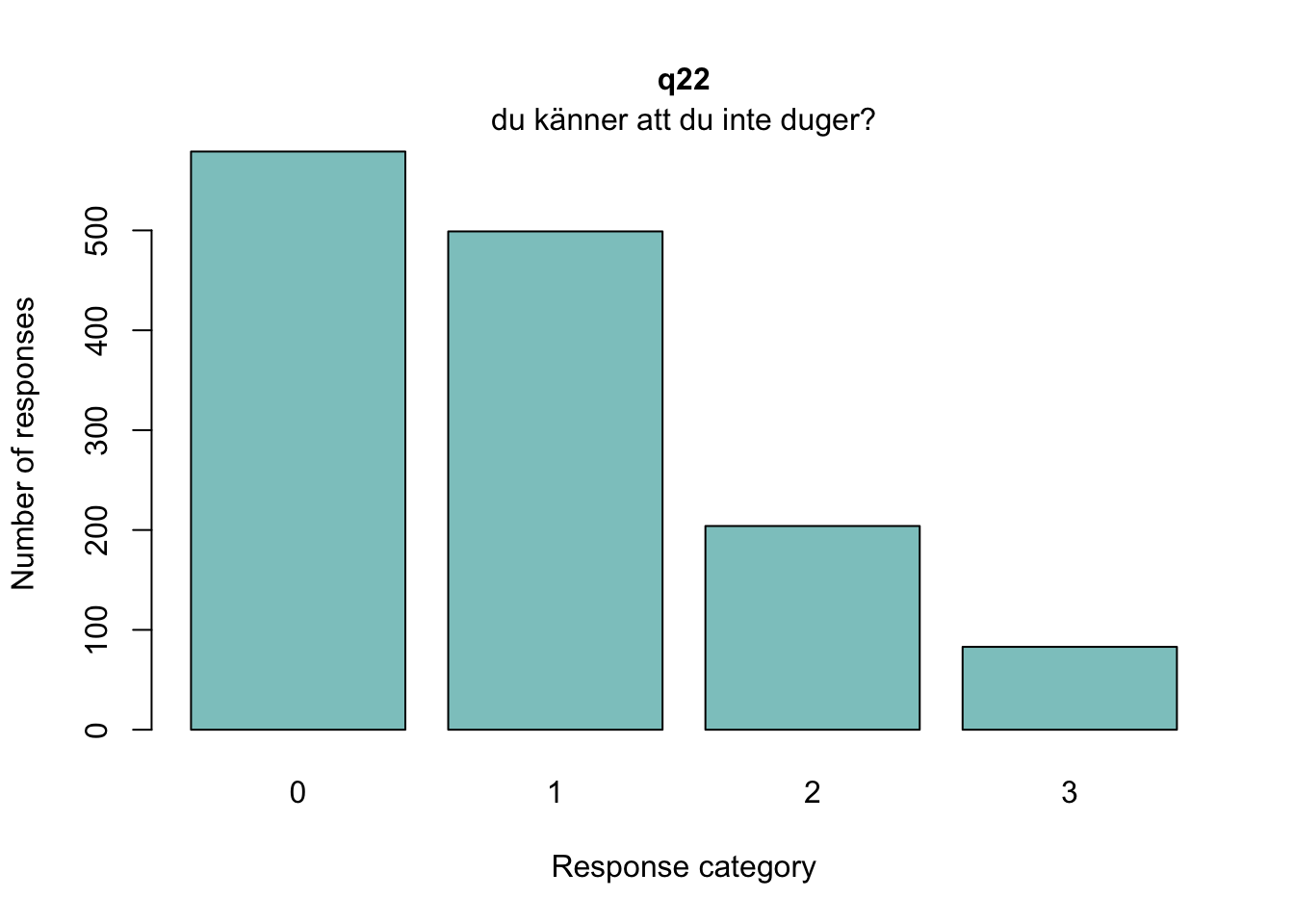
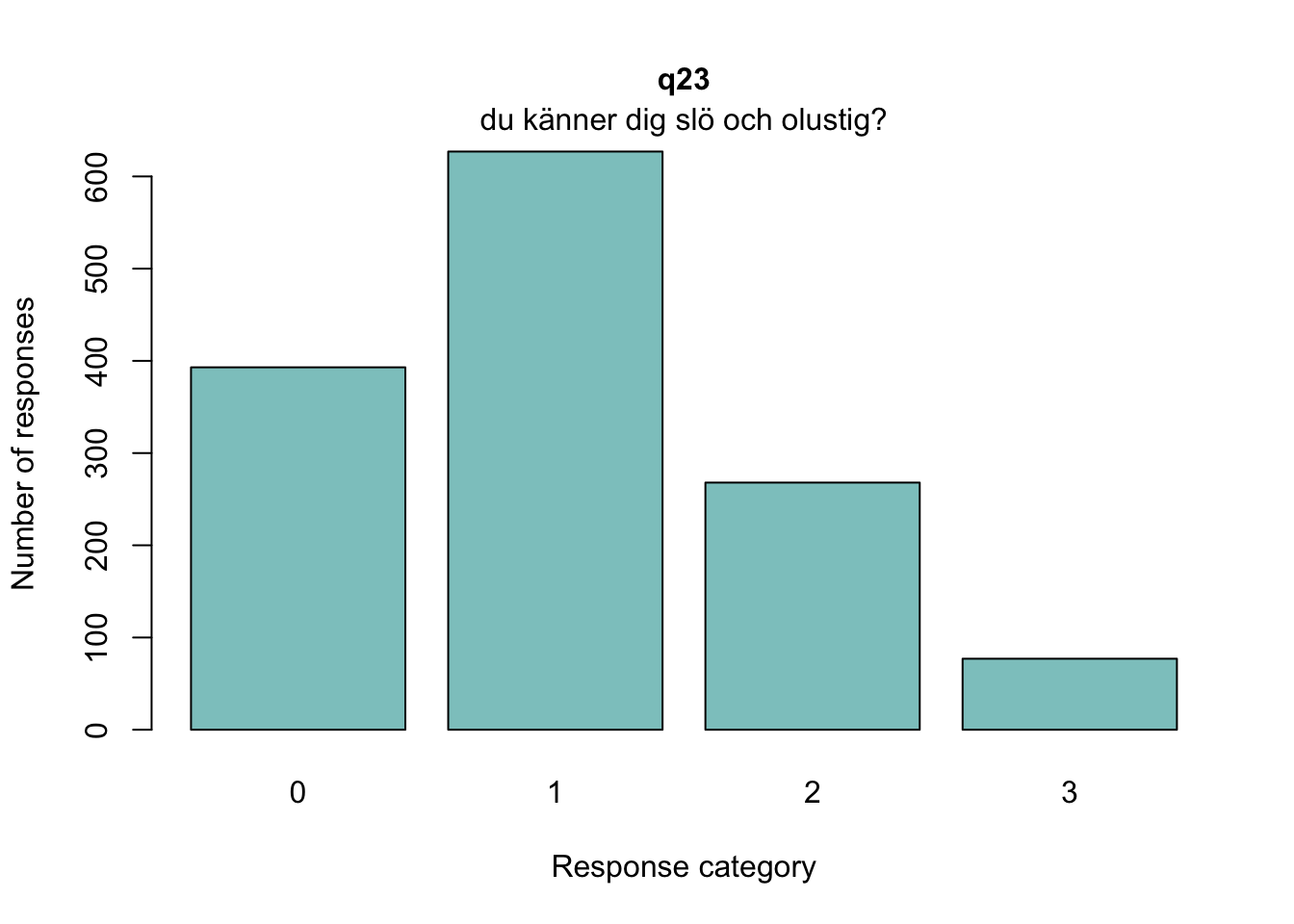
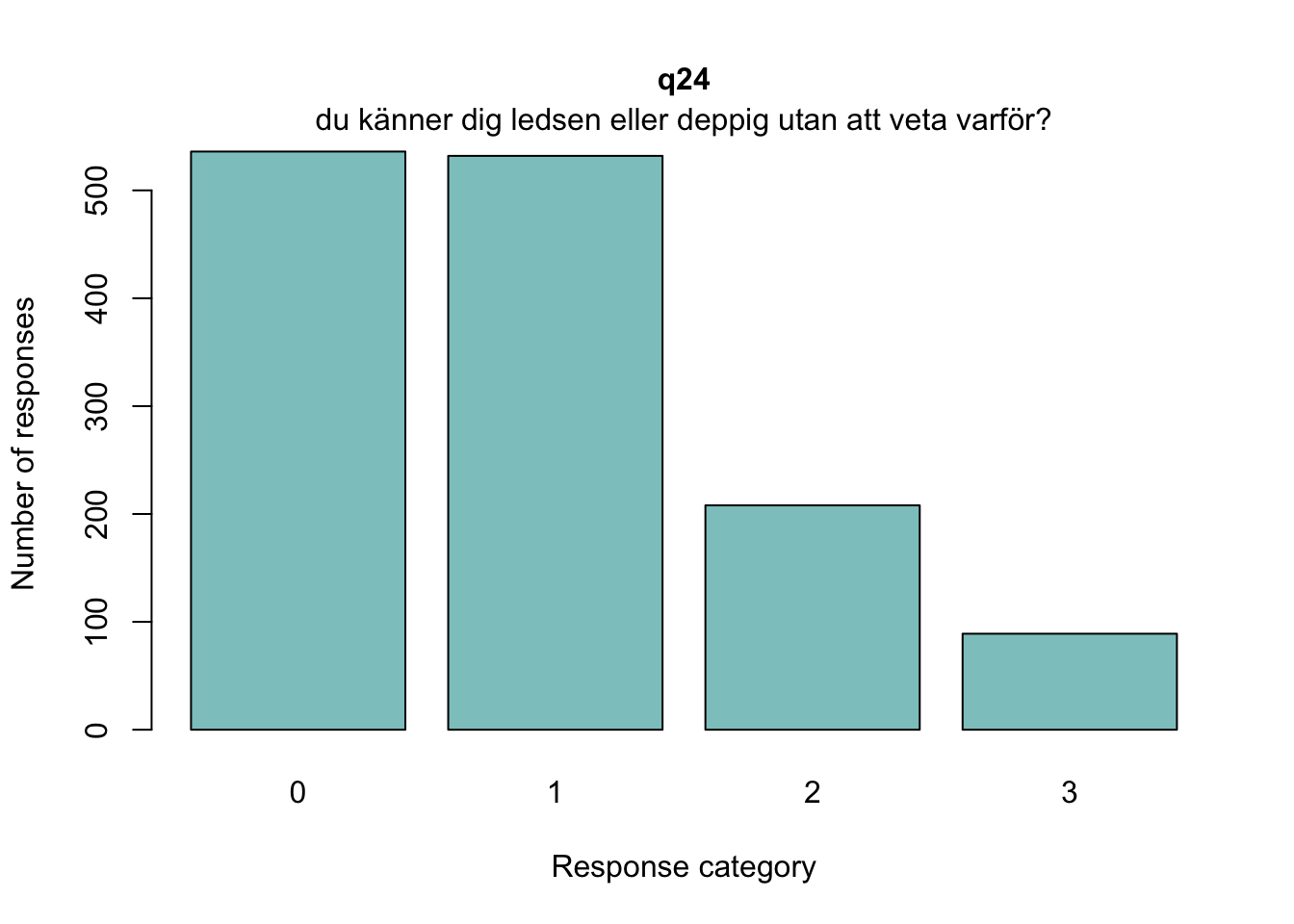
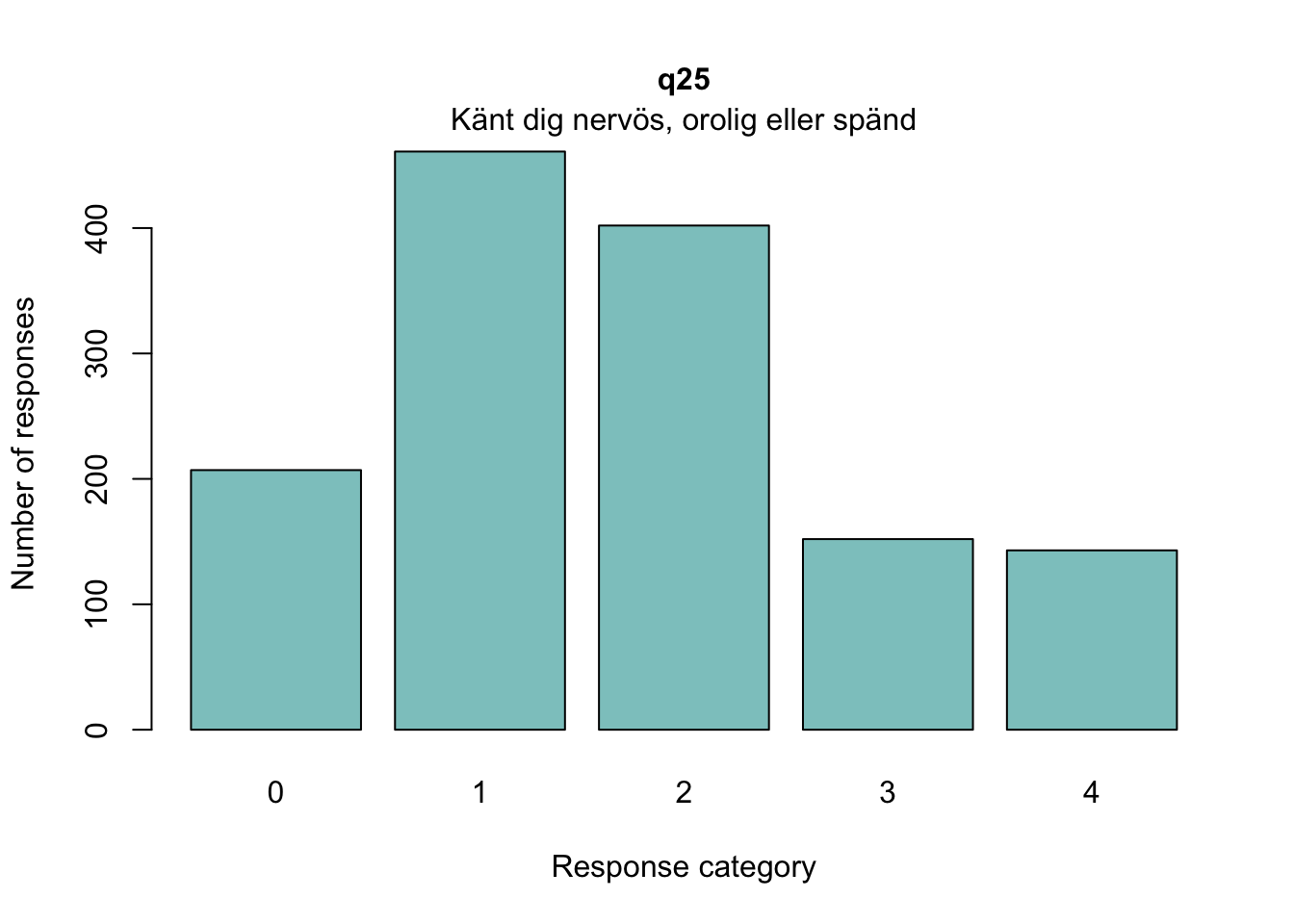
### Tar bort observationer som inte är tjej eller killedf<-df%>%filter(!grepl("annan könsidentitet|vill inte svara", tolower(q3)))df<-df%>%filter(!is.na(q3))### Byter namn på demografiska variablercount(df, q3)
# A tibble: 2 × 2
q3 n
<chr> <int>
1 Kille 671
2 Tjej 719
Code
count(df, q1)
# A tibble: 2 × 2
q1 n
<chr> <int>
1 År 2 på gymnasiet 744
2 Årskurs 9 i grundskolan 646
Code
count(df, q6)
# A tibble: 5 × 2
q6 n
<chr> <int>
1 Annat boende 19
2 Bostadsrätt 333
3 Hyreslägenhet 266
4 Villa/parhus/radhus 767
5 <NA> 5
# A tibble: 2 × 2
Kön n
<chr> <int>
1 Kille 671
2 Tjej 719
Code
count(df, q7, q8, q9)
# A tibble: 53 × 4
q7 q8 q9 n
<chr> <chr> <chr> <int>
1 I Sverige I Sverige I Sverige 863
2 I Sverige I Sverige I ett land i övriga Europa 37
3 I Sverige I Sverige I ett land i övriga Norden 16
4 I Sverige I Sverige I ett land i övriga världen 77
5 I Sverige I Sverige <NA> 1
6 I Sverige I ett land i övriga Europa I Sverige 29
7 I Sverige I ett land i övriga Europa I ett land i övriga Europa 28
8 I Sverige I ett land i övriga Europa I ett land i övriga världen 6
9 I Sverige I ett land i övriga Norden I Sverige 13
