library(foreign)library(readxl)library(RISEkbmRasch) # devtools::install_github("pgmj/RISEkbmRasch")library(grateful) # devtools::install_github("Pakillo/grateful")library(ggrepel)library(car)library(kableExtra)library(readxl)library(tidyverse)library(eRm)library(mirt)library(psych)library(ggplot2)library(psychotree)library(matrixStats)library(reshape)library(knitr)library(cowplot)library(formattable) library(glue)library(hexbin)library(skimr)### some commands exist in multiple packages, here we define preferred ones that are frequently usedselect <- dplyr::selectcount <- dplyr::countrecode <- car::recoderename <- dplyr::rename# file paths will need to have "../" added at the beginning to be able to render document# get itemlabelsitemlabels <-read_excel("../data/Itemlabels.xlsx") %>%filter(str_detect(itemnr, pattern ="kb")) %>%select(!Dimension)spssDatafil <-"../data/2023-04-26 Prevent OSA-enkat.sav"# read SurveyMonkey datadf <-read.spss(spssDatafil, to.data.frame =TRUE) %>%select(starts_with("q0012"),q0001,q0002,q0003,q0004) %>%rename(Kön = q0002, Ålder = q0001,Bransch = q0003,Hemarbete = q0004)# SPSS format provides itemlabels too, we can save them in a dataframespssLabels <- df %>%attr('variable.labels') %>%as.data.frame()dif.kön <- df$Köndif.ålder <- df$Ålderdif.bransch <- df$Branschdif.hemarbete <- df$Hemarbetedf <- df %>%select(starts_with("q0012"))names(df) <- itemlabels$itemnr
9.1 Items
Code
itemlabels %>%kbl_rise(width =50)
itemnr
item
kb1
Blivit utsatt för att någon undanhåller information som har påverkat din prestation.
kb2
Blivit utsatt för skvaller eller rykten spridda om dig.
kb3
Blivit ignorerad eller exkluderad.
kb4
Fått kränkande eller stötande kommentarer om dig som person, dina attityder eller ditt privatliv.
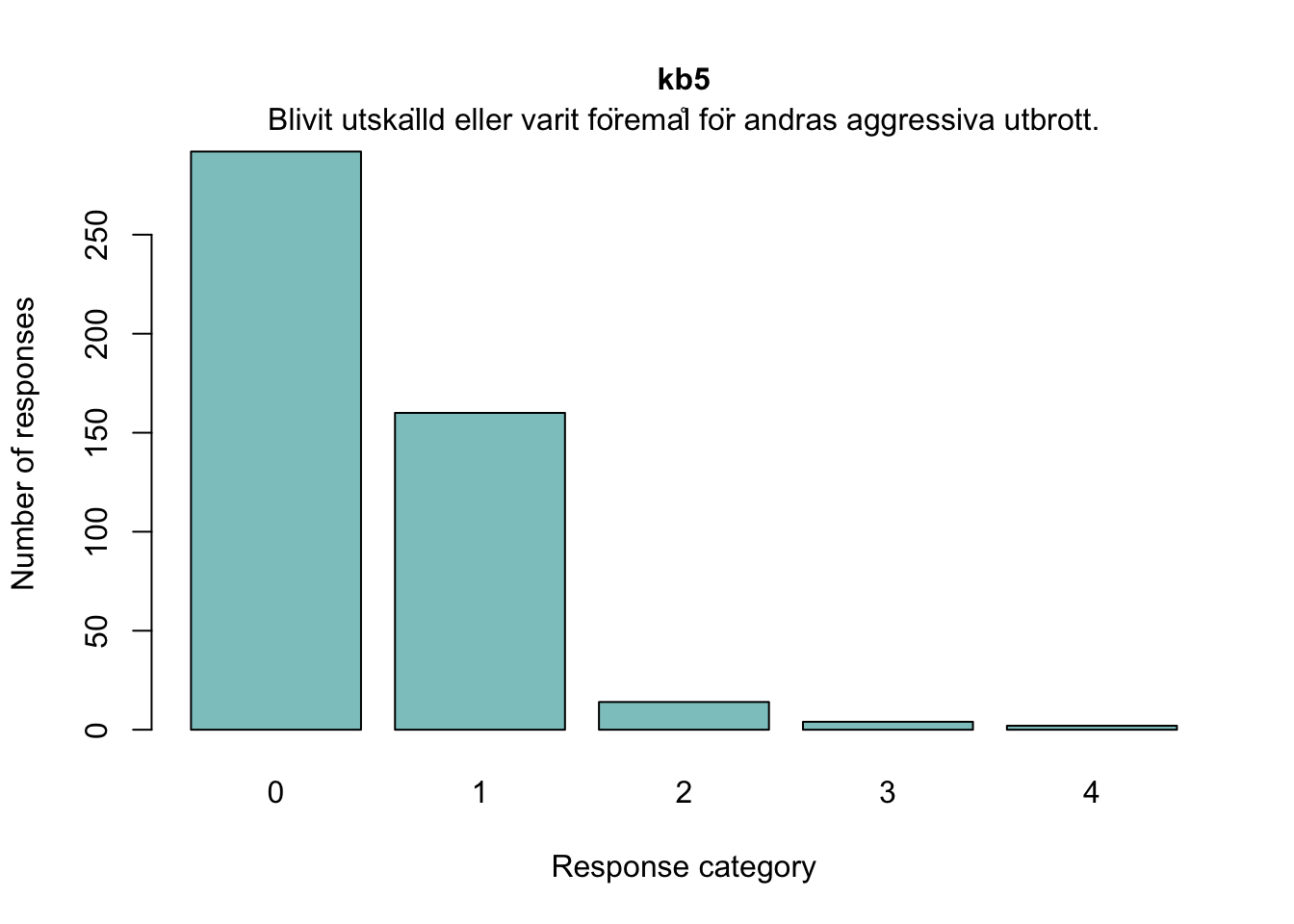
kb5
Blivit utskälld eller varit föremål för andras aggressiva utbrott.
