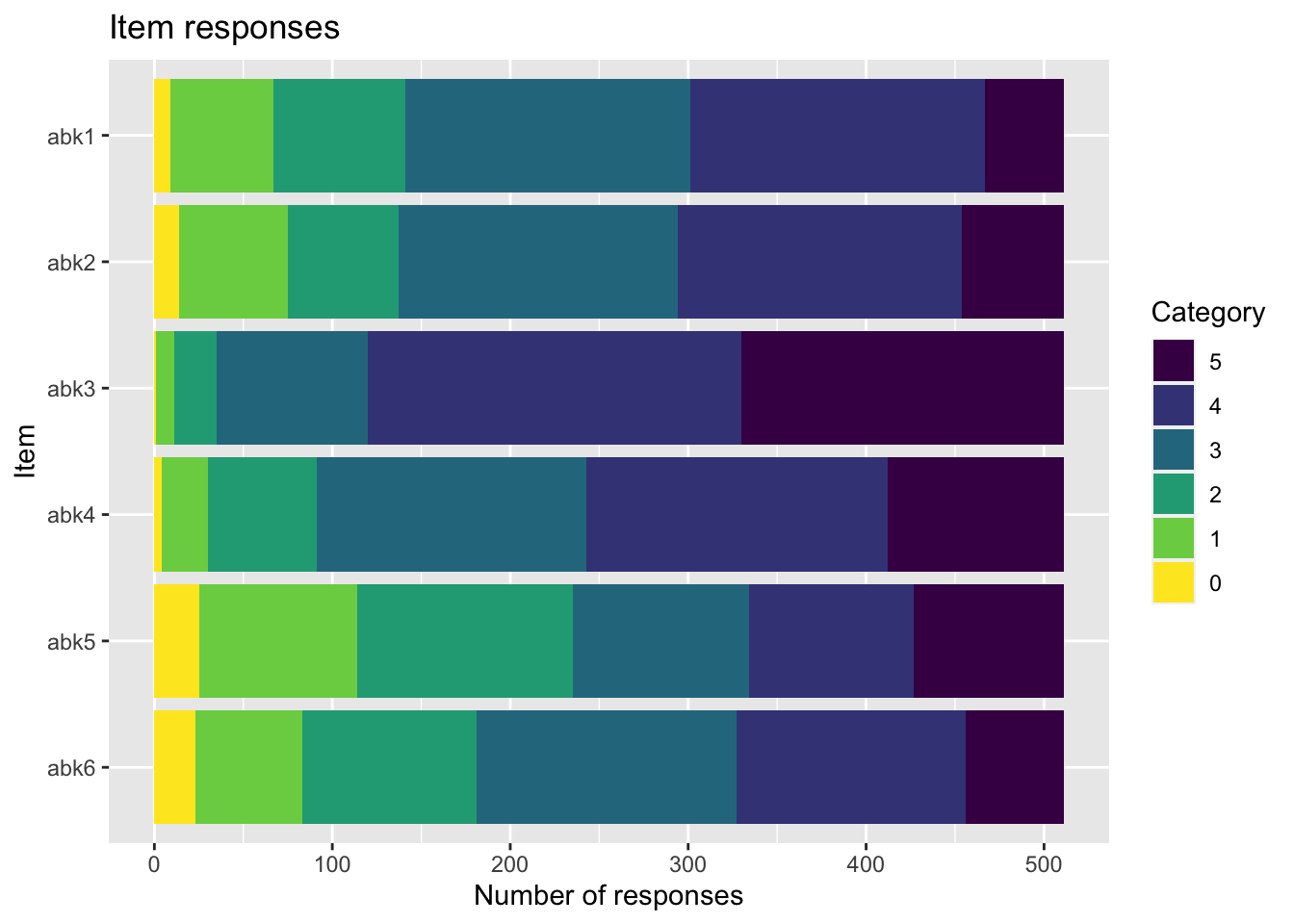
library(foreign)library(readxl)library(RISEkbmRasch) # devtools::install_github("pgmj/RISEkbmRasch")library(grateful) library(ggrepel)library(car)library(kableExtra)library(readxl)library(tidyverse)library(eRm)library(mirt)library(psych)library(ggplot2)library(psychotree)library(matrixStats)library(reshape)library(knitr)library(cowplot)library(formattable) library(glue)library(hexbin)library(skimr)### some commands exist in multiple packages, here we define preferred ones that are frequently usedselect <- dplyr::selectcount <- dplyr::countrecode <- car::recoderename <- dplyr::rename# file paths will need to have "../" added