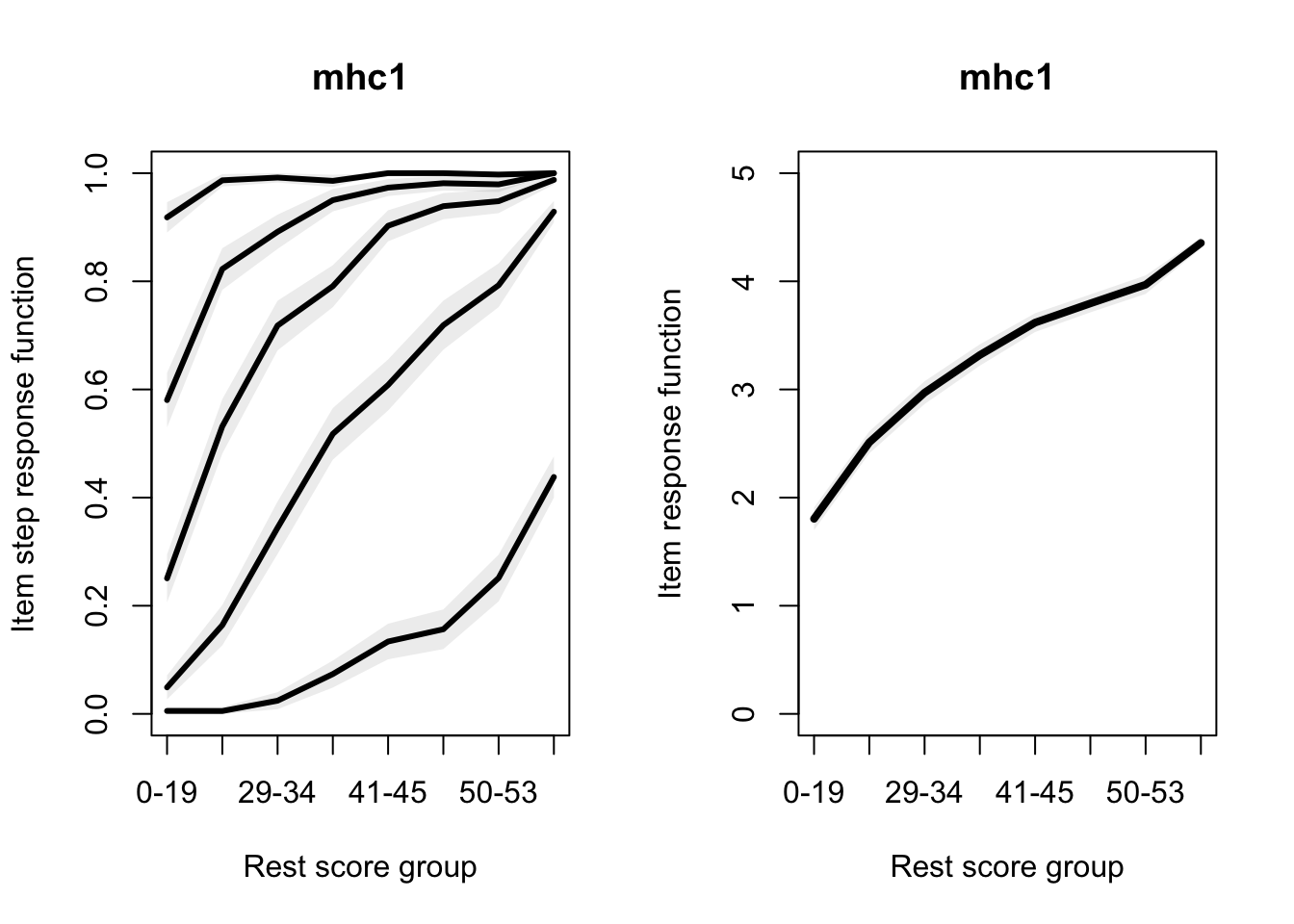
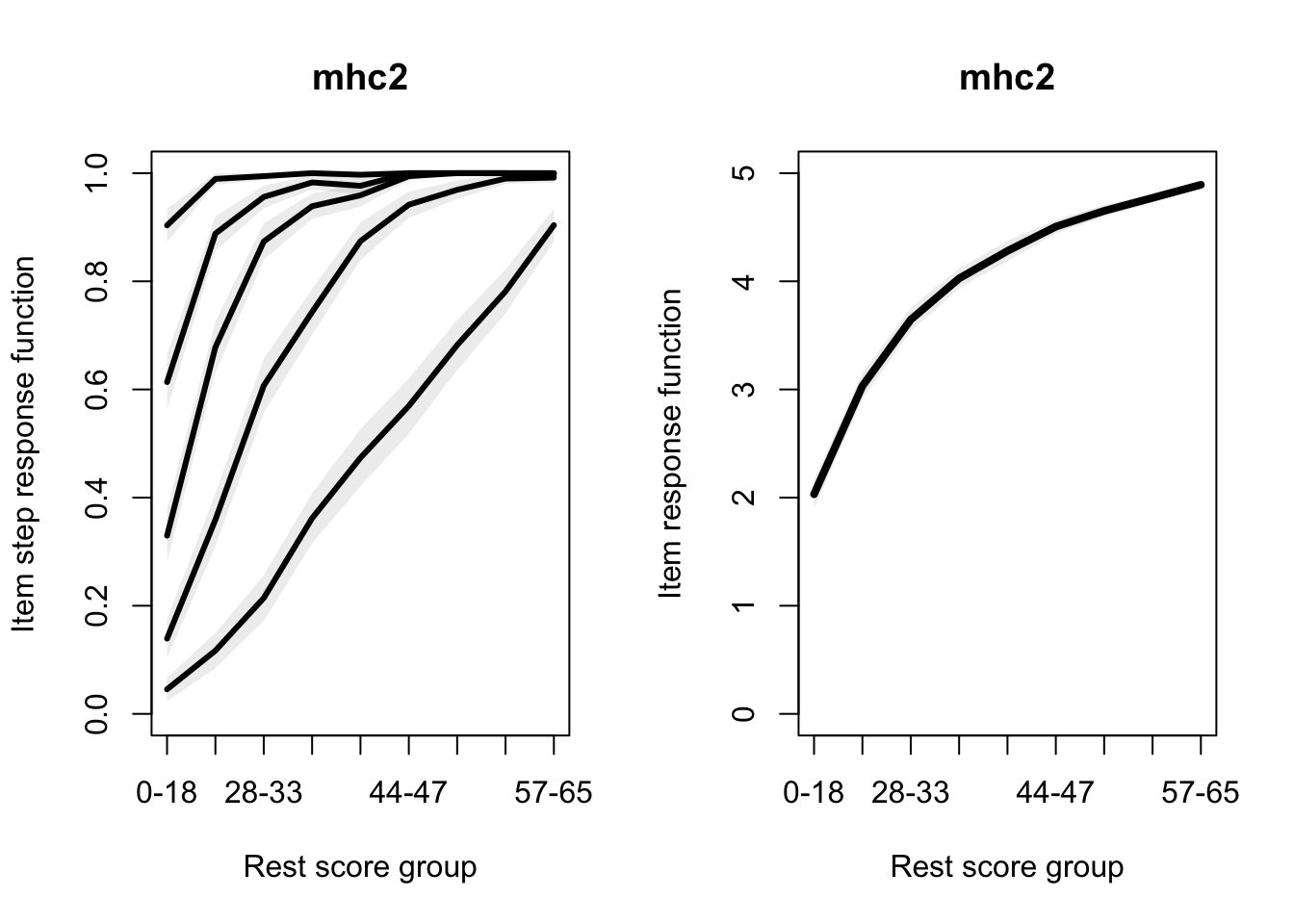
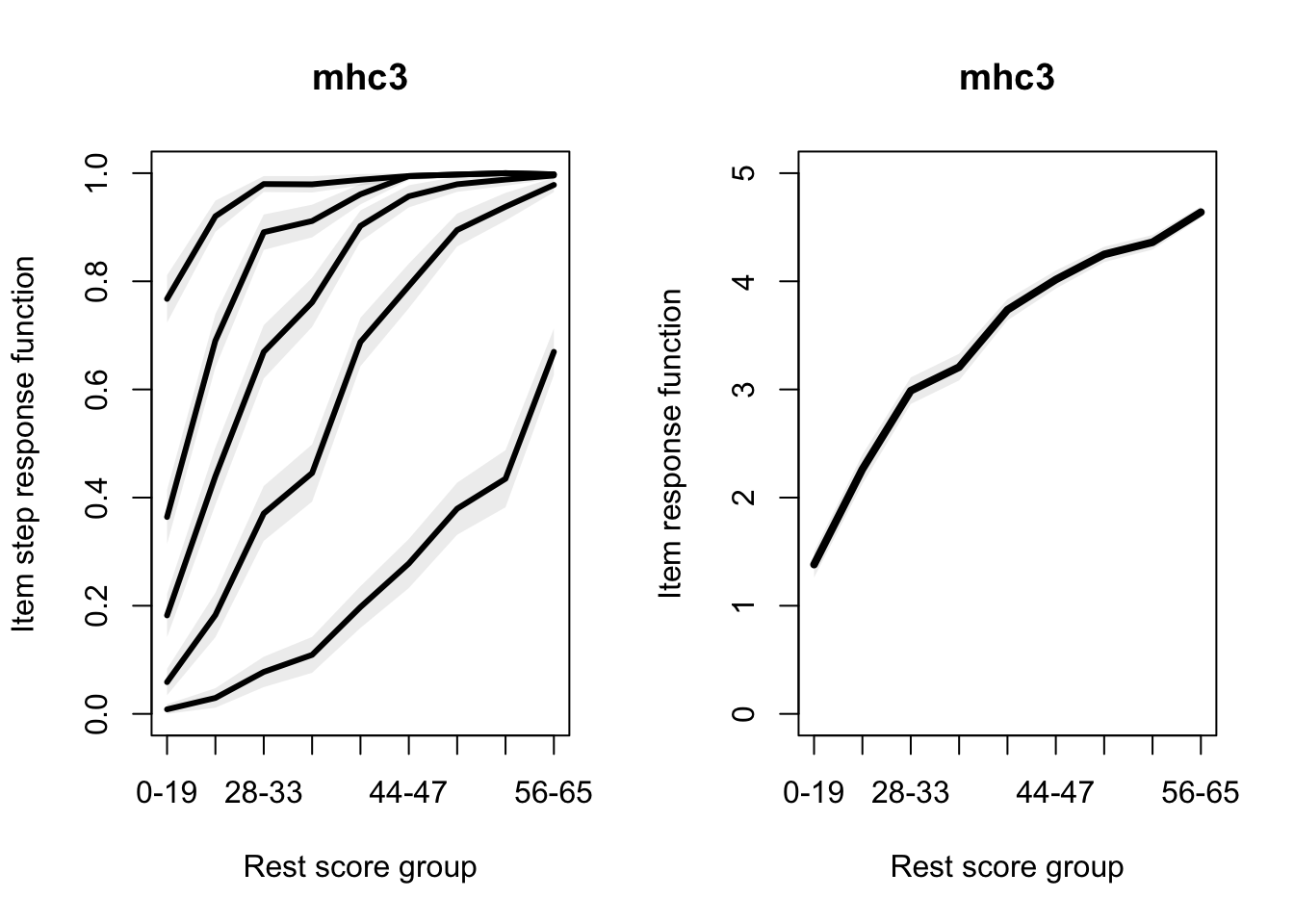
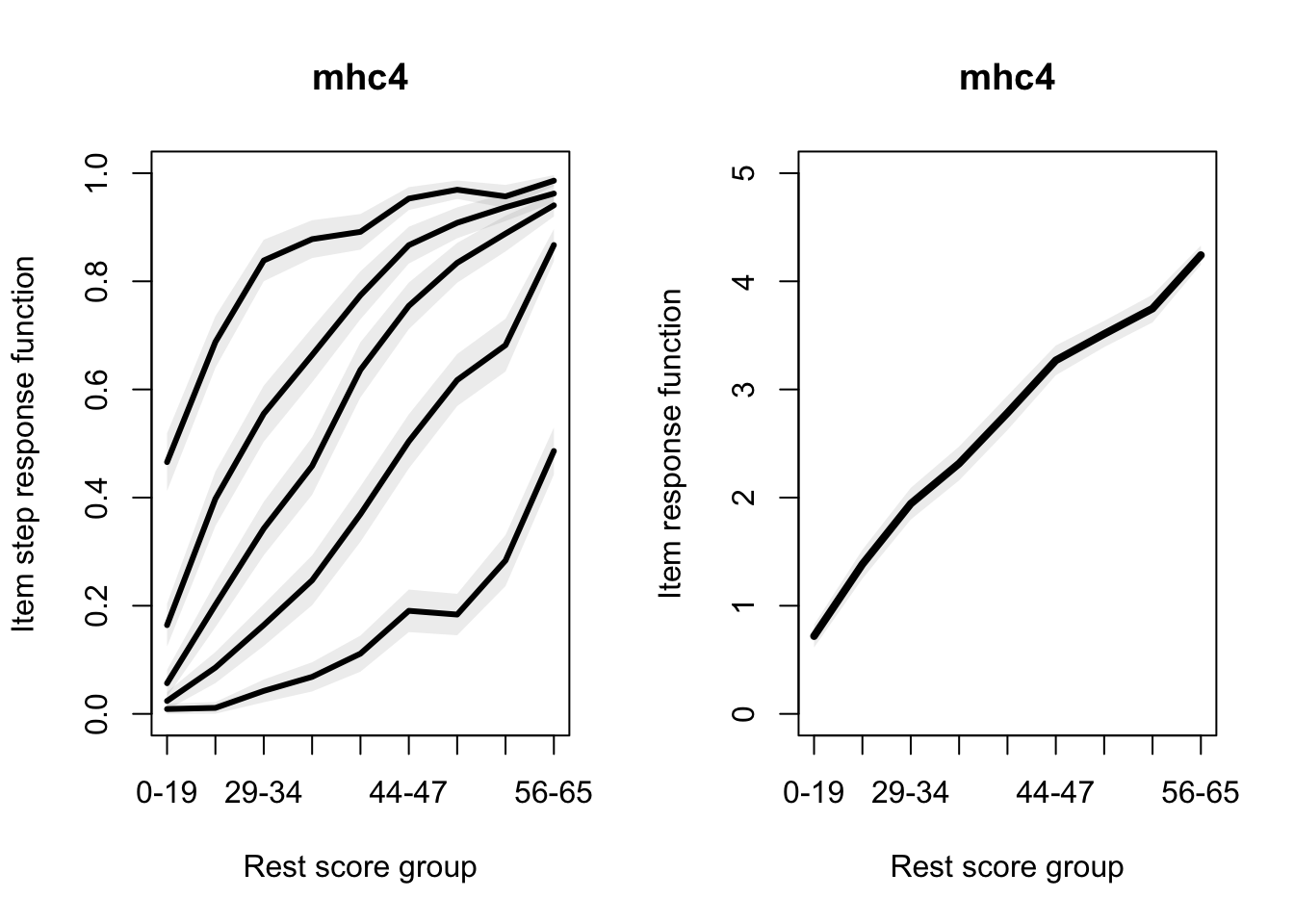
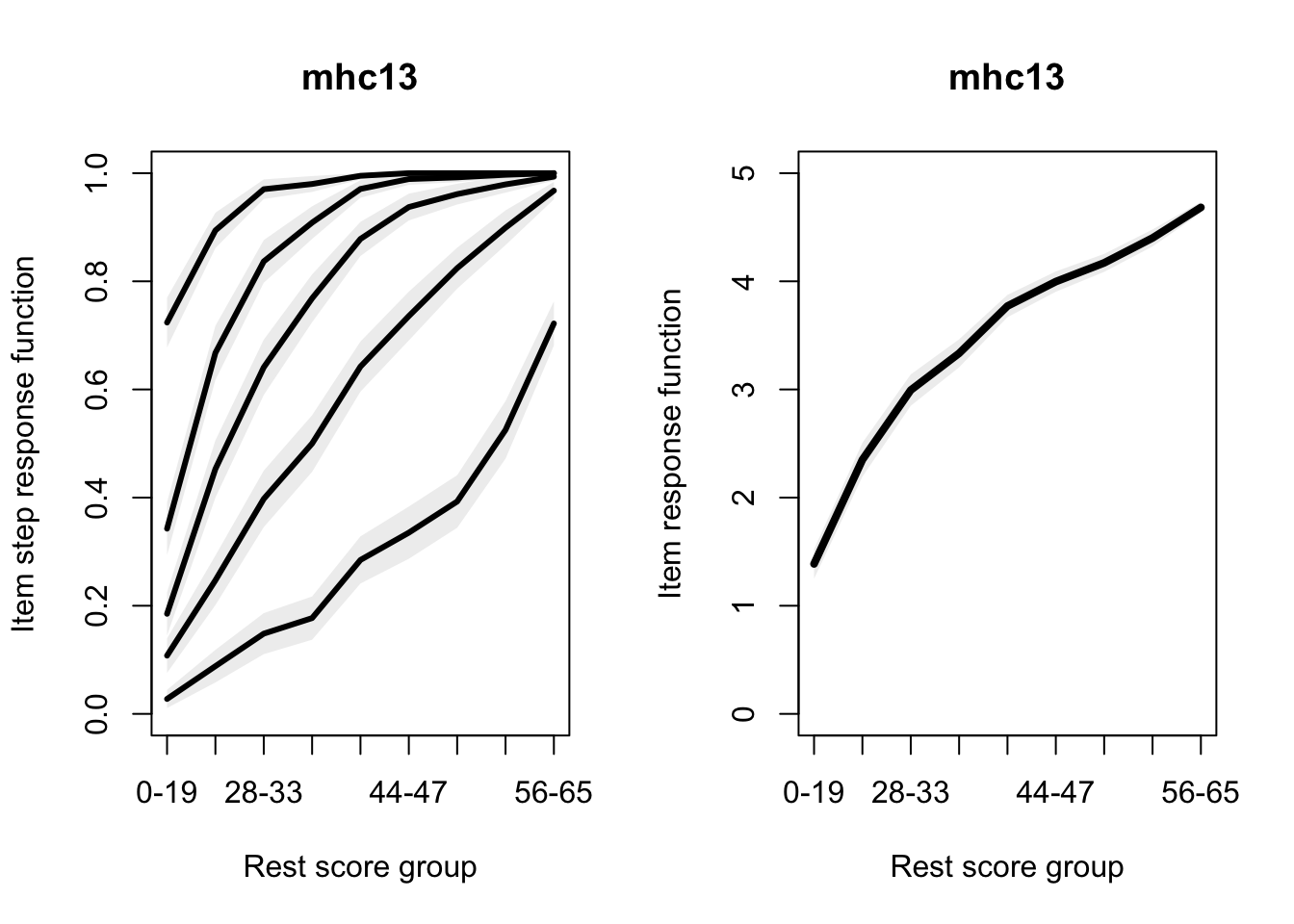
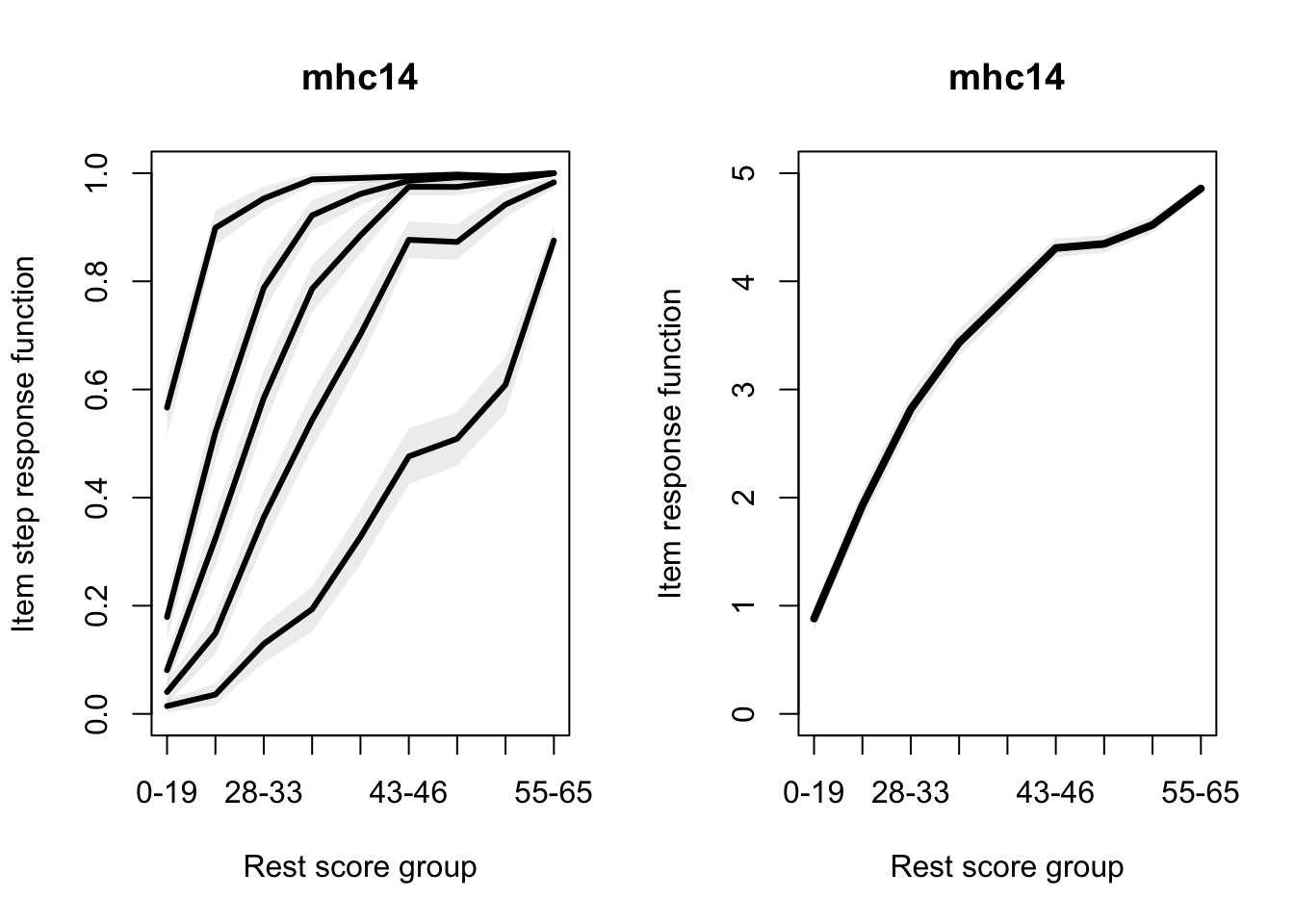
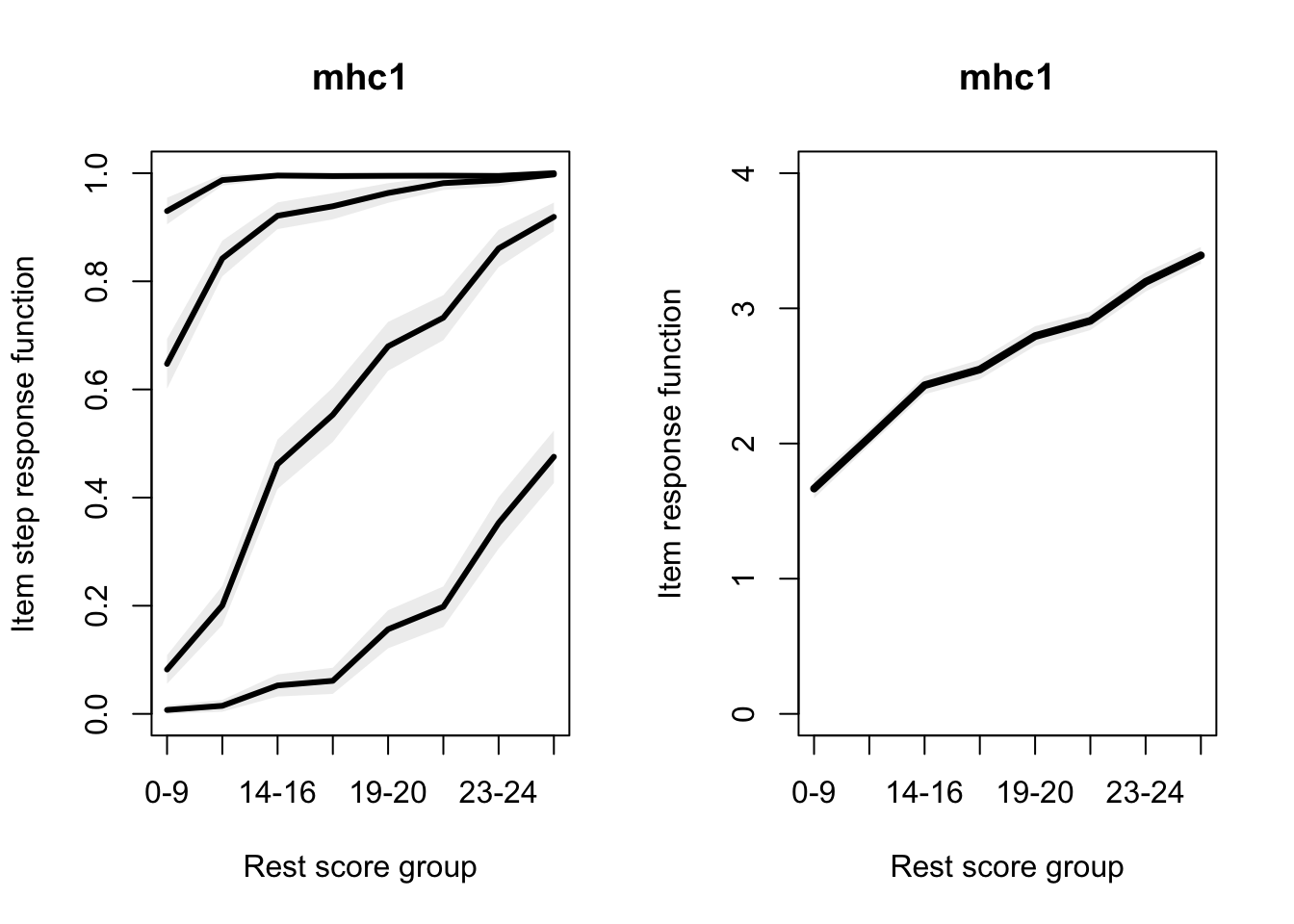
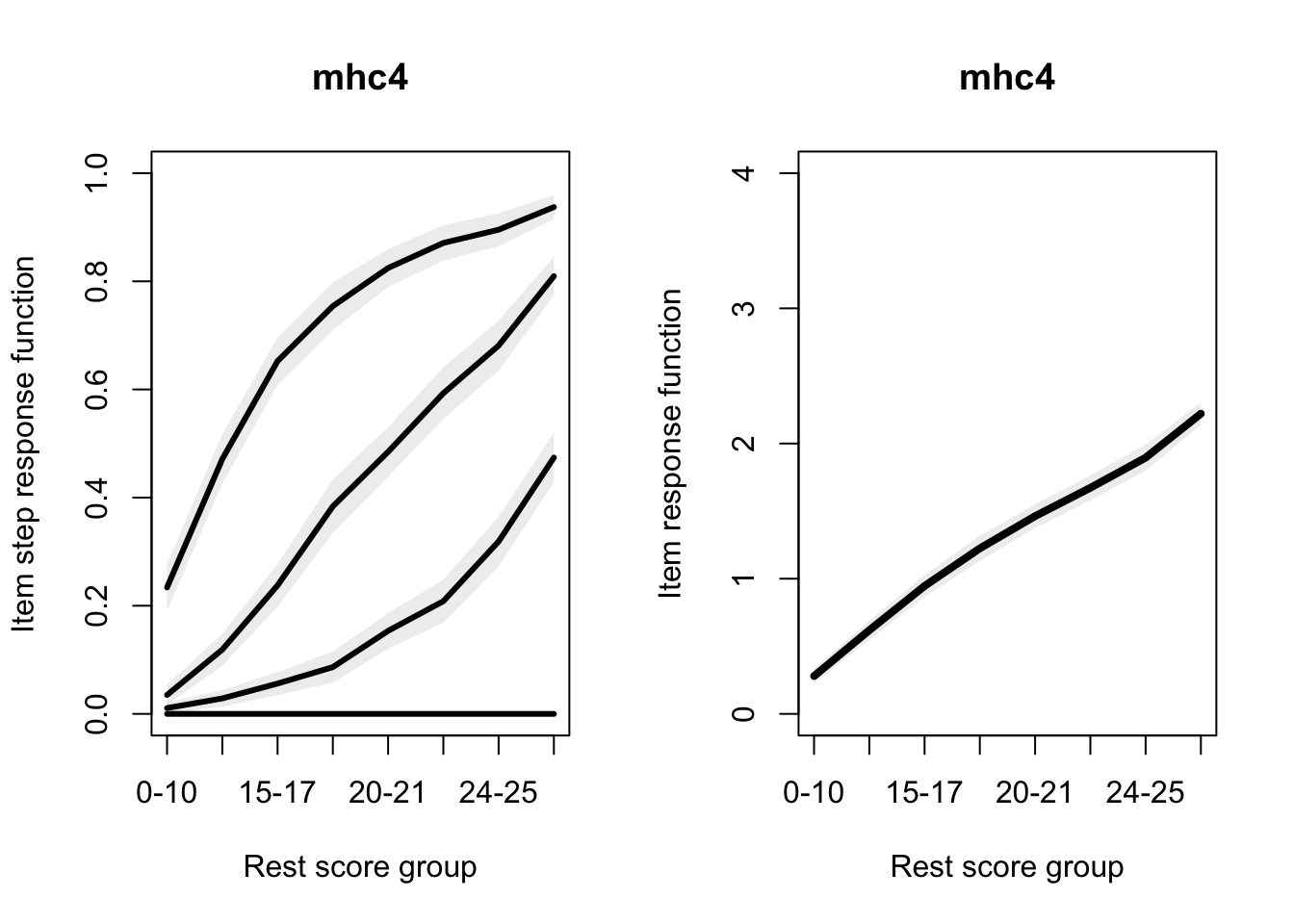
Allaire, JJ, Yihui Xie, Christophe Dervieux, Jonathan