10 I Sverige I ett land i övriga Norden I ett land i övriga Europa 3
# ℹ 43 more rows
Code
### Koda om kön till numerisk + rätt etiketter#d$Kön <- recode(d$Kön,"'Tjej'=1;'Kille'=2",as.factor=FALSE)#d$Kön <- labelled(d$Kön, labels = c("Tjej" = 1, "Kille" = 2))#d$Årskurs<-recode(d$Årskurs,"'Årskurs 9 i grundskolan'=1;'År 2 på gymnasiet'=2",as.factor=FALSE)#d$Årskurs <- labelled(d$Årskurs, labels = c("årskurs 9" = 1, "år 2" = 2))d$Kön<-factor(d$Kön)d$Årskurs<-factor(d$Årskurs, labels =c("Åk 9","Gy 2"))
3.2 Välbefinnande
Code
count(df, q13, q20)
# A tibble: 29 × 3
q13 q20 n
<chr> <chr> <int>
1 Aldrig Lika bra 1
2 Aldrig Lite bättre 2
3 Aldrig Lite sämre 5
4 Aldrig Mycket bättre 5
5 Aldrig Mycket sämre 8
6 Ganska ofta Lika bra 203
7 Ganska ofta Lite bättre 161
8 Ganska ofta Lite sämre 66
9 Ganska ofta Mycket bättre 114
10 Ganska ofta Mycket sämre 12
# ℹ 19 more rows
# A tibble: 25 × 3
q21 q28 n
<chr> <chr> <int>
1 Aldrig/sällan En eller två dagar 262
2 Aldrig/sällan Flera dagar 112
3 Aldrig/sällan Inte besvärats alls 470
4 Aldrig/sällan Mer än hälften av dagarna 32
5 Aldrig/sällan Nästan varje dag 25
6 Aldrig/sällan <NA> 2
7 Ganska ofta En eller två dagar 30
8 Ganska ofta Flera dagar 29
9 Ganska ofta Inte besvärats alls 7
10 Ganska ofta Mer än hälften av dagarna 10
# ℹ 15 more rows
Code
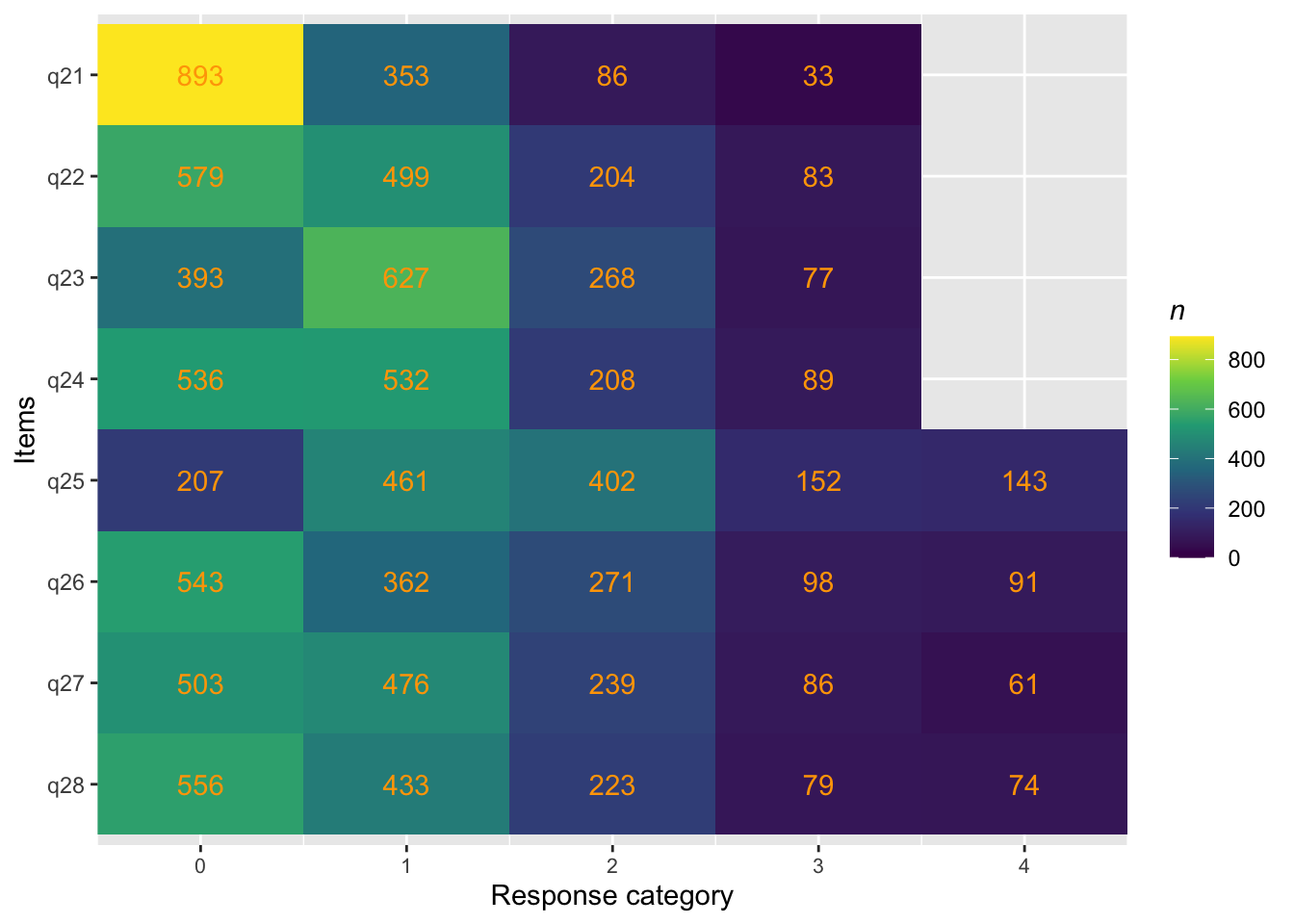