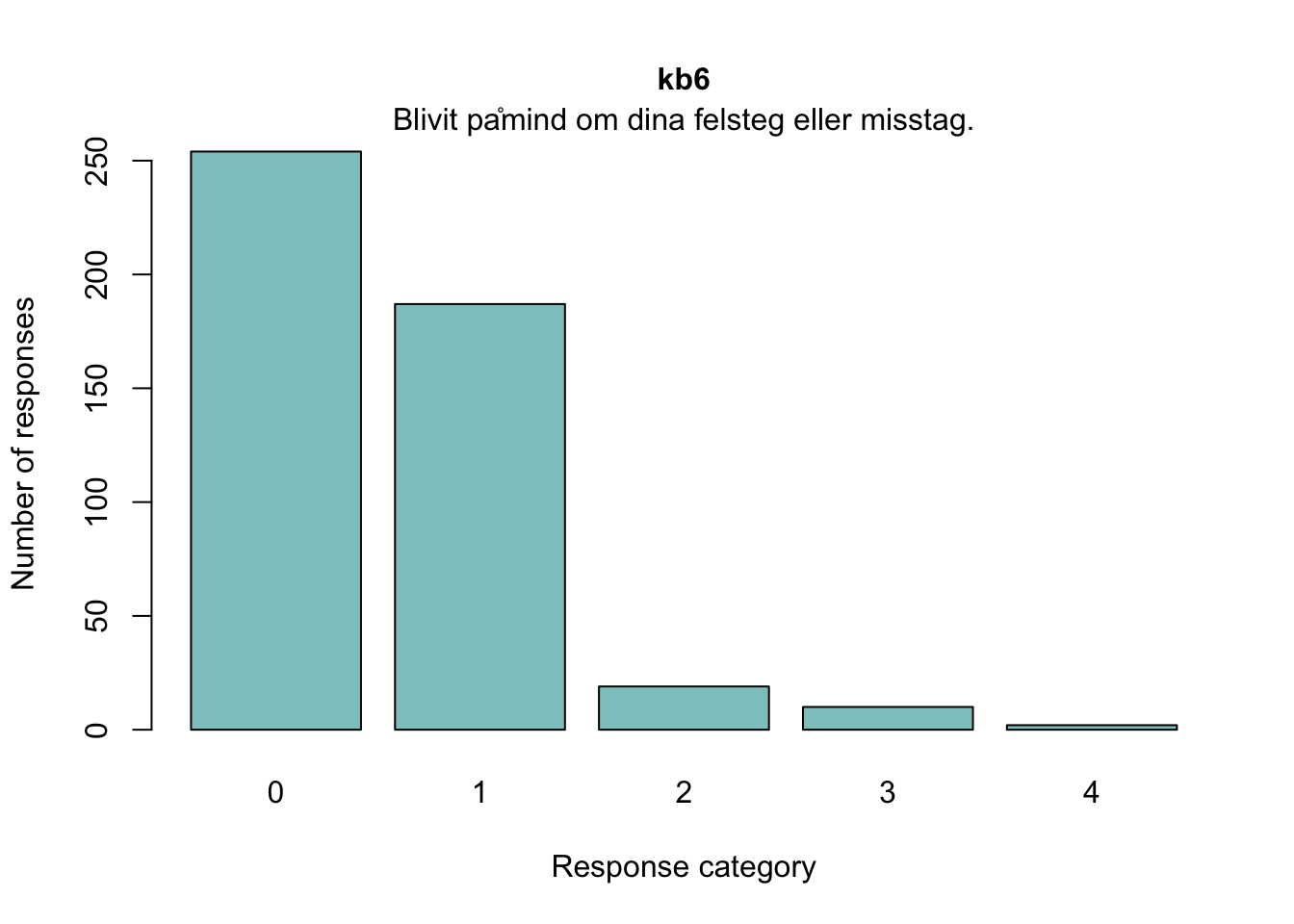
kb6
Blivit påmind om dina felsteg eller misstag.
kb7
Blivit utsatt för ett otrevligt bemötande när du närmar dig andra.