McPherson, Javier Luraschi, Kevin Ushey, Aron Atkins, et al. 2023.
rmarkdown: Dynamic Documents for r.
https://github.com/rstudio/rmarkdown.
Bengtsson, Henrik. 2023.
matrixStats: Functions That Apply to Rows and Columns of Matrices (and to Vectors).
https://CRAN.R-project.org/package=matrixStats.
Chalmers, R. Philip. 2012.
“mirt: A Multidimensional Item Response Theory Package for the R Environment.” Journal of Statistical Software 48 (6): 1–29.
https://doi.org/10.18637/jss.v048.i06.
Debelak, Rudolf, and Ingrid Koller. 2019.
“Testing the Local Independence Assumption of the Rasch Model with Q3-Based Nonparametric Model Tests.” Applied Psychological Measurement 44.
https://doi.org/10.1177/0146621619835501.
Fox, John, and Sanford Weisberg. 2019.
An R Companion to Applied Regression. Third. Thousand Oaks
CA: Sage.
https://socialsciences.mcmaster.ca/jfox/Books/Companion/.
Hatzinger, Reinhold, and Thomas Rusch. 2009. “IRT Models with Relaxed Assumptions in eRm: A Manual-Like Instruction.” Psychology Science Quarterly 51.
Hester, Jim, and Jennifer Bryan. 2024.
glue: Interpreted String Literals.
https://CRAN.R-project.org/package=glue.
Johansson, Magnus. 2024.