at the beginning to be able to render document# get itemlabelsitemlabels <-read_excel("../data/Itemlabels.xlsx") %>%filter(str_detect(itemnr, pattern ="abk")) %>%select(!Dimension)spssDatafil <-"../data/2023-04-26 Prevent OSA-enkat.sav"# read SurveyMonkey datadf <-read.spss(spssDatafil, to.data.frame =TRUE) %>%select(starts_with("q0006"),q0001,q0002,q0003,q0004) %>%rename(Kön = q0002, Ålder = q0001,Bransch = q0003,Hemarbete = q0004)# SPSS format provides itemlabels too, we can save them in a dataframespssLabels <- df %>%attr('variable.labels') %>%as.data.frame()dif.kön <- df$Köndif.ålder <- df$Ålderdif.bransch <- df$Branschdif.hemarbete <- df$Hemarbetedf <- df %>%select(starts_with("q0006"))names(df) <- itemlabels$itemnr
3.1 Items
Code
itemlabels %>%kbl_rise(width =60)
itemnr
item
abk1
Min arbetsbelastning är rimlig.
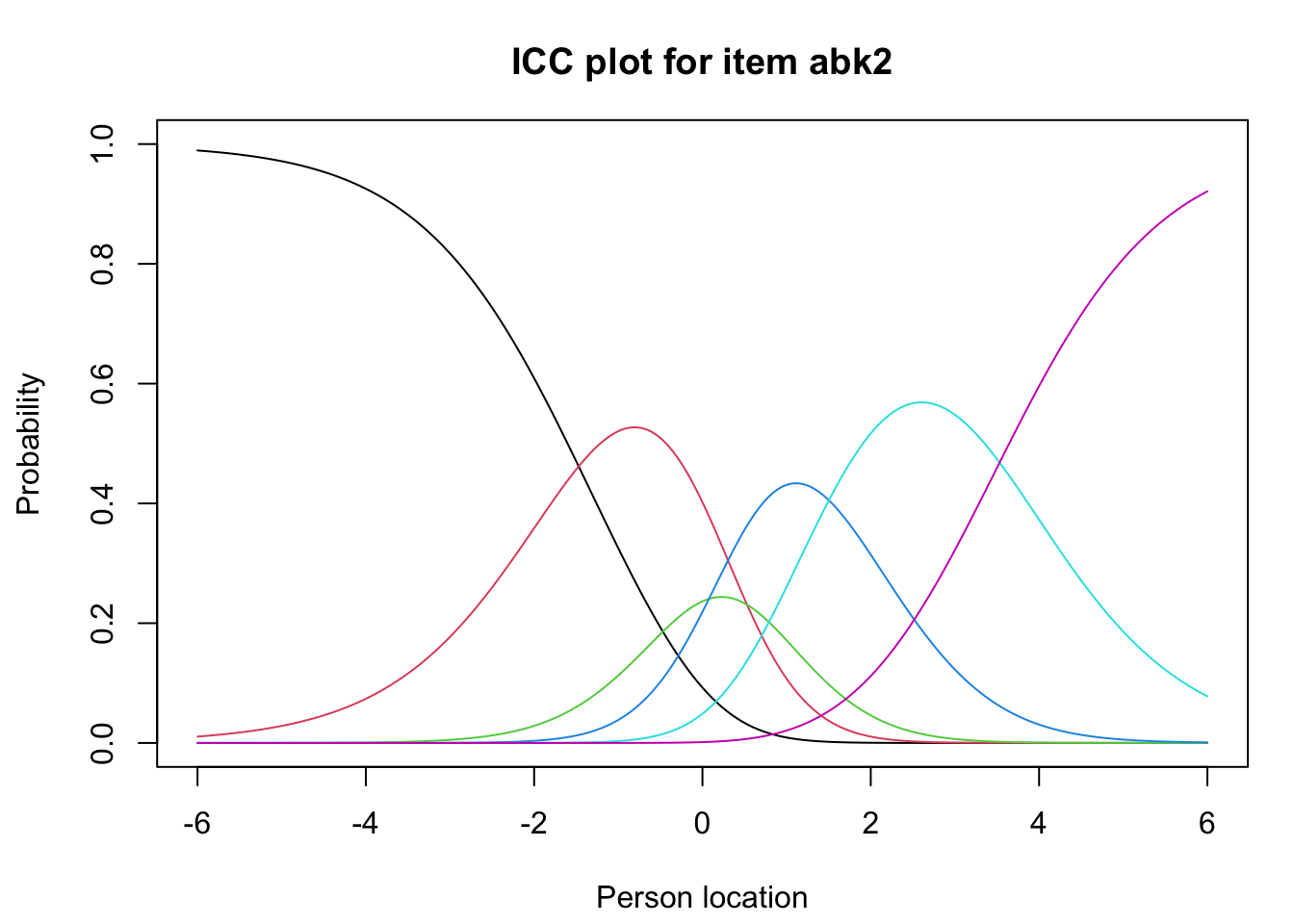
abk2
Jag hinner med mina arbetsuppgifter inom min arbetstid.
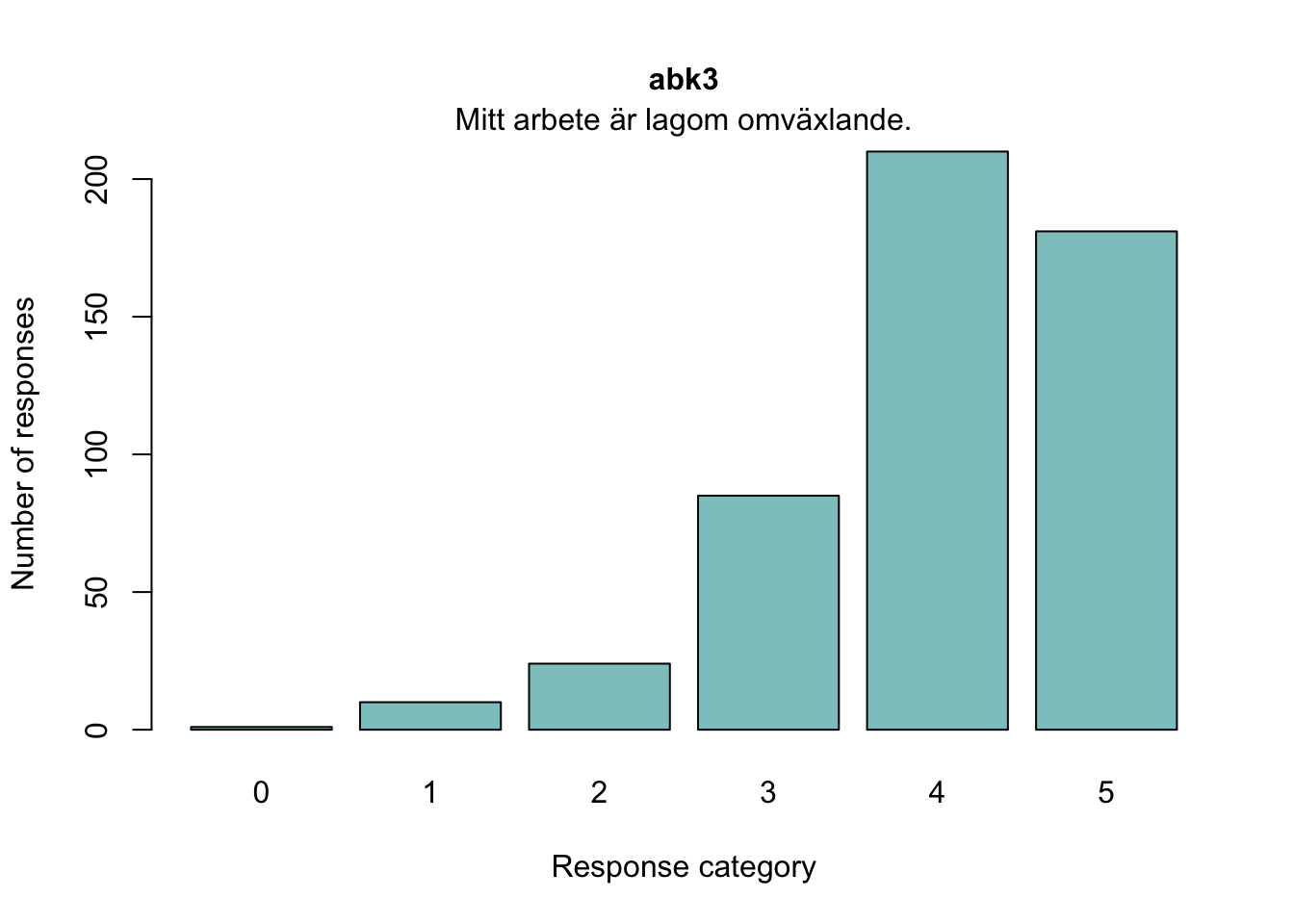
abk3
Mitt arbete är lagom omväxlande.
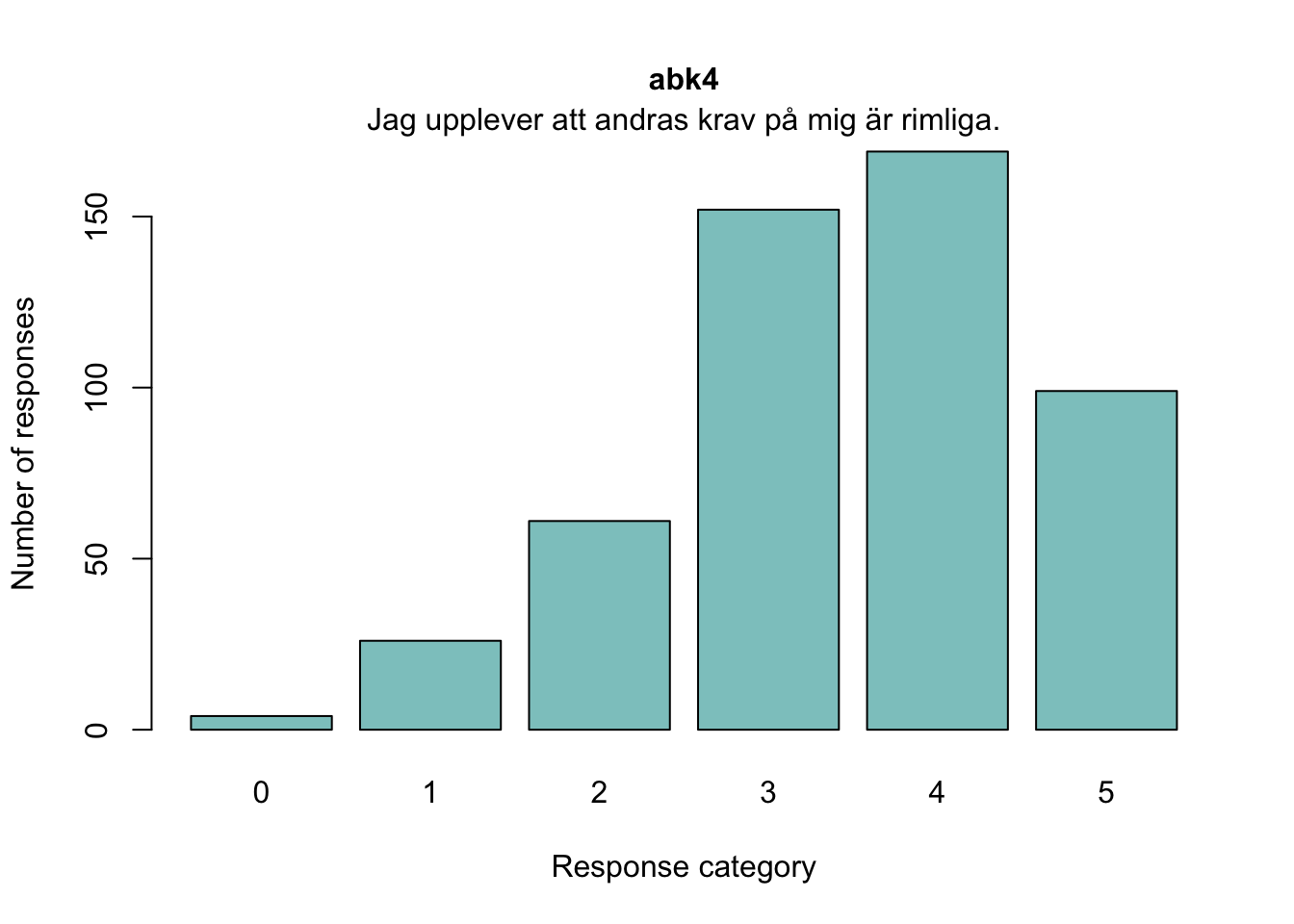
abk4
Jag upplever att andras krav på mig är rimliga.
abk5
Jag kan få hjälp om min arbetsbelastning är för hög.
abk6
Mitt arbete är fritt från psykiskt påfrestande arbetsuppgifter.
RIdemographics(dif.ålder,"Ålder") # kanske även fixa en figur?
Ålder
n
Percent
18-29
22
3.8
30-39
103
17.8
40-49