RIdemographics(dif.ålder,"Ålder") # kanske även fixa en figur?
Ålder
n
Percent
18-29
22
3.8
30-39
103
17.8
40-49
175
30.2
50-59
215
37.1
60+
64
11.1
Code
RIdemographics(dif.bransch,"Bransch")
Bransch
n
Percent
Kontorsarbete (oavsett bransch)
284
49.1
Industri
26
4.5
Hotell, restaurang, service
8
1.4
Handel
16
2.8
Skola, utbildning
67
11.6
Vård, omsorg
99
17.1
Byggverksamhet
7
1.2
Annat
71
12.3
Code
RIdemographics(dif.hemarbete,"Antal dagar med arbete hemifrån")
Antal dagar med arbete hemifrån
n
Percent
En dag
136
23.5
Två dagar
105
18.1
Tre dagar
35
6.0
Fyra dagar
10
1.7
Fem dagar
2
0.3
Jag arbetar aldrig eller sällan hemifrån
291
50.3
9.2.1 Svarsbortfall items
Vi filtrerar bort respondenter som har färre än två svar på frågorna i delskalan.
Code
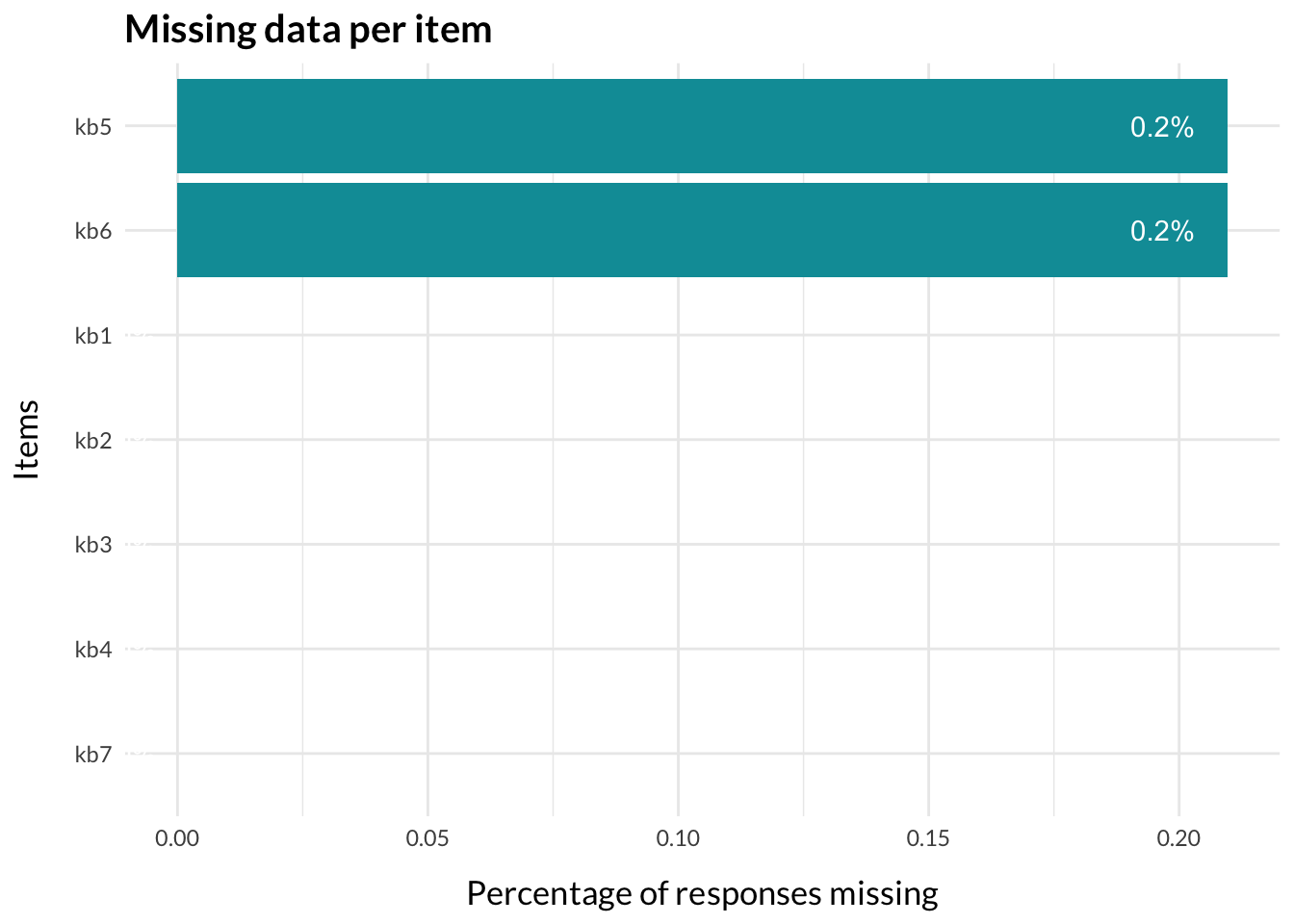
# If you want to include participants with missing data, input the minimum number of items responses that a participant should have to be included in the analysis:min.responses <-2scale.items <- itemlabels$itemnr# Select the variables we will work with, and filter out respondents with a lot of missing datadf.omit.na <- df %>%filter(length(scale.items)-rowSums(is.na(.[scale.items])) >= min.responses)RImissing(df.omit.na,"kb")
Vi har extremt få saknade svar, och tar därför bort respondenterna som inte har kompletta svar.