RISEkbmRasch: Psychometric Analysis in r with Rasch Measurement Theory.
https://github.com/pgmj/RISEkbmRasch.
Koller, Ingrid, Marco Maier, and Reinhold Hatzinger. 2015.
“An Empirical Power Analysis of Quasi-Exact Tests for the Rasch Model: Measurement Invariance in Small Samples.” Methodology 11.
https://doi.org/10.1027/1614-2241/a000090.
Komboz, Basil, Achim Zeileis, and Carolin Strobl. 2018.
“Tree-Based Global Model Tests for Polytomous Rasch Models.” Educational and Psychological Measurement 78 (1): 128–66.
https://doi.org/10.1177/0013164416664394.
Lishinski, Alex. 2021.
lavaanPlot: Path Diagrams for “Lavaan” Models via “DiagrammeR”.
https://CRAN.R-project.org/package=lavaanPlot.
Mair, Patrick, and Reinhold Hatzinger. 2007a.
“CML Based Estimation of Extended Rasch Models with the eRm Package in r.” Psychology Science 49.
https://doi.org/10.18637/jss.v020.i09.
———. 2007b.
“Extended Rasch Modeling: The eRm Package for the Application of IRT Models in r.” Journal of Statistical Software 20.
https://doi.org/10.18637/jss.v020.i09.
Pedersen, Thomas Lin. 2024.
patchwork: The Composer of Plots.
https://CRAN.R-project.org/package=patchwork.
R Core Team. 2023.