175
30.2
50-59
215
37.1
60+
64
11.1
Code
RIdemographics(dif.bransch,"Bransch")
Bransch
n
Percent
Kontorsarbete (oavsett bransch)
284
49.1
Industri
26
4.5
Hotell, restaurang, service
8
1.4
Handel
16
2.8
Skola, utbildning
67
11.6
Vård, omsorg
99
17.1
Byggverksamhet
7
1.2
Annat
71
12.3
Code
RIdemographics(dif.hemarbete,"Antal dagar med arbete hemifrån")
Antal dagar med arbete hemifrån
n
Percent
En dag
136
23.5
Två dagar
105
18.1
Tre dagar
35
6.0
Fyra dagar
10
1.7
Fem dagar
2
0.3
Jag arbetar aldrig eller sällan hemifrån
291
50.3
3.2.1 Svarsbortfall items
Vi filtrerar bort respondenter som har färre än två svar på frågorna i delskalan.
Code
# If you want to include participants with missing data, input the minimum number of items responses that a participant should have to be included in the analysis:min.responses <-2scale.items <- itemlabels$itemnr# Select the variables we will work with, and filter out respondents with a lot of missing datadf.omit.na <- df %>%filter(length(scale.items)-rowSums(is.na(.[scale.items])) >= min.responses)RImissing(df.omit.na,"abk")
Vi har extremt få saknade svar, och tar därför bort respondenterna som inte har kompletta svar.
Vi har väldigt få svar i lägsta kategorierna för item abk3. Vi slår därför ihop svarskategori 0 (aldrig) och 1 (sällan) för detta item så att efterföljande analyser kan utföras.