Det är tveksamt om området kränkande beteenden är lämpat för att utgöra ett index. Rimligen är det förhållandevis få personer som blivit utsatta för kränkningarna som ingår i skalan, vilket påverkar de psykometriska egenskaperna. Analysen utförs dock ändå i explorativt syfte.
Code
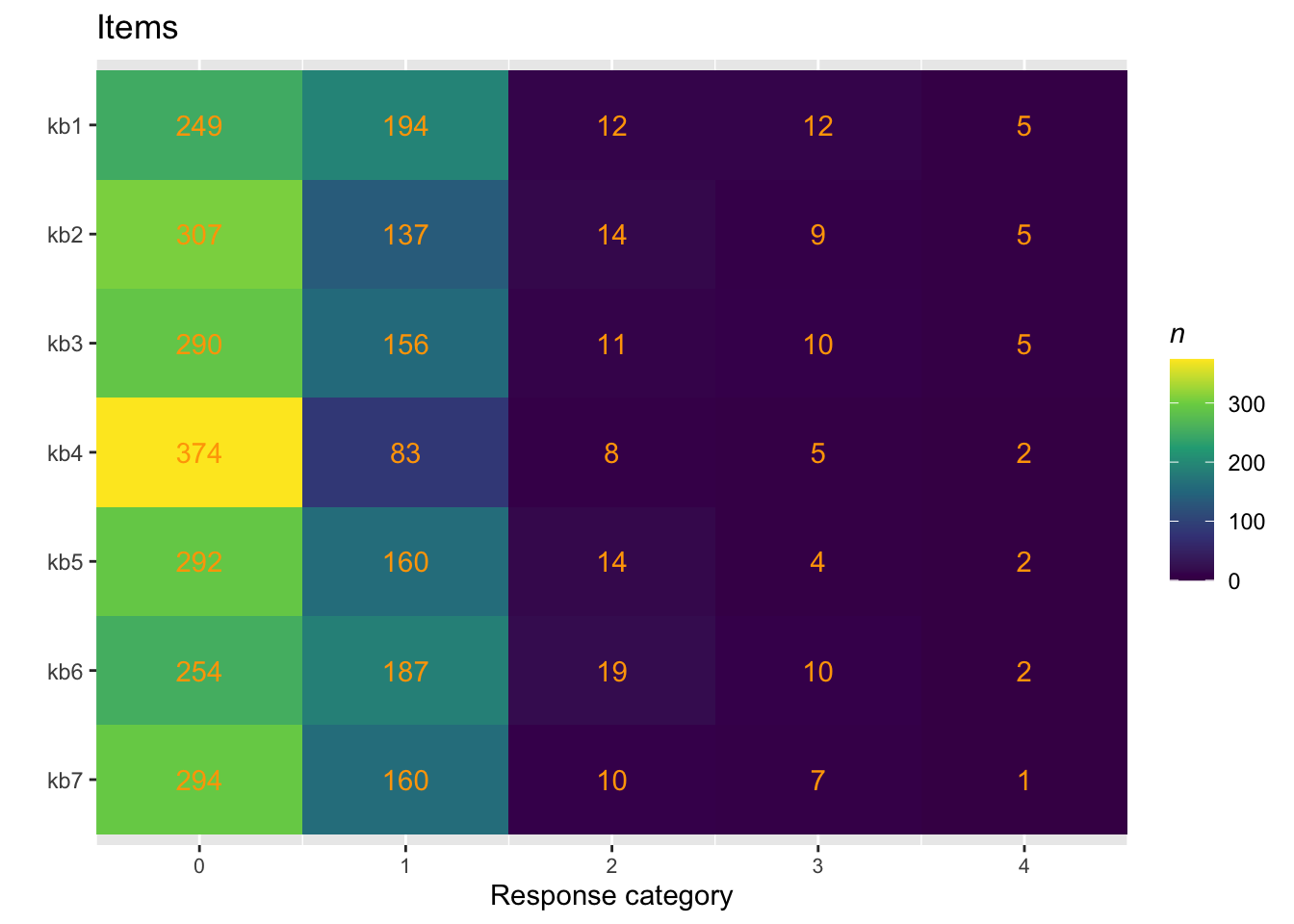
# koda om svarskategorier till siffrordf.omit.na <- df.omit.na %>%mutate(across(everything(), ~ car::recode(.x,"'Aldrig'=0; 'Det har hänt' =1; 'Varje månad'=2; 'Varje vecka'=3; 'Dagligen'=4",as.factor =FALSE)))
Vi har väldigt få svar i högsta kategorierna, vilket kan bero på underlaget, och/eller att förekomsten är låg. Vi slår ihop de högsta två svarsalternativen (dagligen och varje vecka) för att kunna utföra analysen.