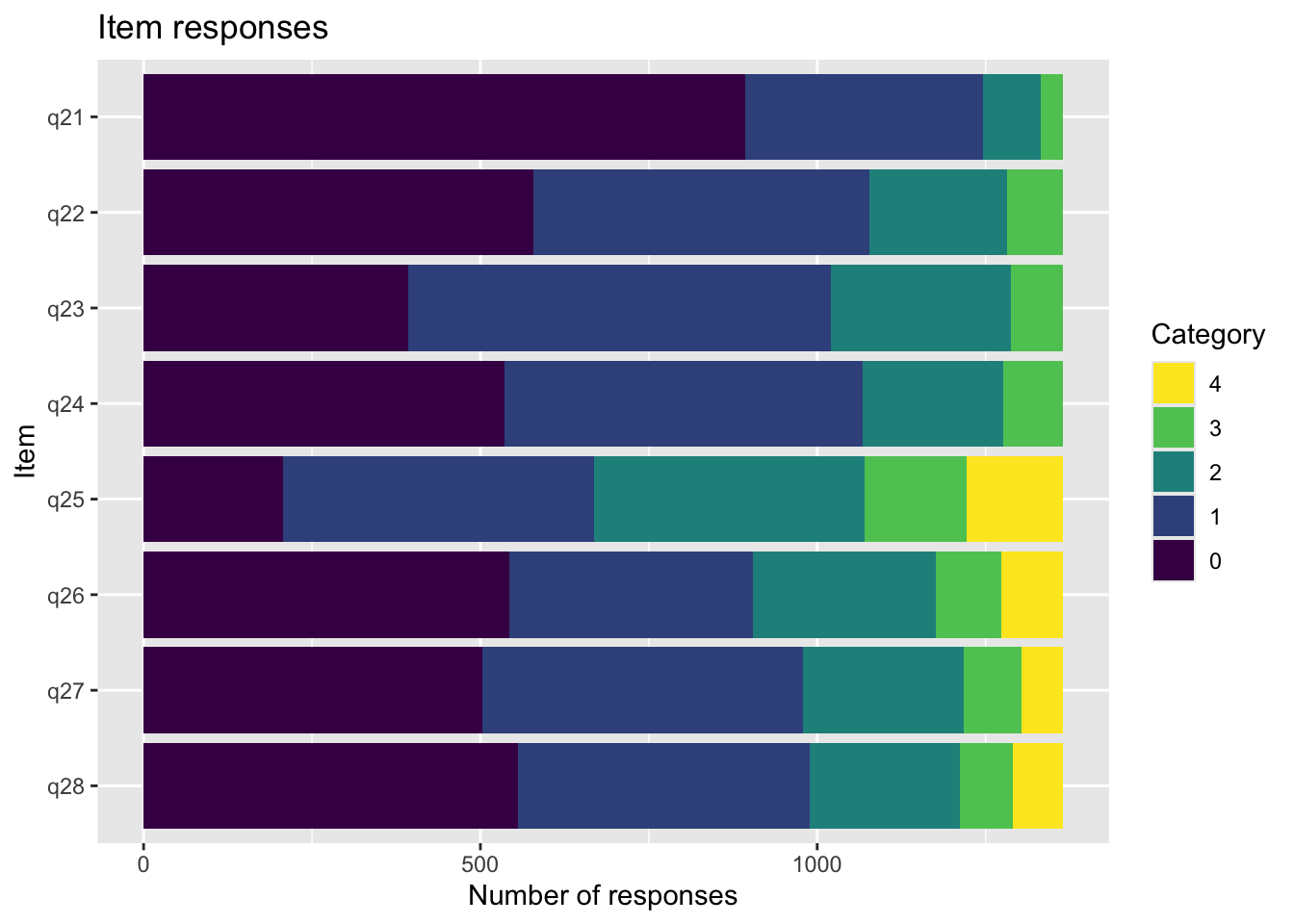
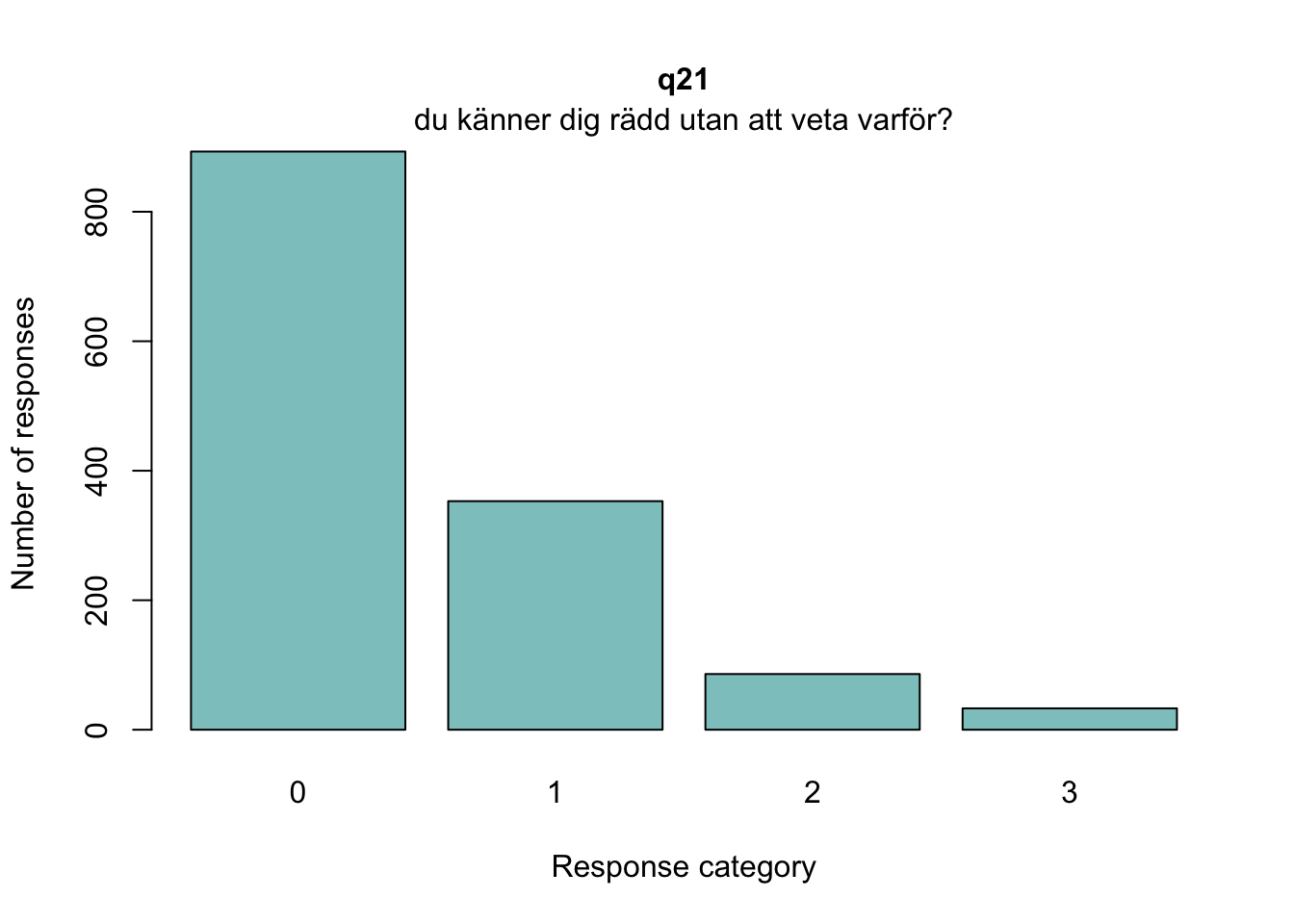
psf<-c("q21", "q22", "q23", "q24", "q25", "q26", "q27", "q28")# Koda om till numeriska + etiktter. Låga värden = låg riskd<-d%>%mutate(across(q21:q24, ~recode(.x,"'Aldrig/sällan'=0; 'Ibland'=1; 'Ganska ofta'=2; 'Mycket ofta'=3", as.factor =FALSE)))%>%mutate(across(q21:q24, ~labelled(.x, labels =c("Aldrig/sällan"=0,"Ibland"=1,"Ganska ofta"=2,"Mycket ofta"=3))))d<-d%>%mutate(across(q25:q28, ~recode(.x,"'Inte besvärats alls'=0; 'En eller två dagar'=1; 'Flera dagar'=2; 'Mer än hälften av dagarna'=3; 'Nästan varje dag'=4", as.factor =FALSE)))%>%mutate(across(q25:q28, ~labelled(.x, labels =c("Inte besvärats alls"=0,"En eller två dagar"=1,"Flera dagar"=2,"Mer än hälften av dagarna"=3, "Nästan varje dag"=4))))#d$q20<-recode(d$q20,"'Mycket bättre'=0;'Lite bättre'=1; 'Lika bra'=2; 'Lite sämre'=3; 'Mycket sämre'=4",as.factor=FALSE)#d$q20 <- labelled(d$q20, labels = c("Mycket bättre" = 0, "Lite bättre" = 1, "Lika bra" = 2, "Lite sämre" = 3,"Mycket sämre" = 4))count(d, q21)
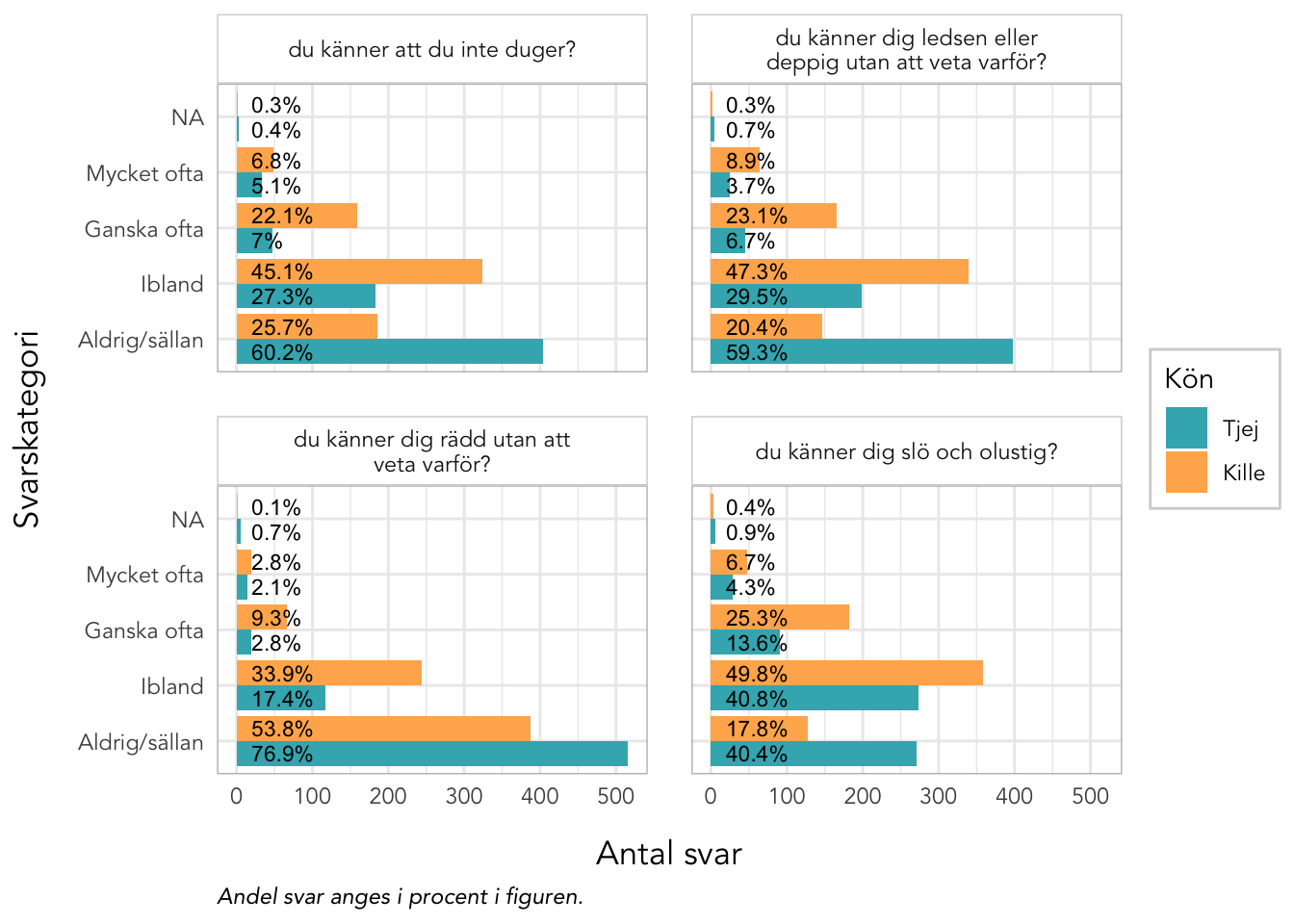
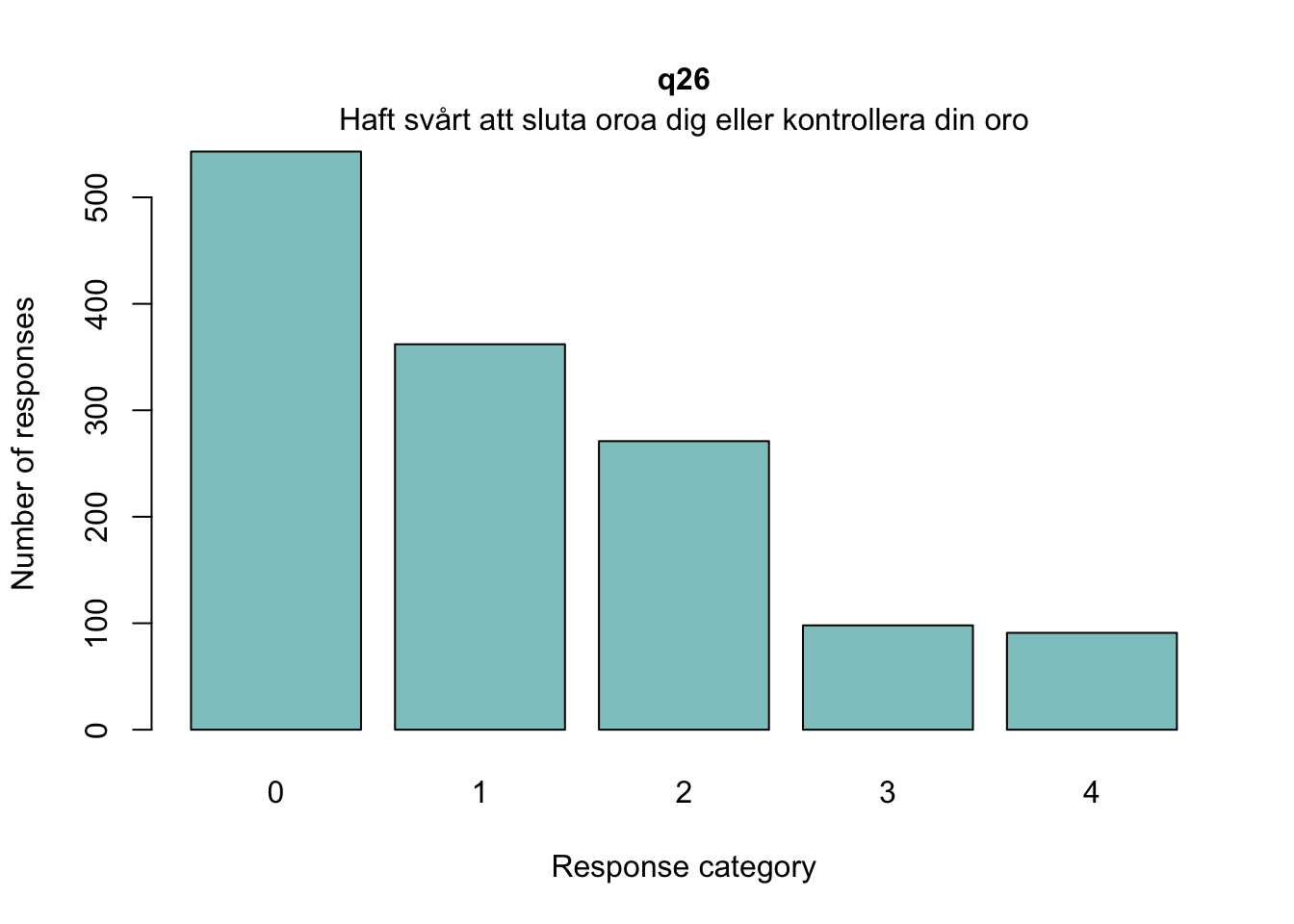
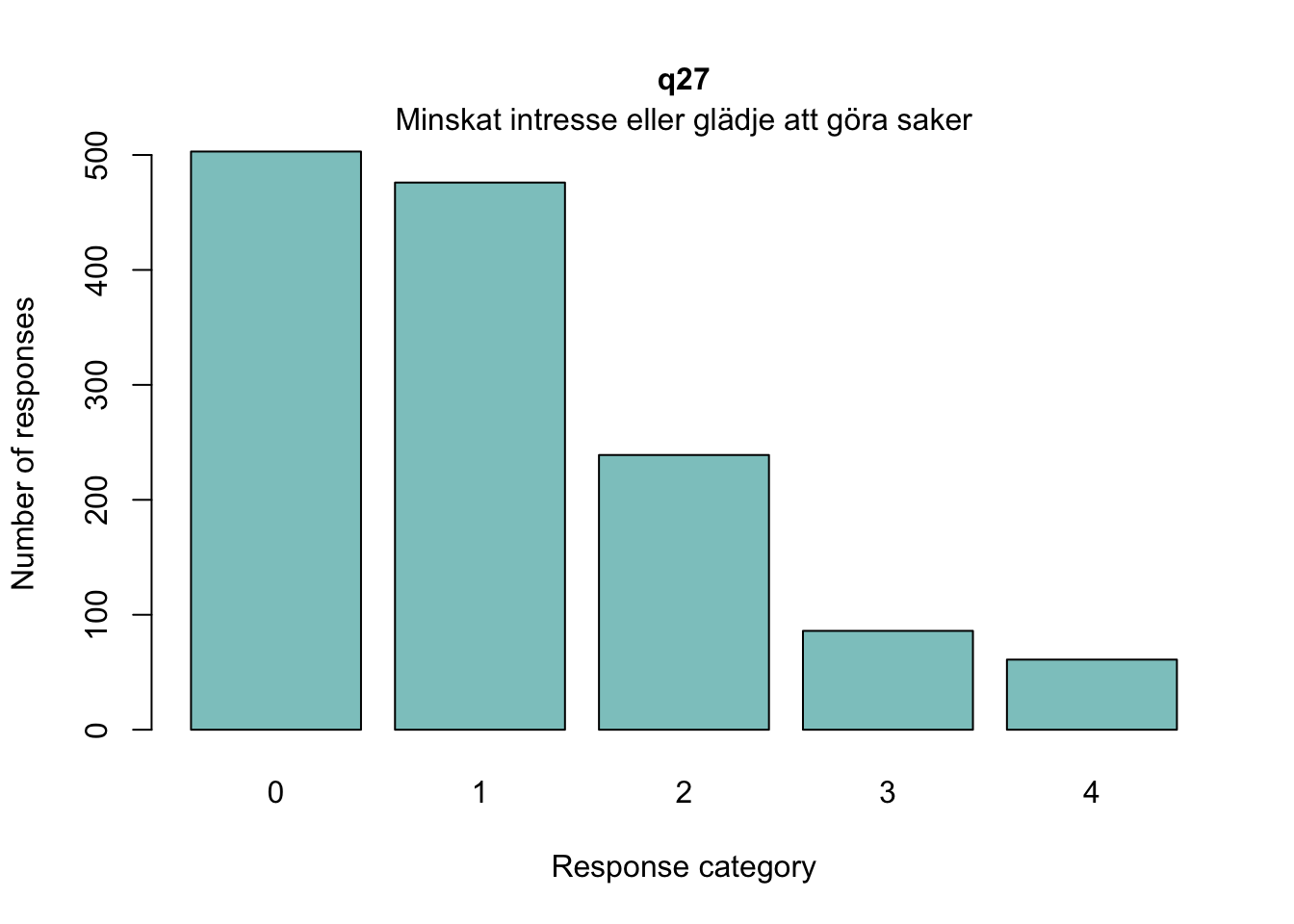
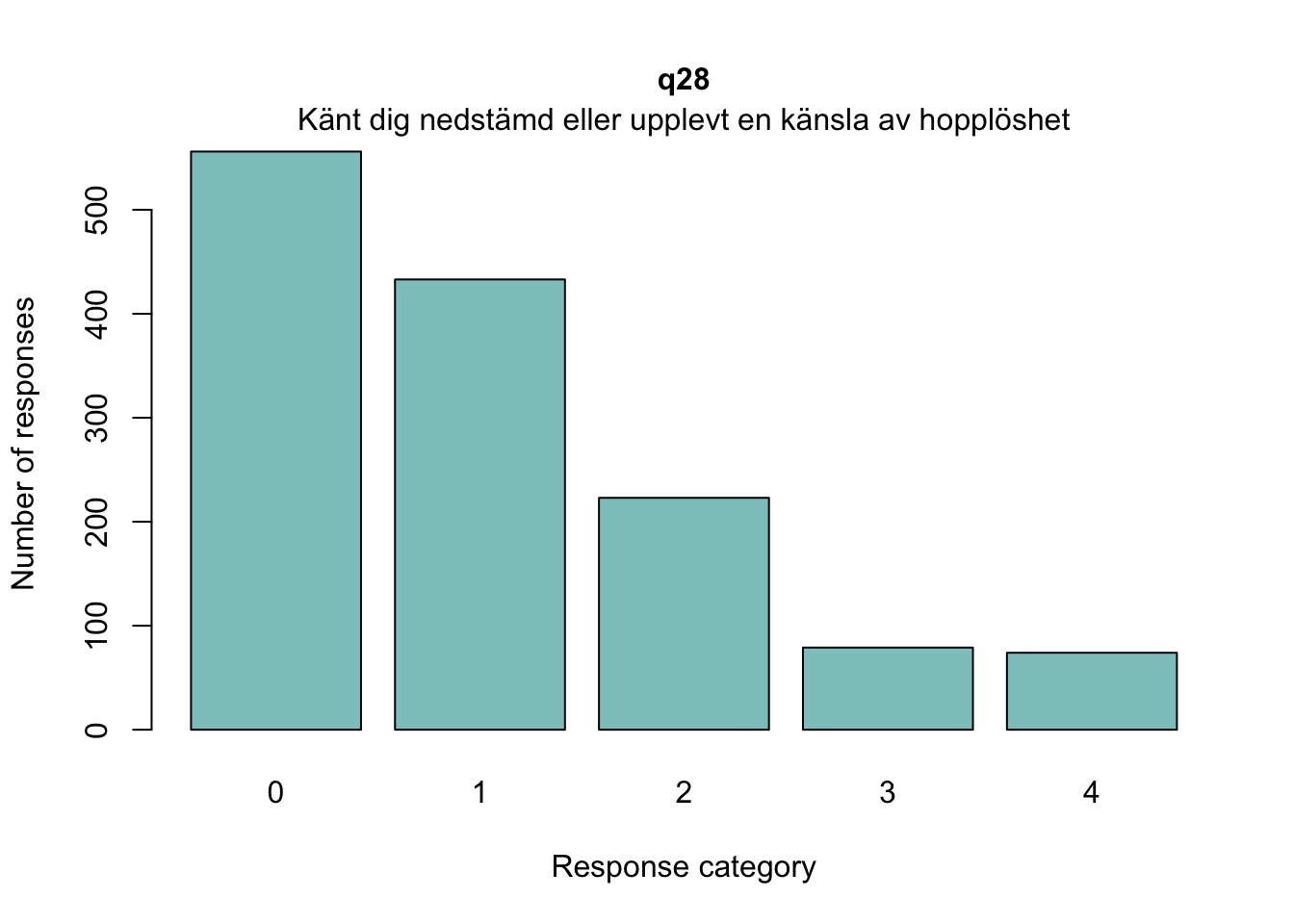
Sektionen i PDF/pappers-enkäten inleds med meningen: “NÅGRA FRÅGOR OM HUR DU MÅR”.