RIitemfitPCM2(df.omit.na, samplesize =250, nsamples =32, cpu =8)
OutfitMSQ
InfitMSQ
OutfitZSTD
InfitZSTD
abk1
0.58
0.576
-5.515
-5.651
abk2
0.682
0.697
-3.853
-3.916
abk3
1.223
1.194
1.79
2.102
abk4
0.603
0.619
-4.924
-4.86
abk5
0.991
0.983
-0.147
-0.24
abk6
1.068
1.056
1.093
0.695
Code
RIpcmPCA(na.omit(df.omit.na))
PCA of Rasch model residuals
Eigenvalues
1.92
1.39
1.20
0.89
0.58
Code
RIresidcorr(df.omit.na, cutoff =0.2)
abk1
abk2
abk3
abk4
abk5
abk6
abk1
abk2
0.46
abk3
-0.34
-0.41
abk4
-0.07
-0.1
0.07
abk5
-0.22
-0.19
-0.18
-0.3
abk6
-0.28
-0.33
-0.15
-0.1
-0.28
Note:
Relative cut-off value (highlighted in red) is 0.037, which is 0.2 above the average correlation.
Code
RIloadLoc(df.omit.na)
Code
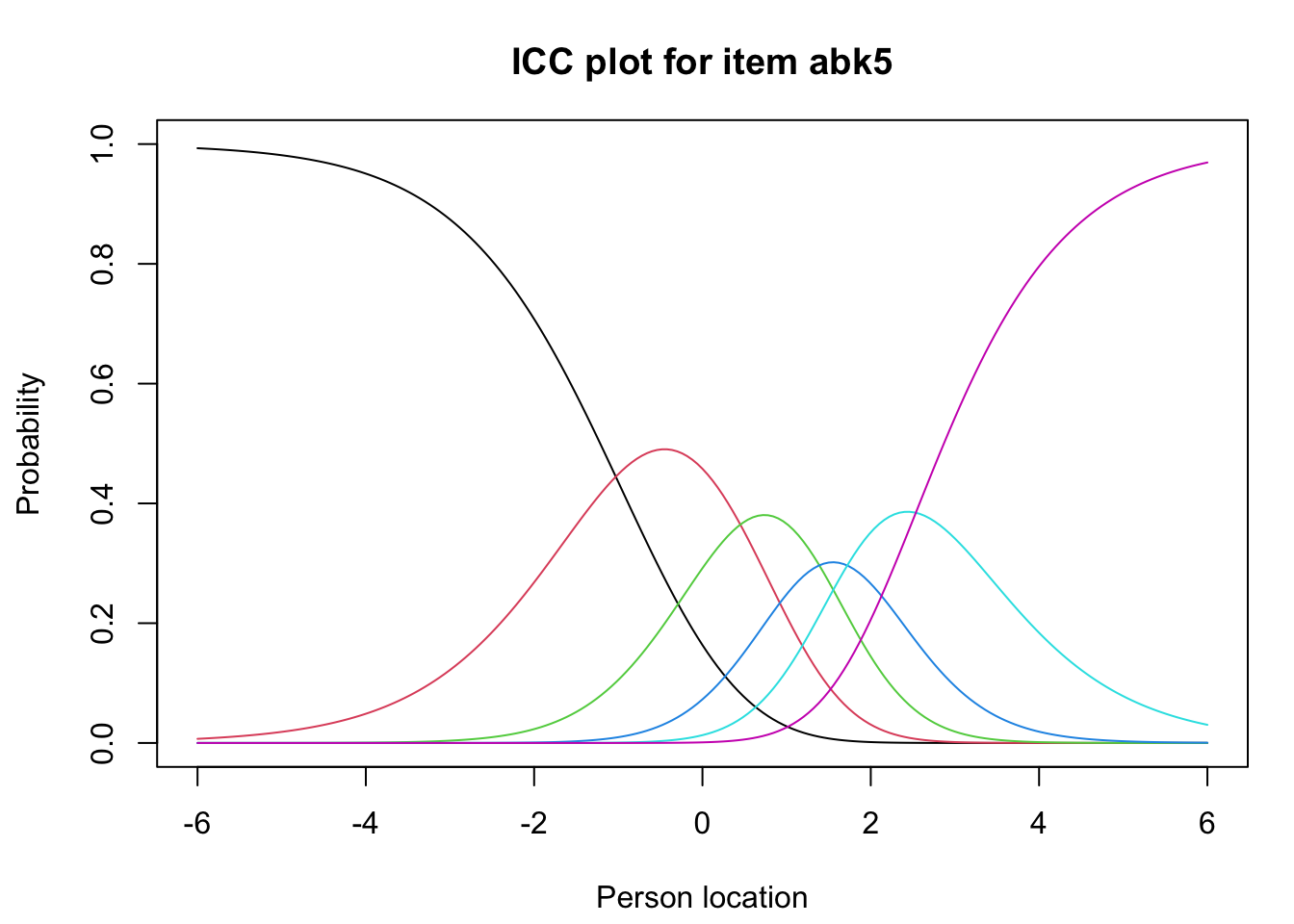
RIitemCats(df.omit.na, items ="all")
Code
# increase fig-height above as needed, if you have many itemsRItargeting(df.omit.na, xlim =c(-5,5))
Code
RIitemHierarchy(df.omit.na)
Den initiala analysen visar att items abk1, abk2 och abk4 visar något låg item fit sett till rekommenderade tröskelvärden. Det finns en mycket hög residualkorrelation mellan abk1 och abk2, samt problem med oordnade trösklar för samma två items. Vi tar bort abk1 eftersom den har lägre item fit, och slår samman svarskategorierna Ibland och Sällan för abk2.
Code
# create vector with eliminated itemsremoved_items <-c("abk1")# select all items except those removeddf2 <- df.omit.na %>%select(!any_of(removed_items)) %>%mutate(abk2 = car::recode(abk2,"2=1;3=2;4=3;5=4"))
3.3.1 Analysis of response categories