Code
#Temporärt slå ihop svarskategorier så att analyserna funkardf.omit.na <- df.omit.na %>%mutate(across(everything(), ~recode(.x,"4=3"))) # Slå ihop svarskategorier
9.3 Rasch-analys 1
itemnr
item
kb1
Blivit utsatt för att någon undanhåller information som har påverkat din prestation.
kb2
Blivit utsatt för skvaller eller rykten spridda om dig.
kb3
Blivit ignorerad eller exkluderad.
kb4
Fått kränkande eller stötande kommentarer om dig som person, dina attityder eller ditt privatliv.
kb5
Blivit utskälld eller varit föremål för andras aggressiva utbrott.
kb6
Blivit påmind om dina felsteg eller misstag.
kb7
Blivit utsatt för ett otrevligt bemötande när du närmar dig andra.
Relative cut-off value (highlighted in red) is 0.035, which is 0.2 above the average correlation.
Code
RIloadLoc(df2)
Code
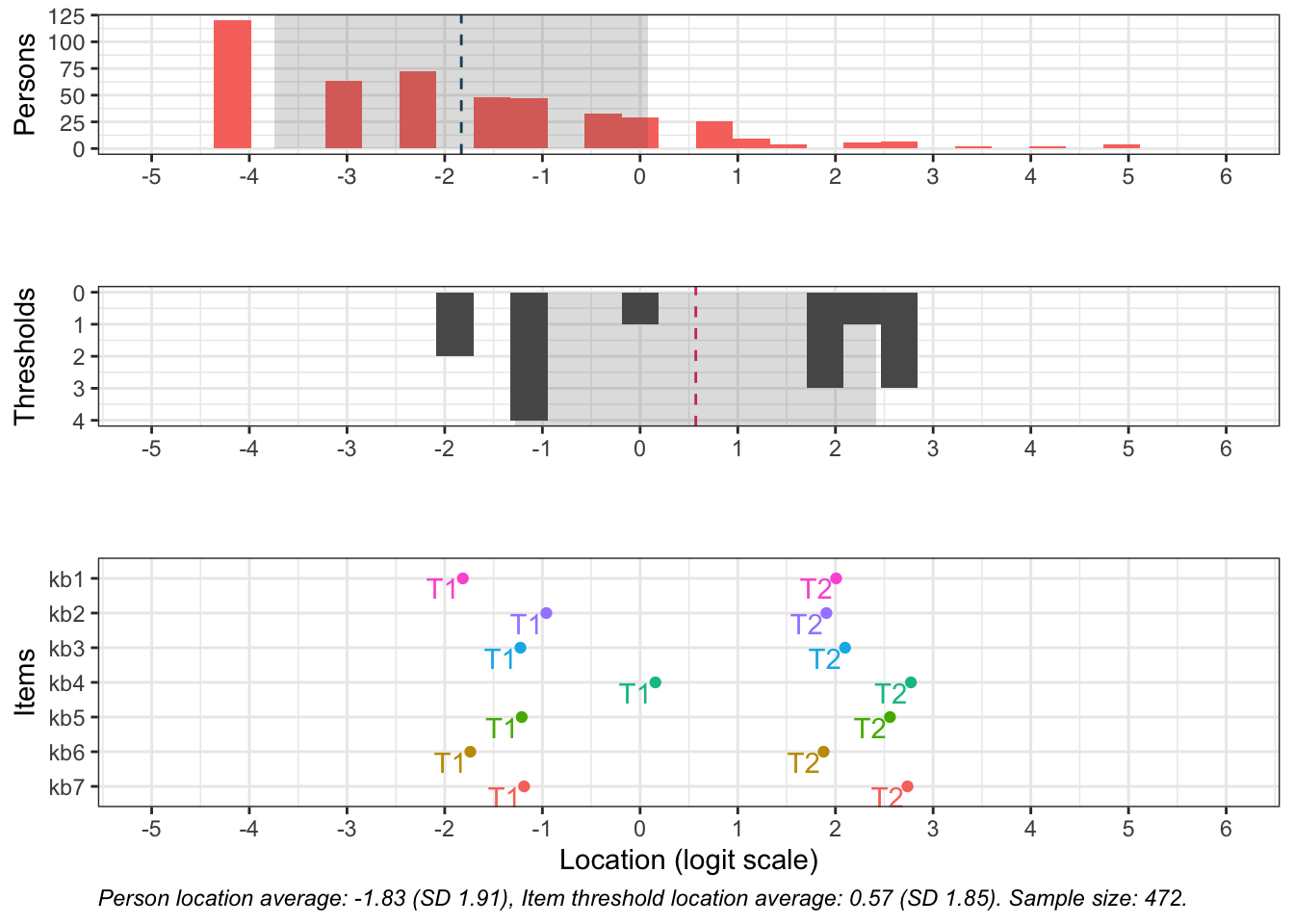
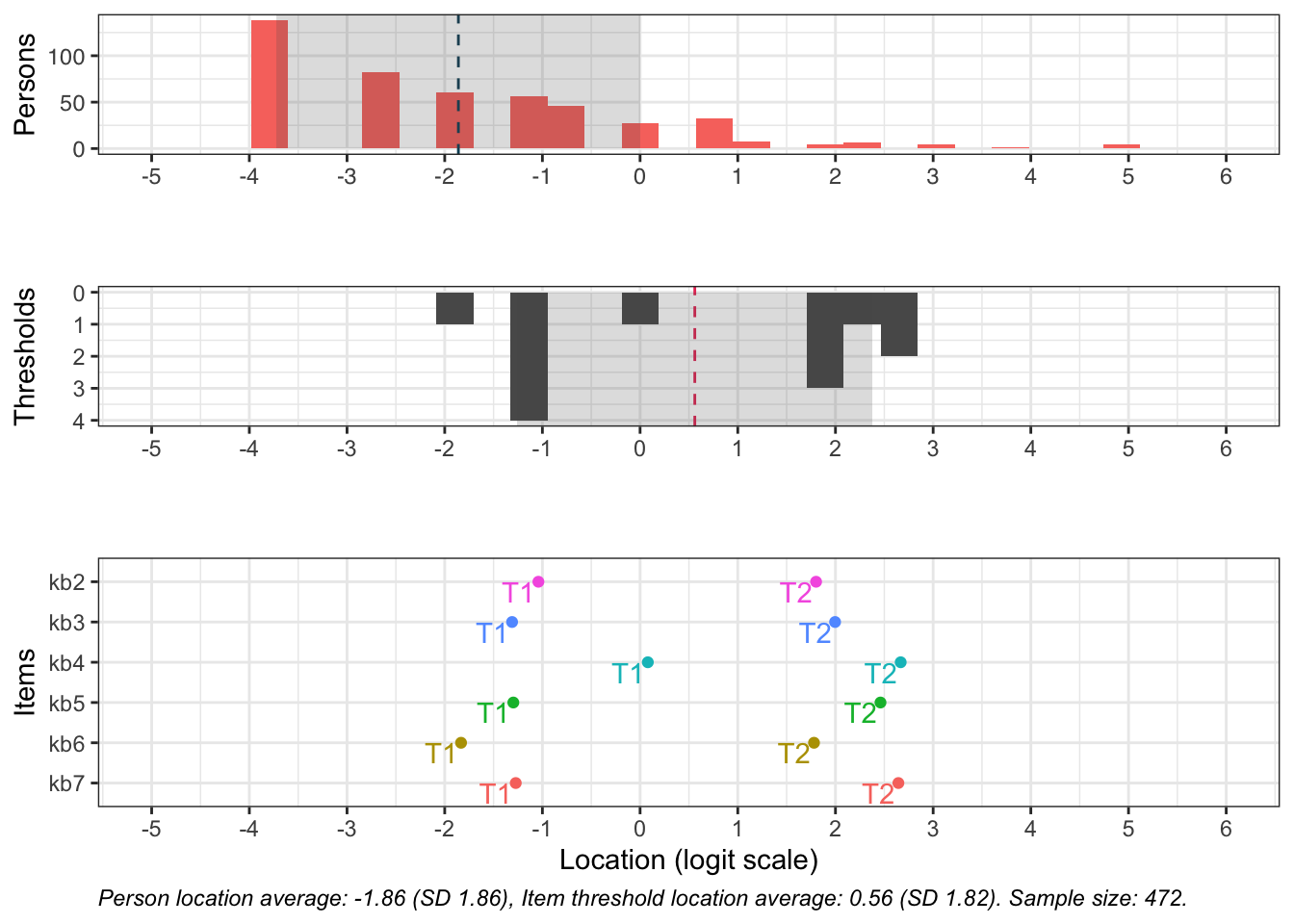
# increase fig-height above as needed, if you have many itemsRItargeting(df2)
Code
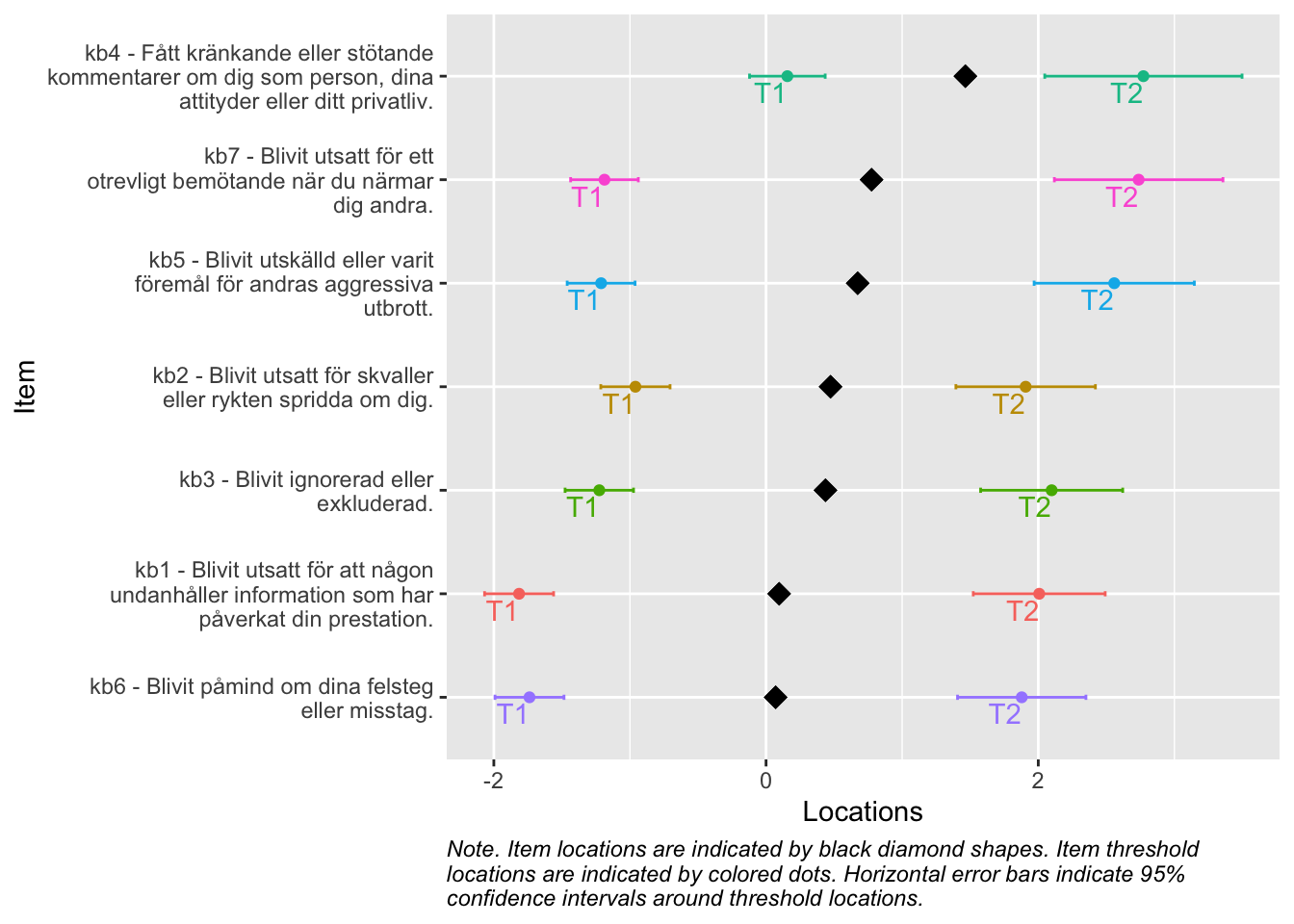
RIitemHierarchy(df2)
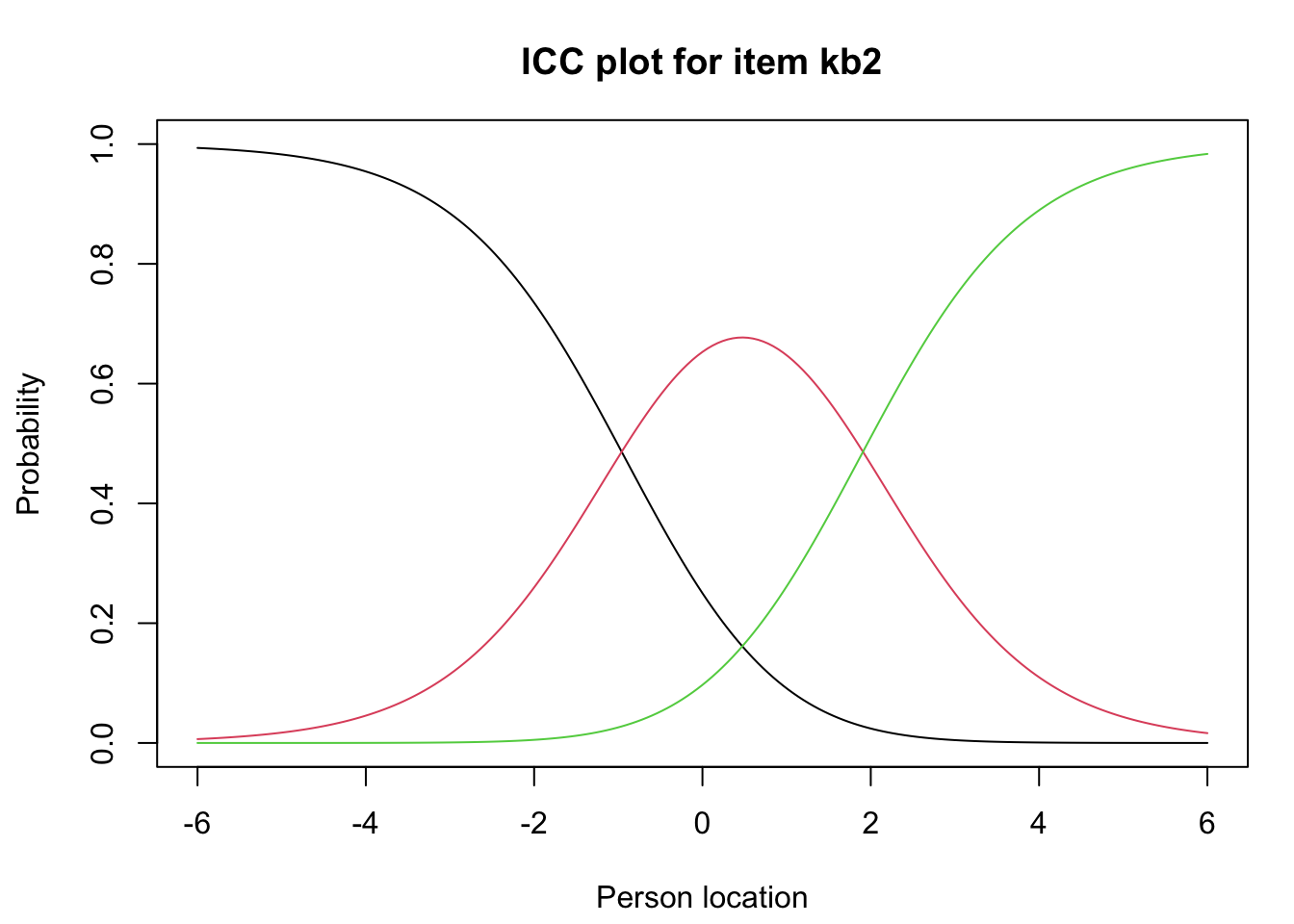
Item 4 har fortsatt något låg outfit medan infit (som är viktigare) är inom rimliga nivåer.