3.5 DF för välbefinnande
Code
# Skapa dataframe för välbefinnande utan NA:sd_v<-d%>%select(Kön, Årskurs, Bostad, any_of(välbefinnande))%>%na.omit()# Skapa DIF dfd_dif_v<-d_v%>%select(Kön, Årskurs, Bostad)%>%mutate(across(everything(), ~factor(.x)))# remove non-itemsd_v<-d_v%>%select(!c(Kön,Årskurs,Bostad))
3.6 DF för PSF
Code
# Skapa dataframe för alla PSF utan NA:sd_psf<-d%>%select(Kön, Årskurs, Bostad, any_of(psf))%>%na.omit()# Skapa DIF dfd_dif__psf<-d_psf%>%select(Kön, Årskurs, Bostad)%>%mutate(across(everything(), ~factor(.x)))# remove non-itemsd_psf<-d_psf%>%select(!c(Kön,Årskurs,Bostad))# Skapa dataframe för depressionsitems utan NA:sd_psf_d<-d%>%select(Kön, Årskurs, Bostad, any_of(c("q22", "q23", "q24", "q27", "q28")))%>%na.omit()# Skapa DIF dfd_dif__psf_d<-d_psf_d%>%select(Kön, Årskurs, Bostad)%>%mutate(across(everything(), ~factor(.x)))# remove non-itemsd_psf_d<-d_psf_d%>%select(!c(Kön,Årskurs,Bostad))# Skapa dataframe för ångestitems utan NA:sd_psf_å<-d%>%select(Kön, Årskurs, Bostad, any_of(c("q21", "q25", "q26")))%>%na.omit()# Skapa DIF dfd_dif__psf_å<-d_psf_å%>%select(Kön, Årskurs, Bostad)%>%mutate(across(everything(), ~factor(.x)))# remove non-itemsd_psf_å<-d_psf_å%>%select(!c(Kön,Årskurs,Bostad))
labels_p_25_28<-c("Inte