Code
RIitemCats(df2, items =c("abk2","abk3"))
Avstånden mellan tröskel 1 och 2 för abk3 är så små att vi slår samman de två lägsta svarskategorierna för abk3.
RIitemfitPCM2(df2, samplesize =250, nsamples =32, cpu =8)
OutfitMSQ
InfitMSQ
OutfitZSTD
InfitZSTD
abk2
0.732
0.727
-3.424
-3.658
abk3
1.005
0.983
0.108
0.015
abk5
0.669
0.673
-3.947
-4.356
abk6
0.765
0.772
-3.004
-2.93
Code
RIpcmPCA(na.omit(df2))
PCA of Rasch model residuals
Eigenvalues
1.54
1.31
1.14
0.01
Code
RIresidcorr(df2, cutoff =0.2)
abk2
abk3
abk5
abk6
abk2
abk3
-0.26
abk5
-0.1
-0.26
abk6
-0.16
-0.22
-0.4
Note:
Relative cut-off value (highlighted in red) is -0.035, which is 0.2 above the average correlation.
Code
RIloadLoc(df2)
Code
# increase fig-height above as needed, if you have many items#| label: fig-arbkrv-targRItargeting(df2)
Code
RIitemHierarchy(df2)
Code
RIpfit(df2)
3.5.1 Targeting
Code
# increase fig-height above as needed, if you have many itemsRItargeting(df2)
Figur 3.1: Targeting för området Arbetsbelastning och krav
Det kvarstår smärre problem med låg item fit, men överlag fungerar denna uppsättning items acceptabelt.
3.6 Reliability
Code
RItif(df2)
Figur 3.2: Reliabilitet för området Arbetsbelastning och krav
Vi kommer senare att utforska möjligheten att slå ihop items från ‘arbetsbelastning och krav’ och ‘återhämtning’ i den explorativa analysdelen, se Sektion 12.2.