9.6 DIF-analysis
En DIF-analys bör inte inkludera svarskategorier med för få svar. Därför har svarskategorier med färre än 50 svar antingen exkluderas eller slagits ihop med andra svarskategorier (se avsnittet om bakgrundsdata för exakt antal svar per ordinarie kategori). DIF-variablerna omkodades till att innehålla följande kategorier:
Kön: man, kvinna
Ålder: 30-39, 40-49, 50-59, 60+
Bransch: kontorsarbete, ej kontorsarbete
Hemarbete: aldrig eller sällan, en dag, minst två dagar
Koden nedan specificerar exakt hur omkodningen gick till.
Code
# Omkodning för köndif.kön <-recode(dif.kön,"'Annat'=NA;'Vill ej uppge'=NA")# Omkodning för ålderdif.ålder <-recode(dif.ålder,"'18-29'=NA")# Omkodning för branschdif.bransch <-recode(dif.bransch,"'Industri'='Ej kontorsarbete';'Hotell, restaurang, service'='Ej kontorsarbete';'Handel'='Ej kontorsarbete';'Skola, utbildning'='Ej kontorsarbete';'Vård, omsorg'='Ej kontorsarbete';'Byggverksamhet'='Ej kontorsarbete';'Annat'='Ej kontorsarbete'")#Omkodning för hemarbetedif.hemarbete <-recode(dif.hemarbete,"'Fem dagar'='Minst två dagar';'Fyra dagar'='Minst två dagar';'Tre dagar'='Minst två dagar';'Två dagar'='Minst två dagar'")