R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing.
https://www.R-project.org/.
Rosseel, Yves. 2012.
“lavaan: An R Package for Structural Equation Modeling.” Journal of Statistical Software 48 (2): 1–36.
https://doi.org/10.18637/jss.v048.i02.
Rusch, Thomas, Marco Maier, and Reinhold Hatzinger. 2013.
“Linear Logistic Models with Relaxed Assumptions in r.” In
Algorithms from and for Nature and Life, edited by Berthold Lausen, Dirk van den Poel, and Alfred Ultsch. Studies in Classification, Data Analysis, and Knowledge Organization. New York: Springer.
https://doi.org/10.1007/978-3-319-00035-0_34.
Sijtsma, Klaas, and L. Andries van der Ark. 2017.
“A tutorial on how to do a Mokken scale analysis on your test and questionnaire data.” The British Journal of Mathematical and Statistical Psychology 70 (1): 137–58.
https://doi.org/10.1111/bmsp.12078.
Slowikowski, Kamil. 2024.
ggrepel: Automatically Position Non-Overlapping Text Labels with “ggplot2”.
https://CRAN.R-project.org/package=ggrepel.
Stochl, Jan, Peter B. Jones, and Tim J. Croudace. 2012.
“Mokken Scale Analysis of Mental Health and Well-Being Questionnaire Item Responses: A Non-Parametric IRT Method in Empirical Research for Applied Health Researchers.” BMC Medical Research Methodology 12 (1): 74.
https://doi.org/10.1186/1471-2288-12-74.
Strobl, Carolin, Julia Kopf, and Achim Zeileis. 2015.
“Rasch Trees: A New Method for Detecting Differential Item Functioning in the Rasch Model.” Psychometrika 80 (2): 289–316.
https://doi.org/10.1007/s11336-013-9388-3.
Strobl, Carolin, Florian Wickelmaier, and Achim Zeileis. 2011.
“Accounting for Individual Differences in Bradley-Terry Models by Means of Recursive Partitioning.” Journal of Educational and Behavioral Statistics 36 (2): 135–53.
https://doi.org/10.3102/1076998609359791.
Trepte, Sabine, and Markus Verbeet, eds. 2010. Allgemeinbildung in Deutschland – Erkenntnisse Aus Dem SPIEGEL Studentenpisa-Test. Wiesbaden: VS Verlag.
Van der Ark, L. Andries. 2007.
“Mokken Scale Analysis in R.” Journal of Statistical Software 20 (11): 1–19.
https://doi.org/10.18637/jss.v020.i11.
———. 2012.
“New Developments in Mokken Scale Analysis in R.” Journal of Statistical Software 48 (5): 1–27.
https://doi.org/10.18637/jss.v048.i05.
Wickelmaier, Florian, and Achim Zeileis. 2018.
“Using Recursive Partitioning to Account for Parameter Heterogeneity in Multinomial Processing Tree Models.” Behavior Research Methods 50 (3): 1217–33.
https://doi.org/10.3758/s13428-017-0937-z.
Wickham, Hadley. 2007.
“Reshaping Data with the Reshape Package.” Journal of Statistical Software 21 (12).
https://www.jstatsoft.org/v21/i12/.
Wickham, Hadley, Mara Averick, Jennifer Bryan, Winston Chang, Lucy D’Agostino McGowan, Romain François, Garrett Grolemund, et al. 2019.
“Welcome to the tidyverse.” Journal of Open Source Software 4 (43): 1686.
https://doi.org/10.21105/joss.01686.
Wilke, Claus O. 2023.
cowplot: Streamlined Plot Theme and Plot Annotations for “ggplot2”.
https://CRAN.R-project.org/package=cowplot.
William Revelle. 2023.
psych: Procedures for Psychological, Psychometric, and Personality Research. Evanston, Illinois: Northwestern University.
https://CRAN.R-project.org/package=psych.
Xie, Yihui. 2014. “knitr: A Comprehensive Tool for Reproducible Research in R.” In Implementing Reproducible Computational Research, edited by Victoria Stodden, Friedrich Leisch, and Roger D. Peng. Chapman; Hall/CRC.
———. 2015.
Dynamic Documents with R and Knitr. 2nd ed. Boca Raton, Florida: Chapman; Hall/CRC.
https://yihui.org/knitr/.
———. 2023.
knitr: A General-Purpose Package for Dynamic Report Generation in r.
https://yihui.org/knitr/.
Xie, Yihui, J. J. Allaire, and Garrett Grolemund. 2018.
R Markdown: The Definitive Guide. Boca Raton, Florida: Chapman; Hall/CRC.
https://bookdown.org/yihui/rmarkdown.
Xie, Yihui, Christophe Dervieux, and Emily Riederer. 2020.
R Markdown Cookbook. Boca Raton, Florida: Chapman; Hall/CRC.
https://bookdown.org/yihui/rmarkdown-cookbook.