besvärats alls"=0,"En eller två dagar"=1,"Flera dagar"=2,"Mer än hälften av dagarna"=3, "Nästan varje dag"=4)names(labels_p_25_28)
[1] "Inte besvärats alls" "En eller två dagar"
[3] "Flera dagar" "Mer än hälften av dagarna"
[5] "Nästan varje dag"
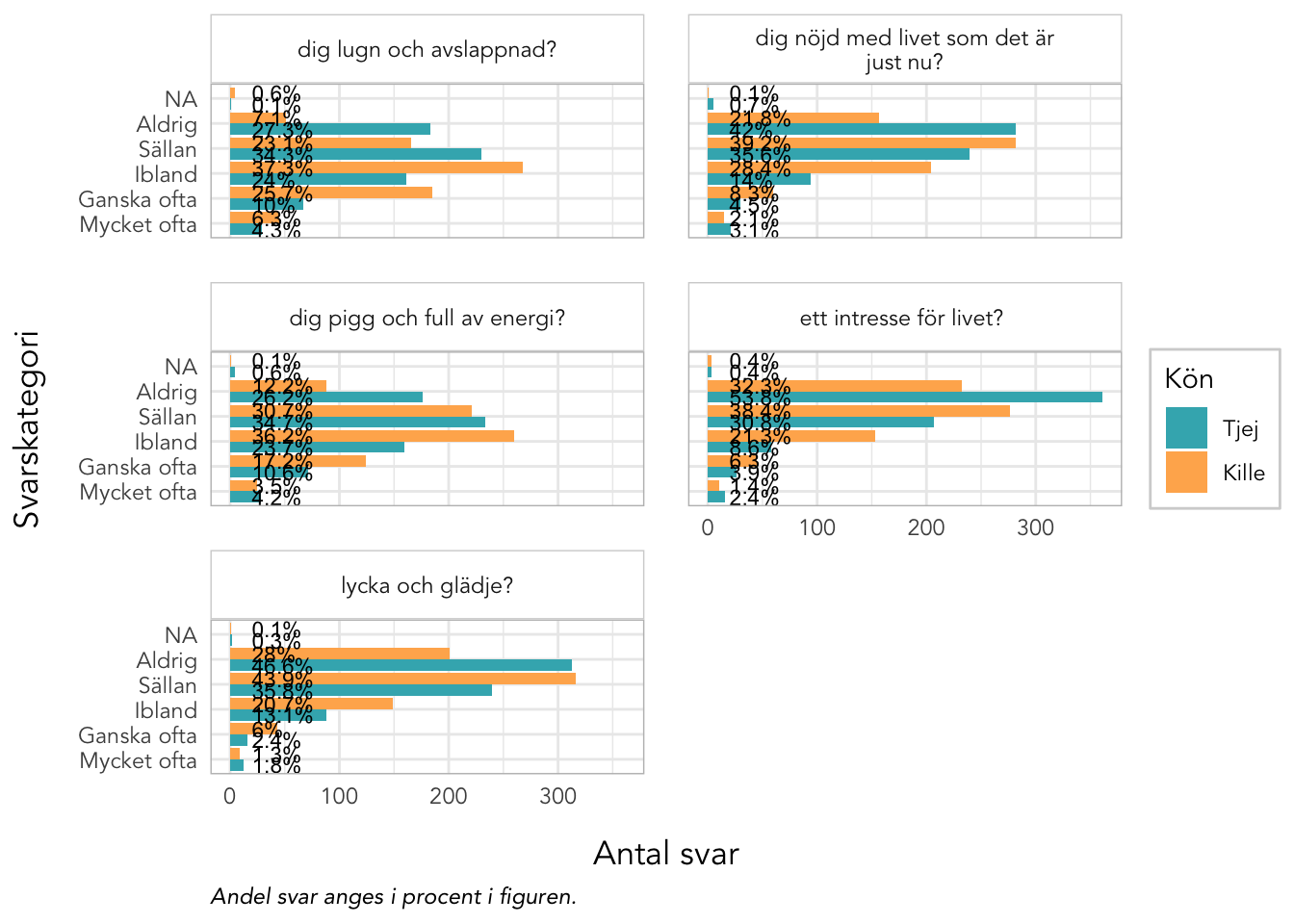
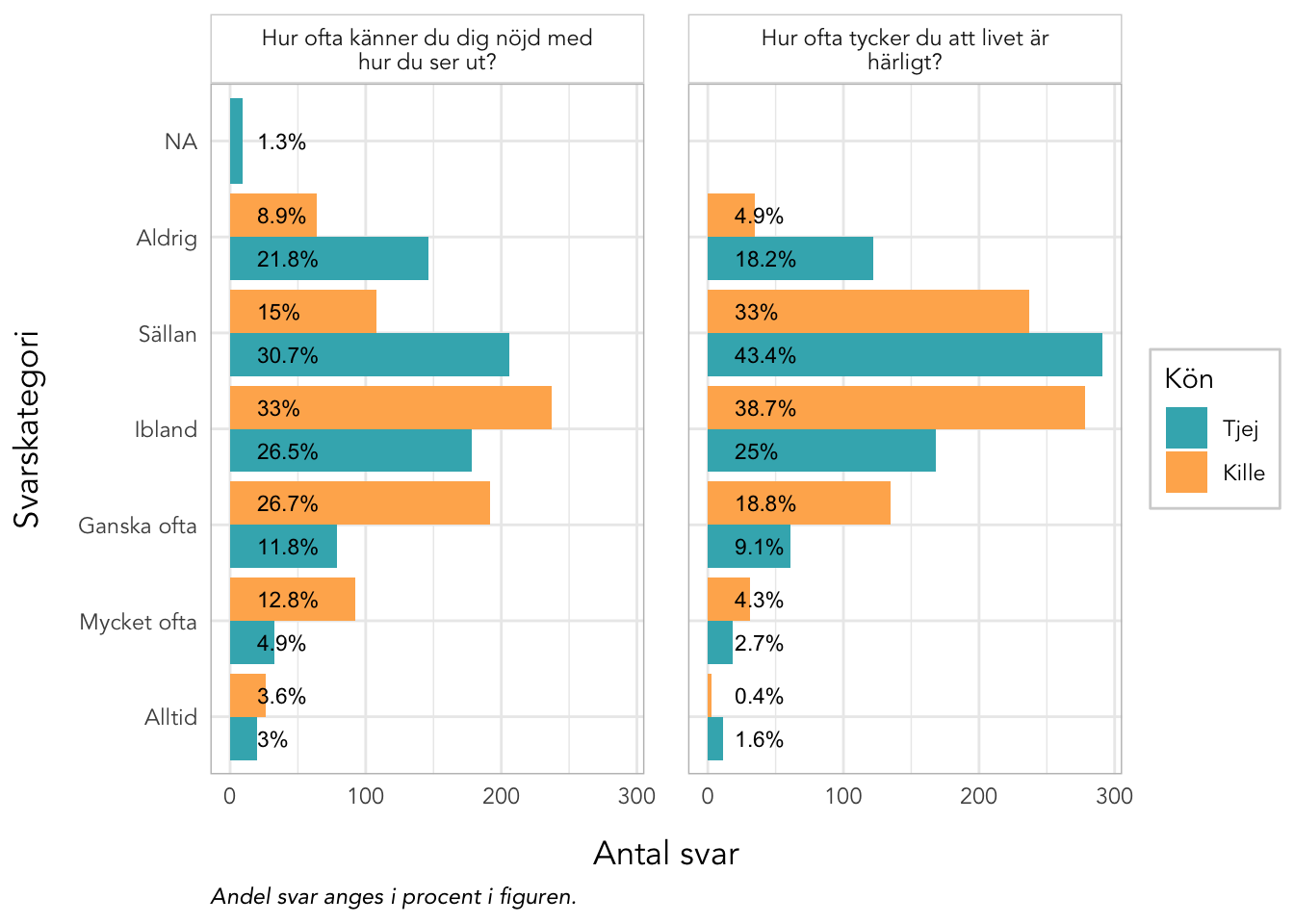
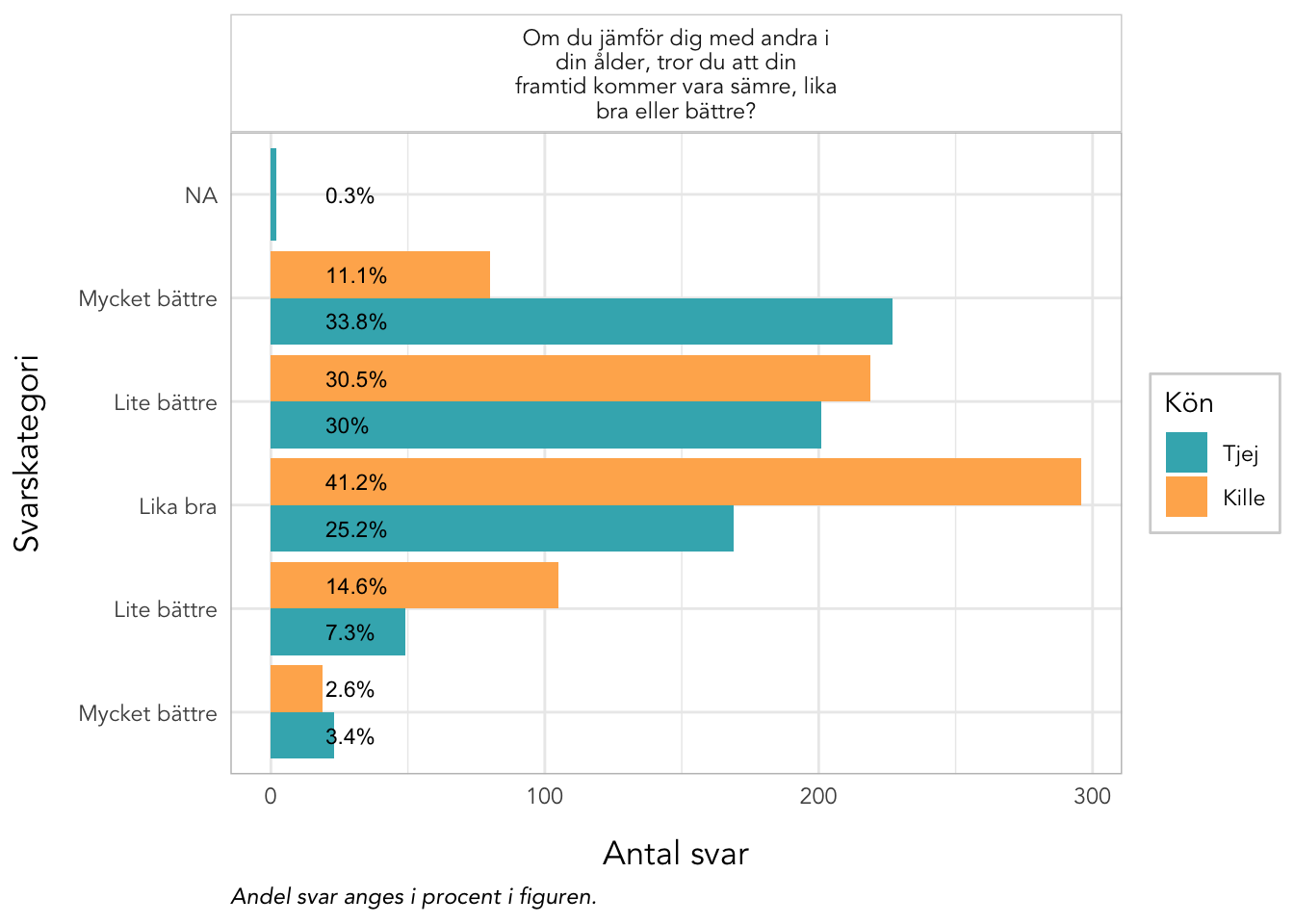
3.8 Deskriptiva data Välbefinnande
3.9 Formatering figur
Code
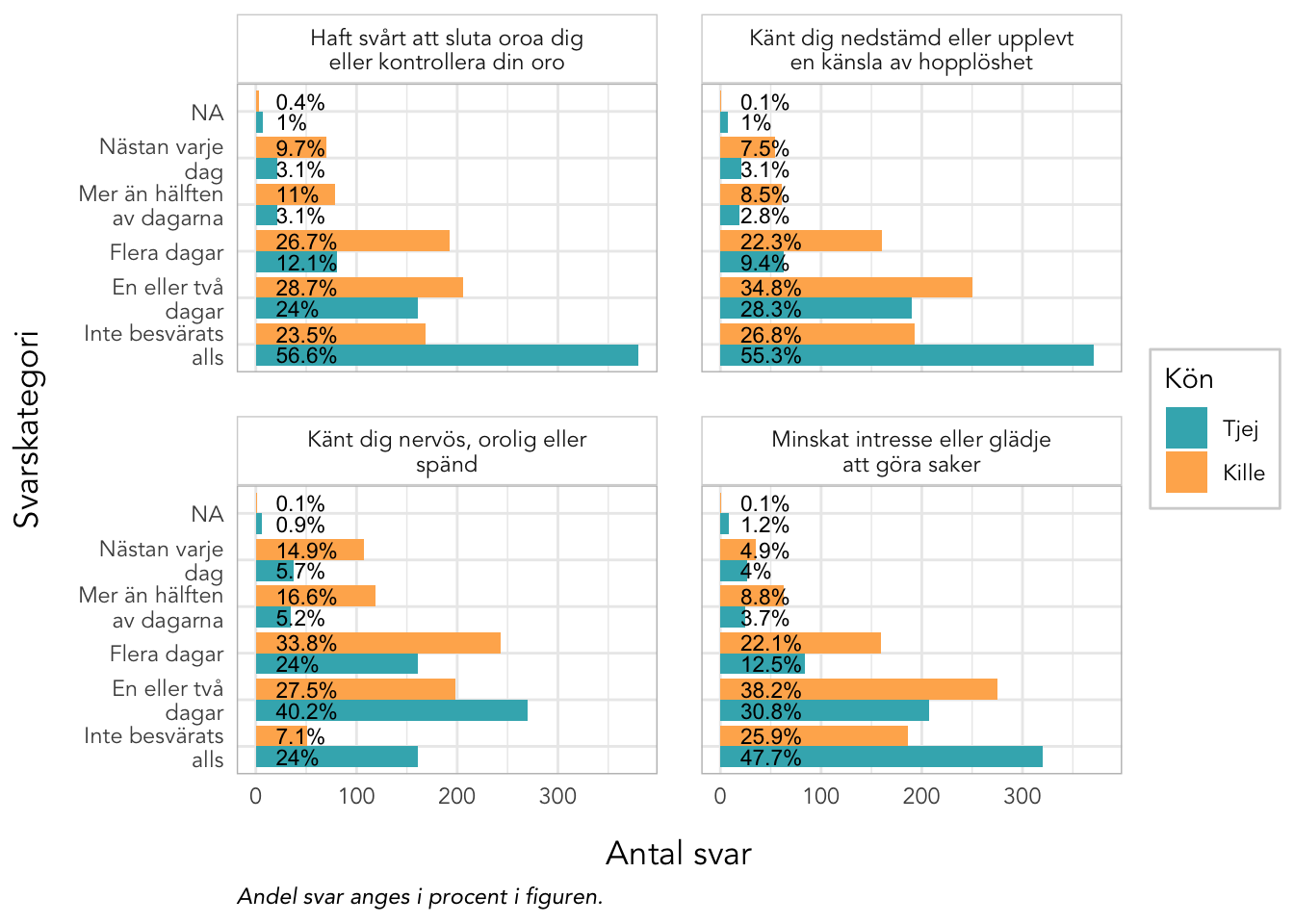
plot_gender<-function(data, items, kolumner=2, labelwrap=24, text_ypos=28, text_size=3){data%>%pivot_longer(all_of(items), names_to ="itemnr")%>%group_by(itemnr,Kön)%>%count(value)%>%mutate(percent =n*100/sum(n))%>%ungroup()%>%mutate(Kön =factor(Kön, labels =c("Tjej","Kille")), value =factor(value, ordered =T))%>%left_join(itemlabels, by ="itemnr")%>%ggplot(aes(x =value, y =n, fill =Kön))+geom_col(position ="dodge")+geom_text(aes(label =paste0(round(percent,1),"%"), y =text_ypos), position =position_dodge(width =0.9), angle =0, color ="black", size =text_size, hjust ="left")+facet_wrap(~item, ncol =kolumner, labeller =labeller(item =label_wrap_gen(labelwrap)))+scale_fill_gender()+theme_rise(fontfamily ="Avenir")+labs(x ="Svarskategori", y ="Antal svar", caption ="Andel svar anges i procent i figuren.")+coord_flip()}
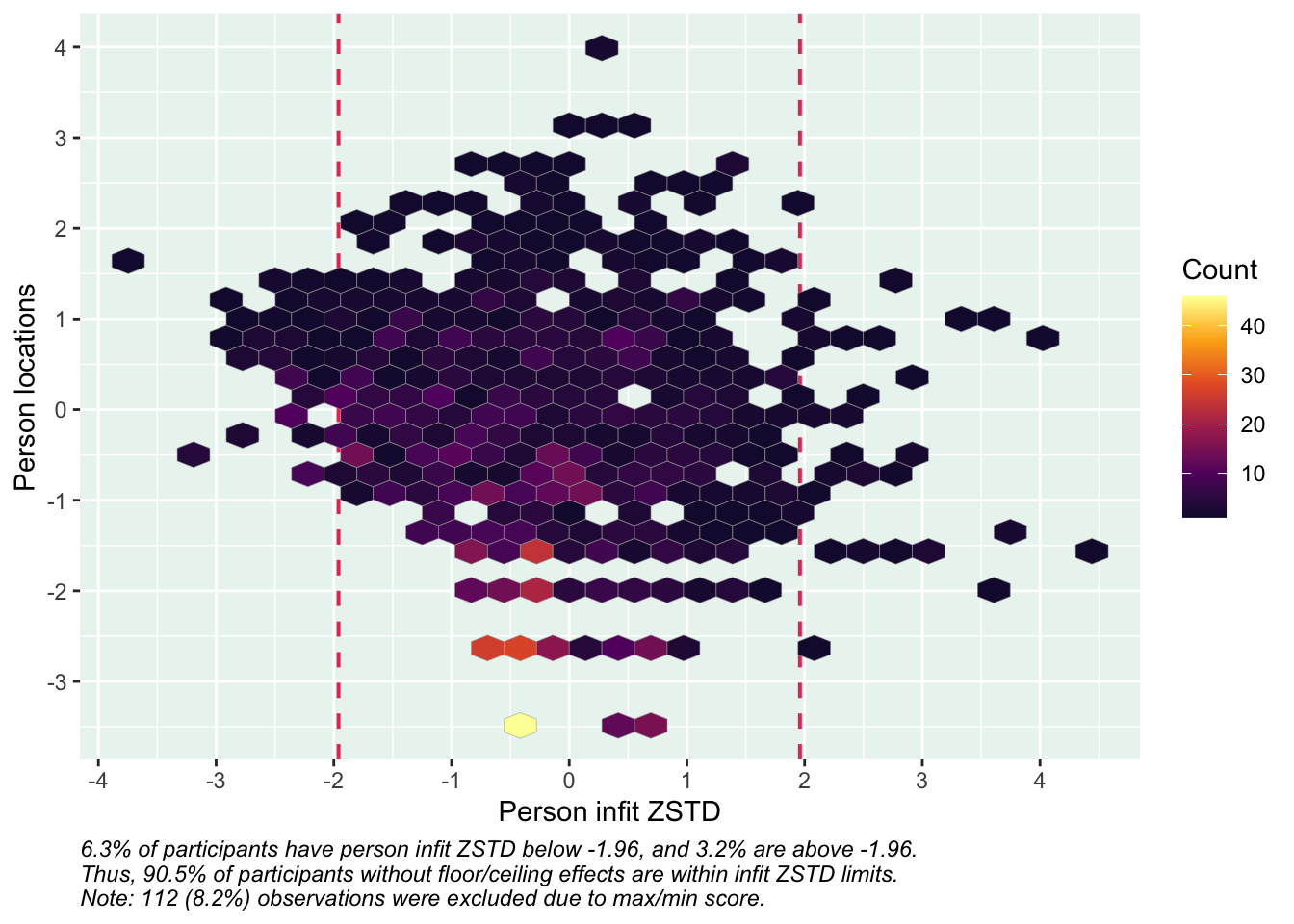
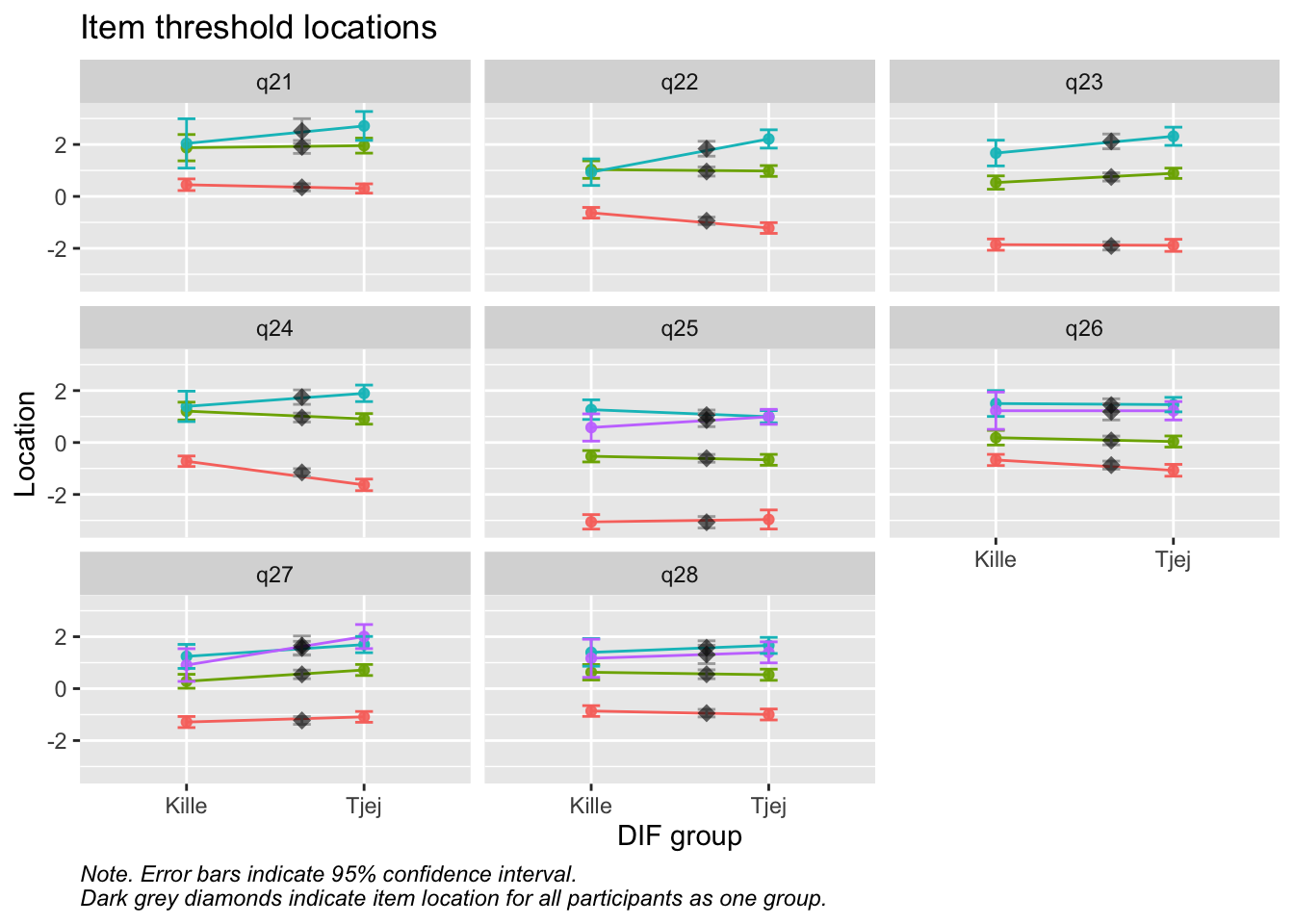
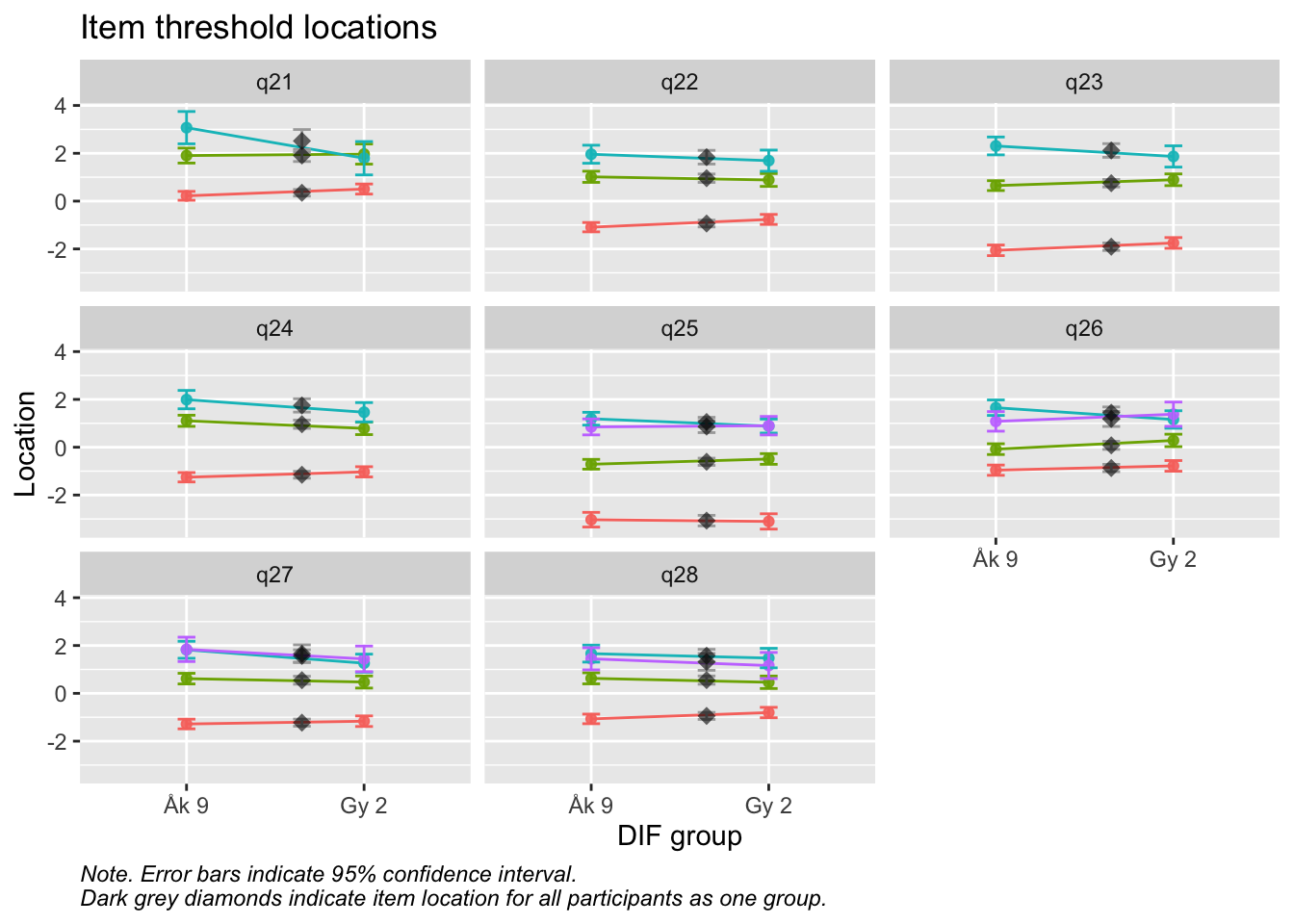
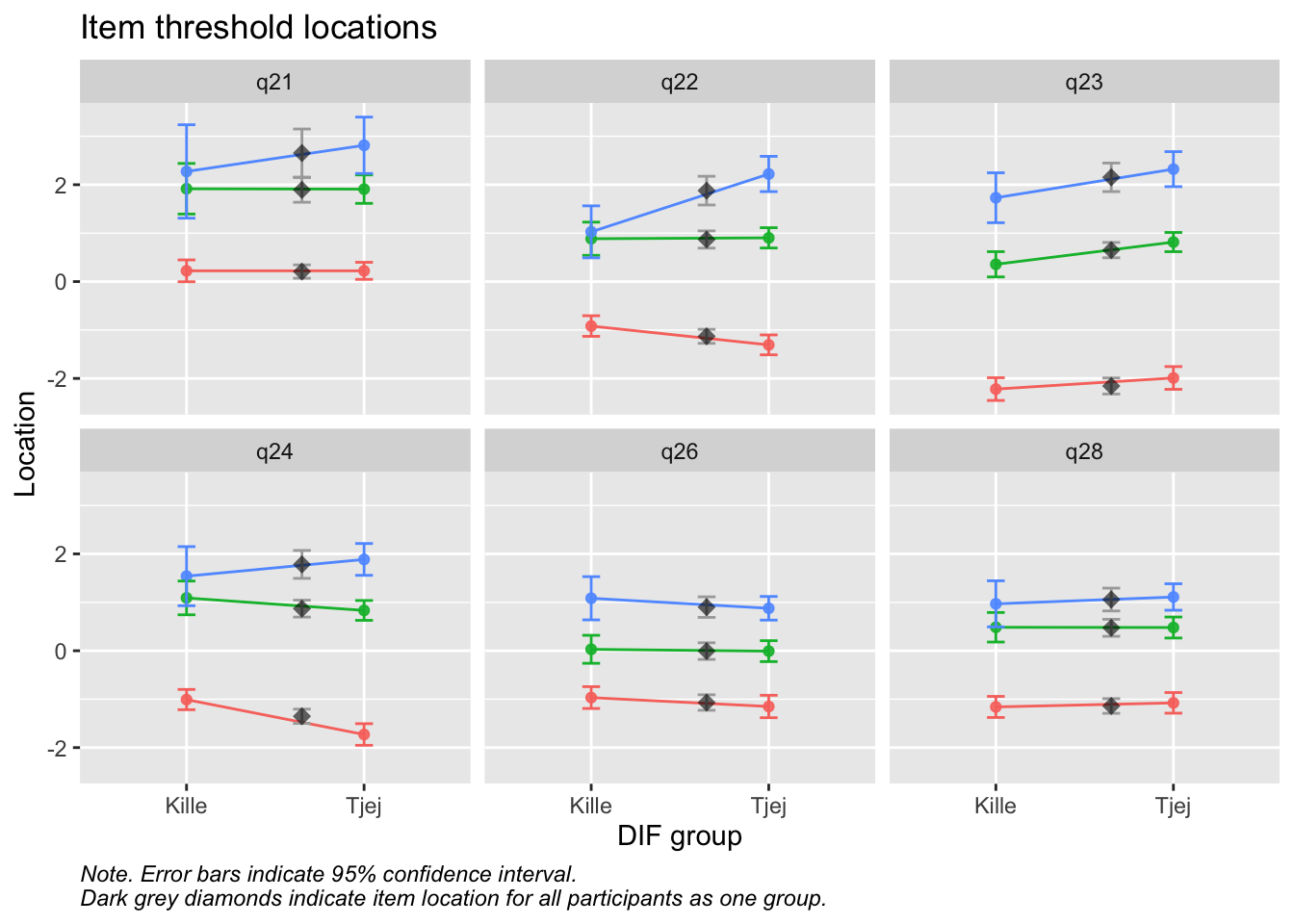
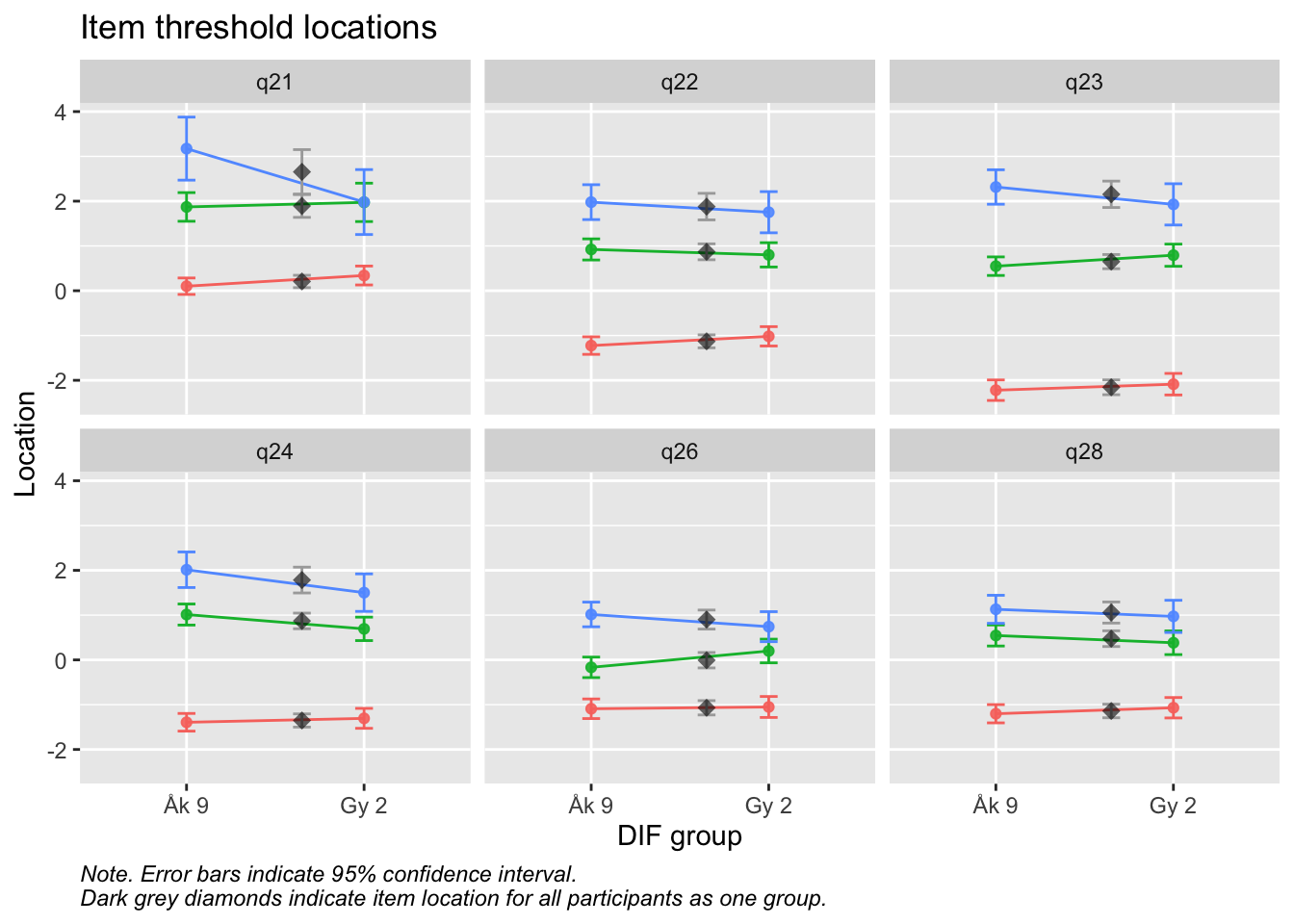
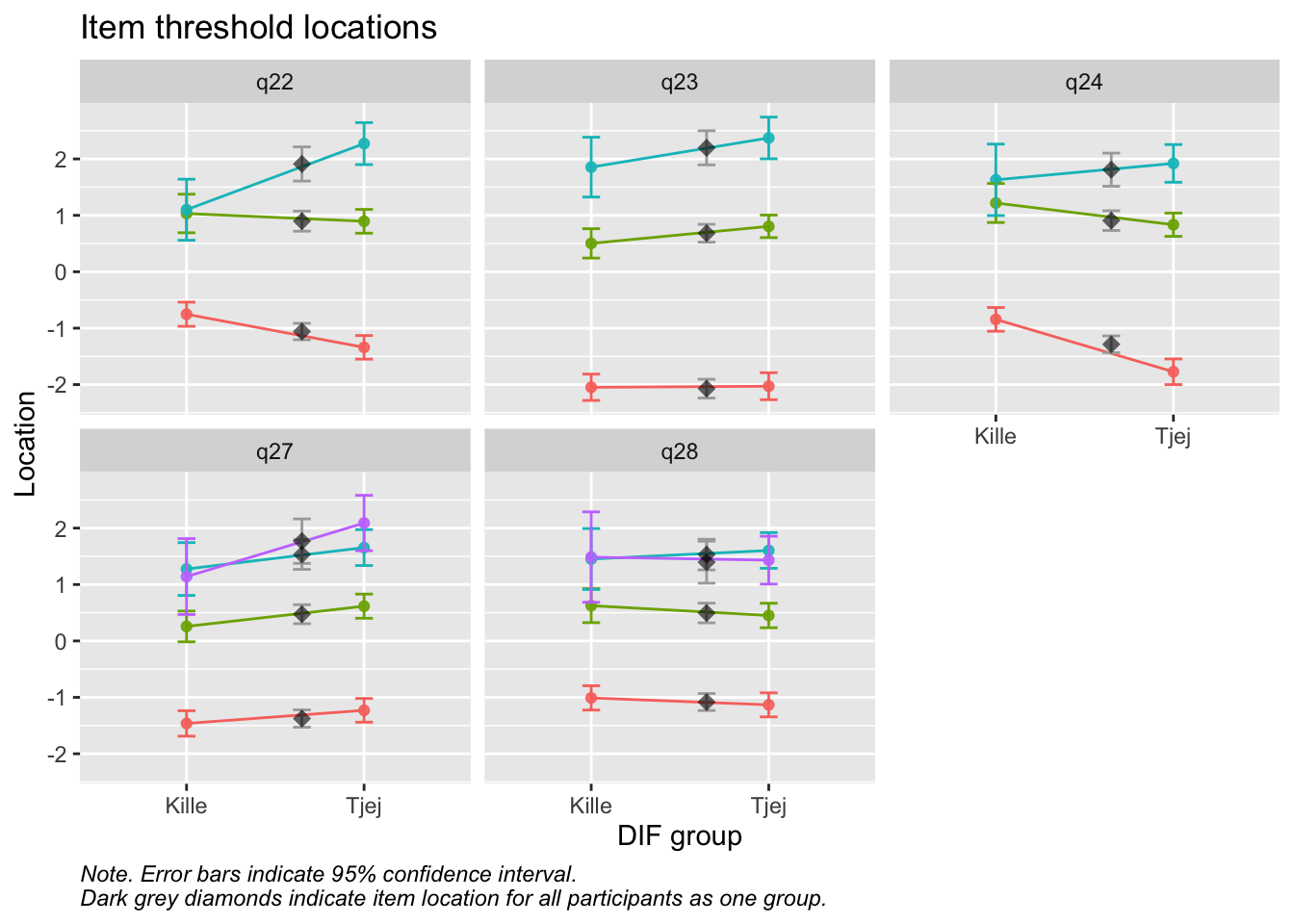
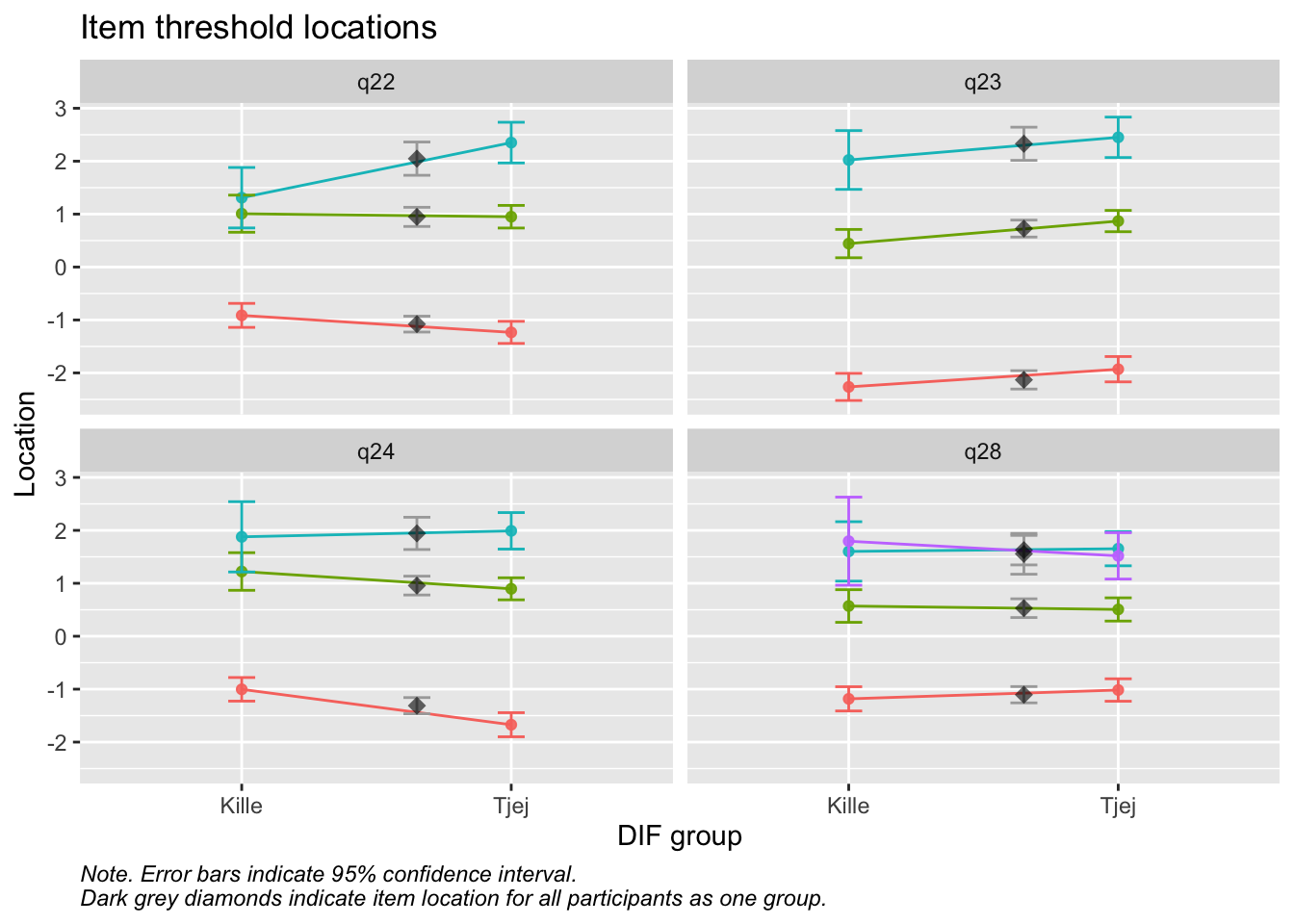
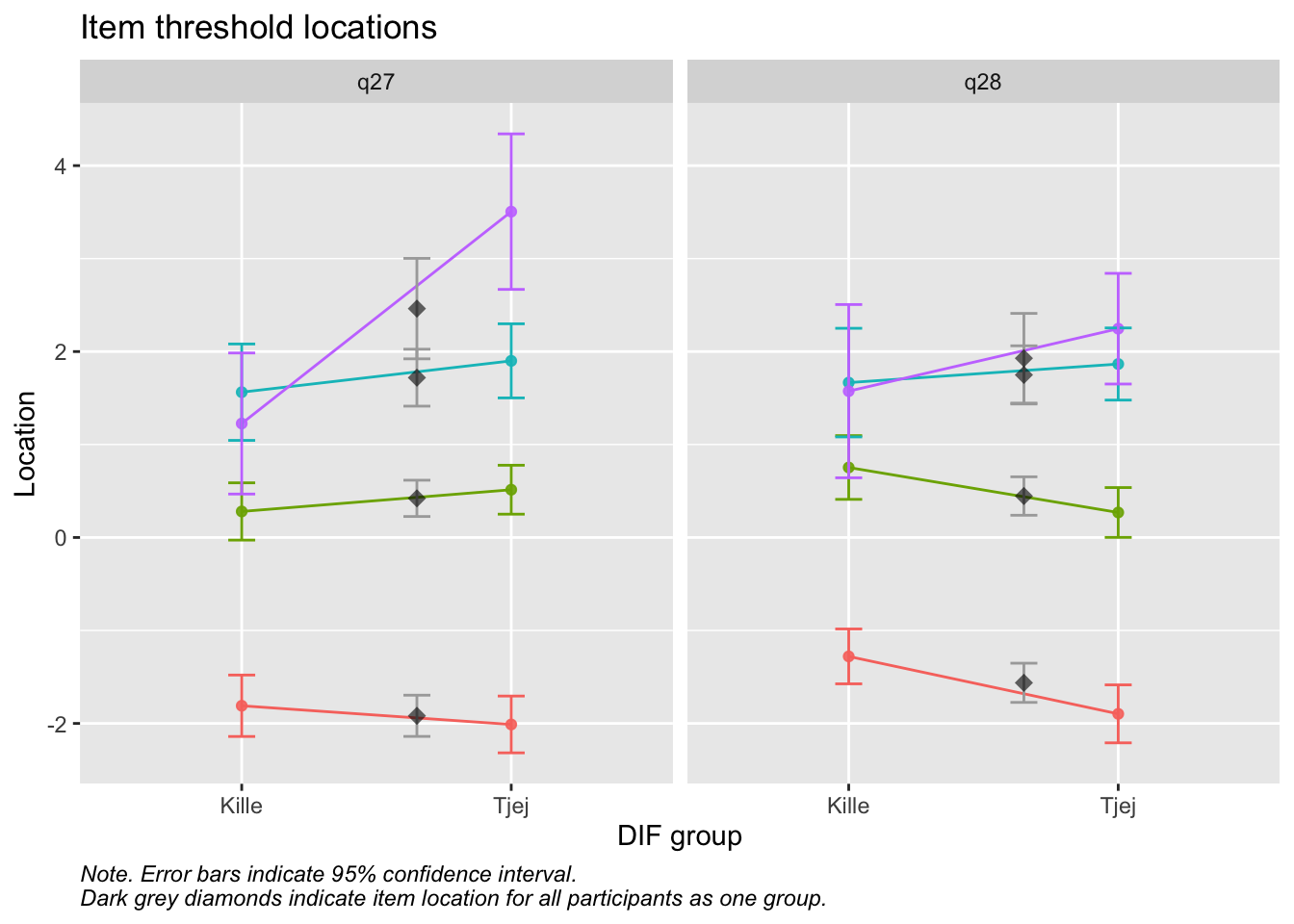
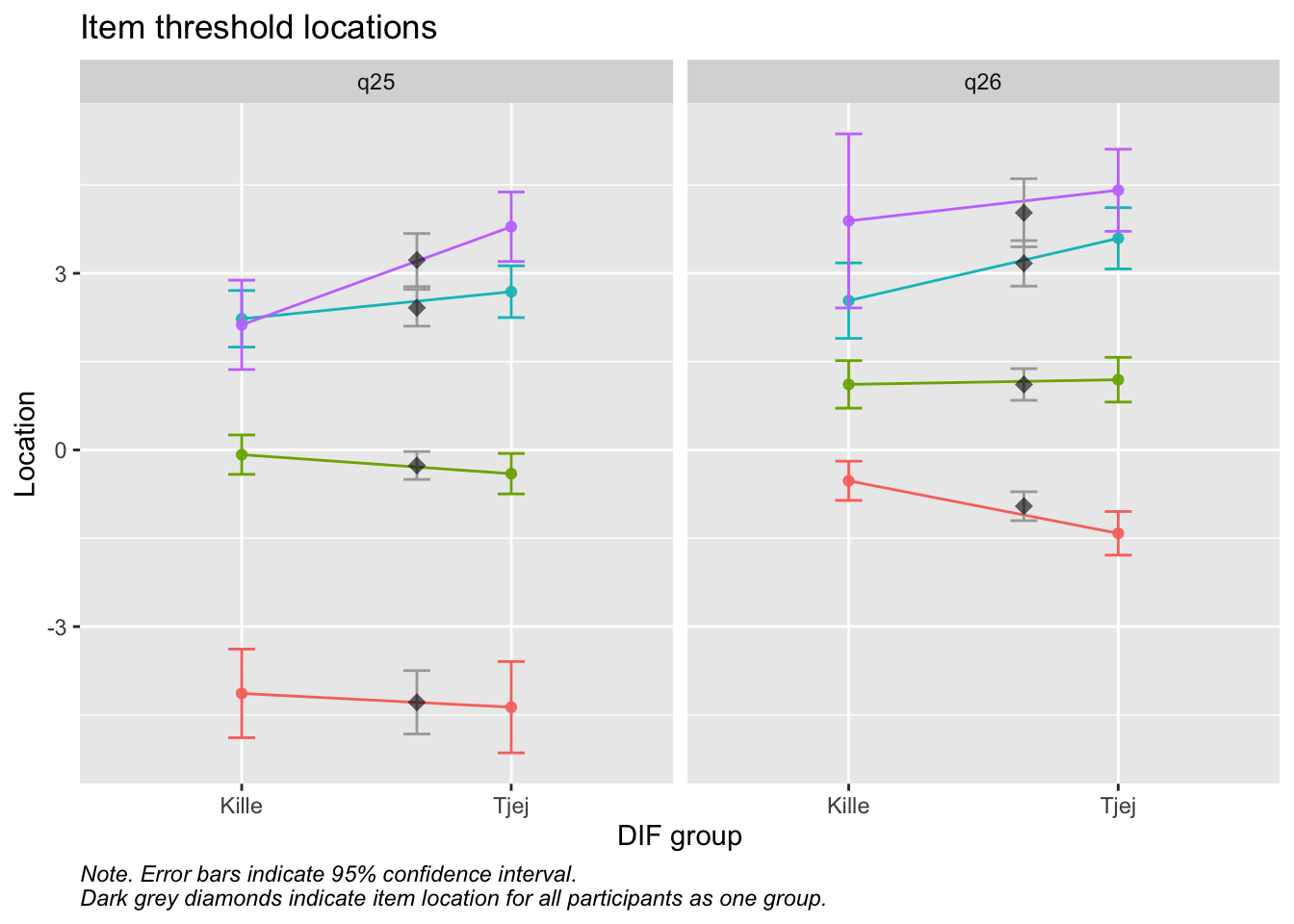
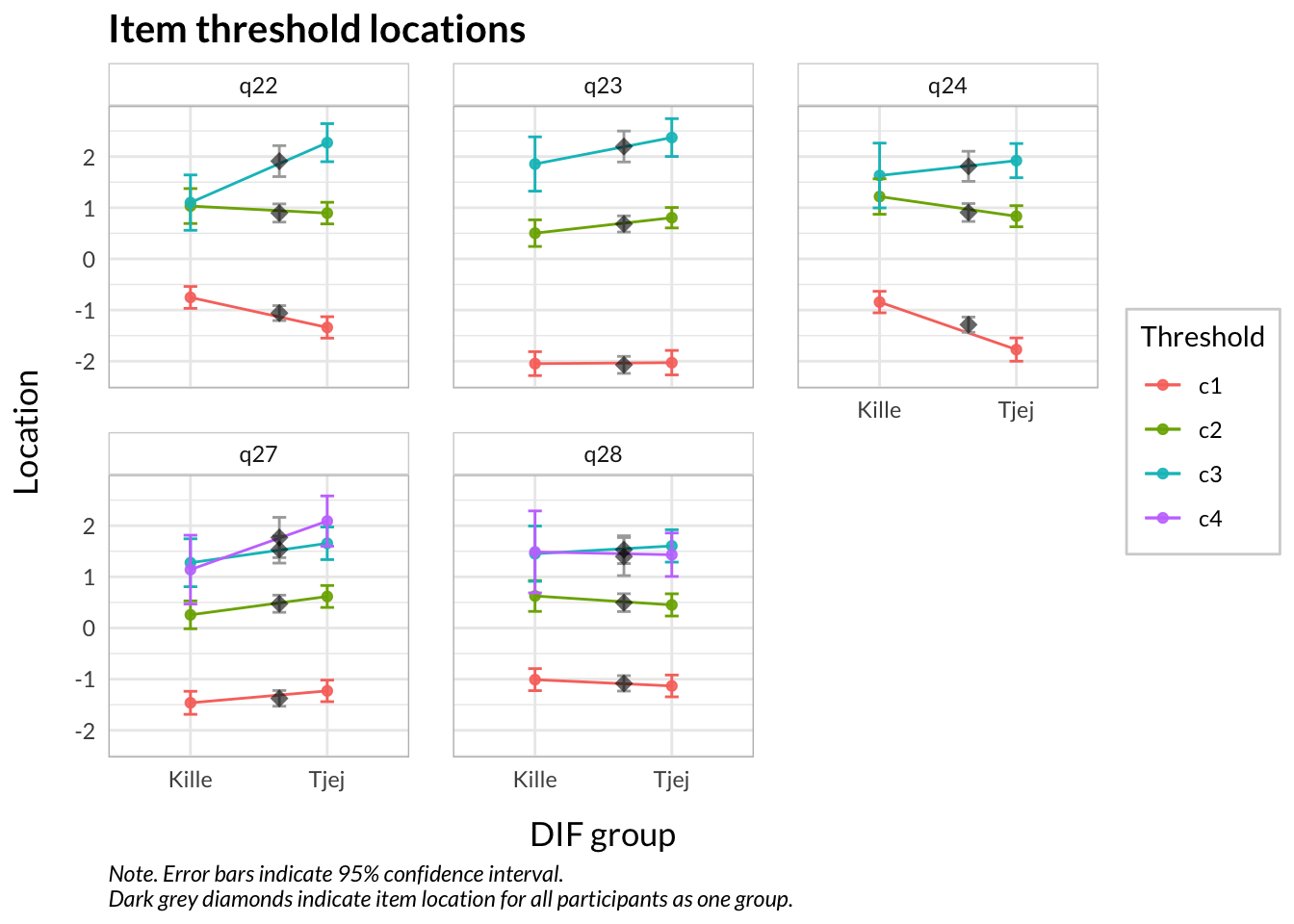
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
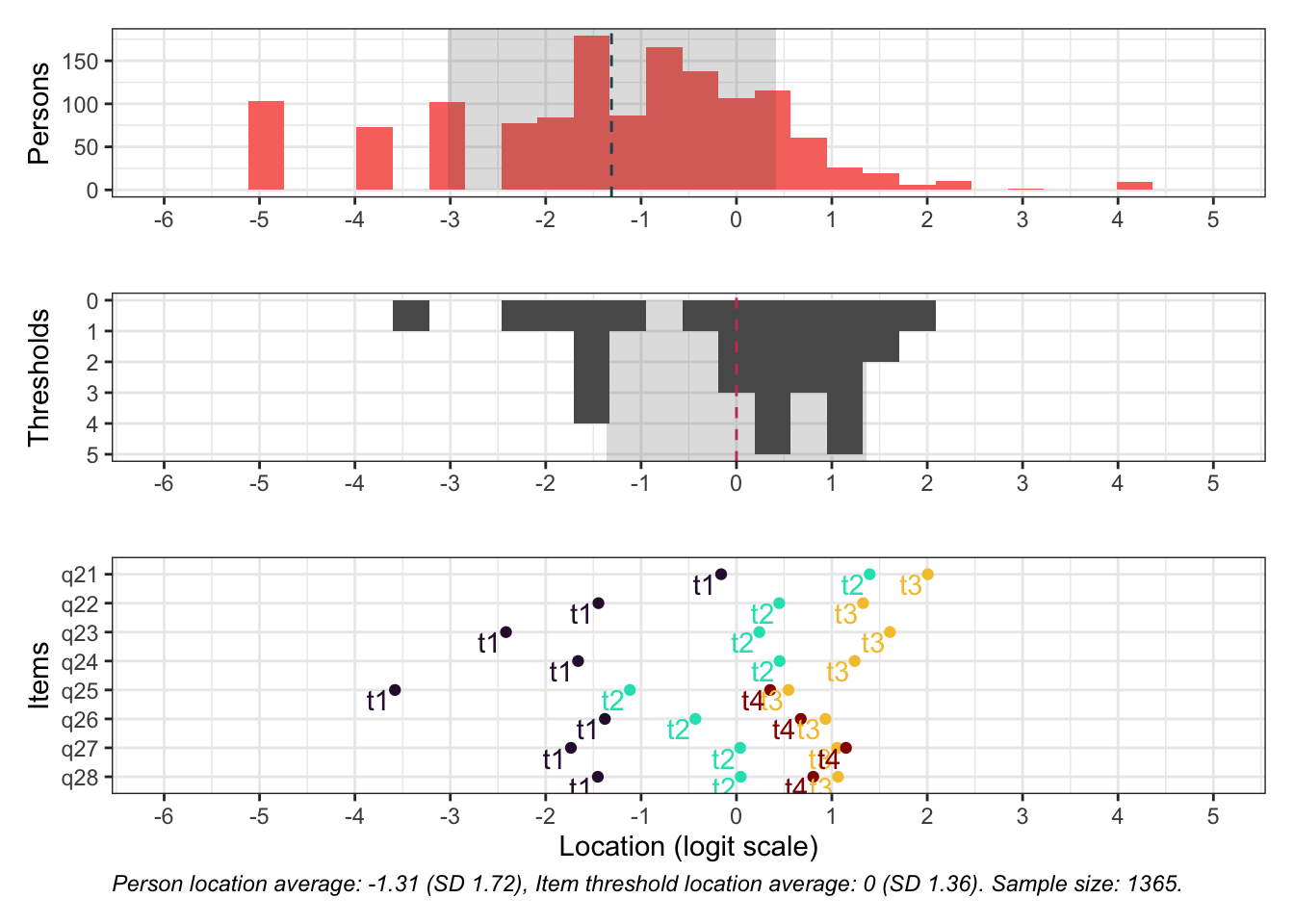
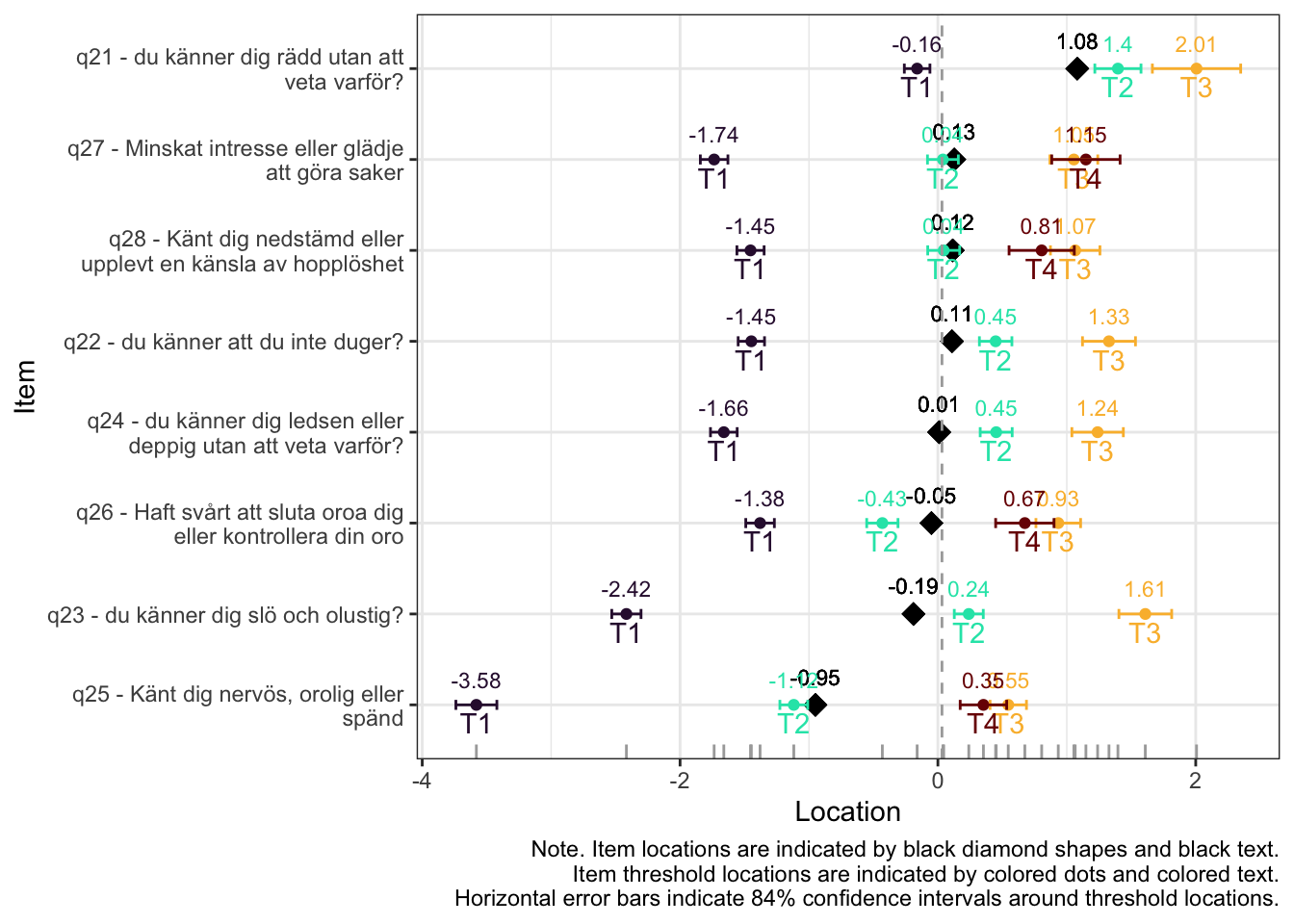
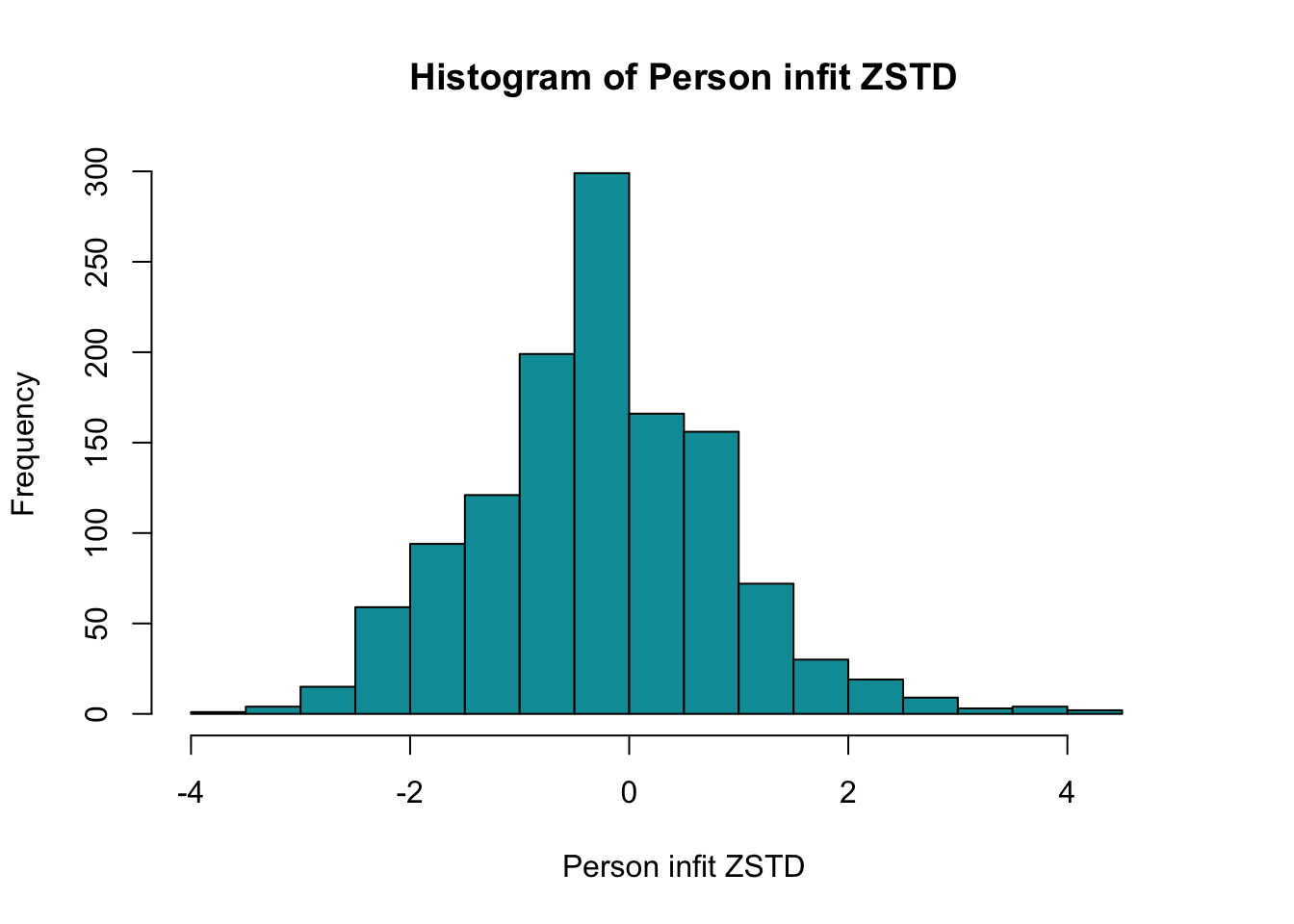
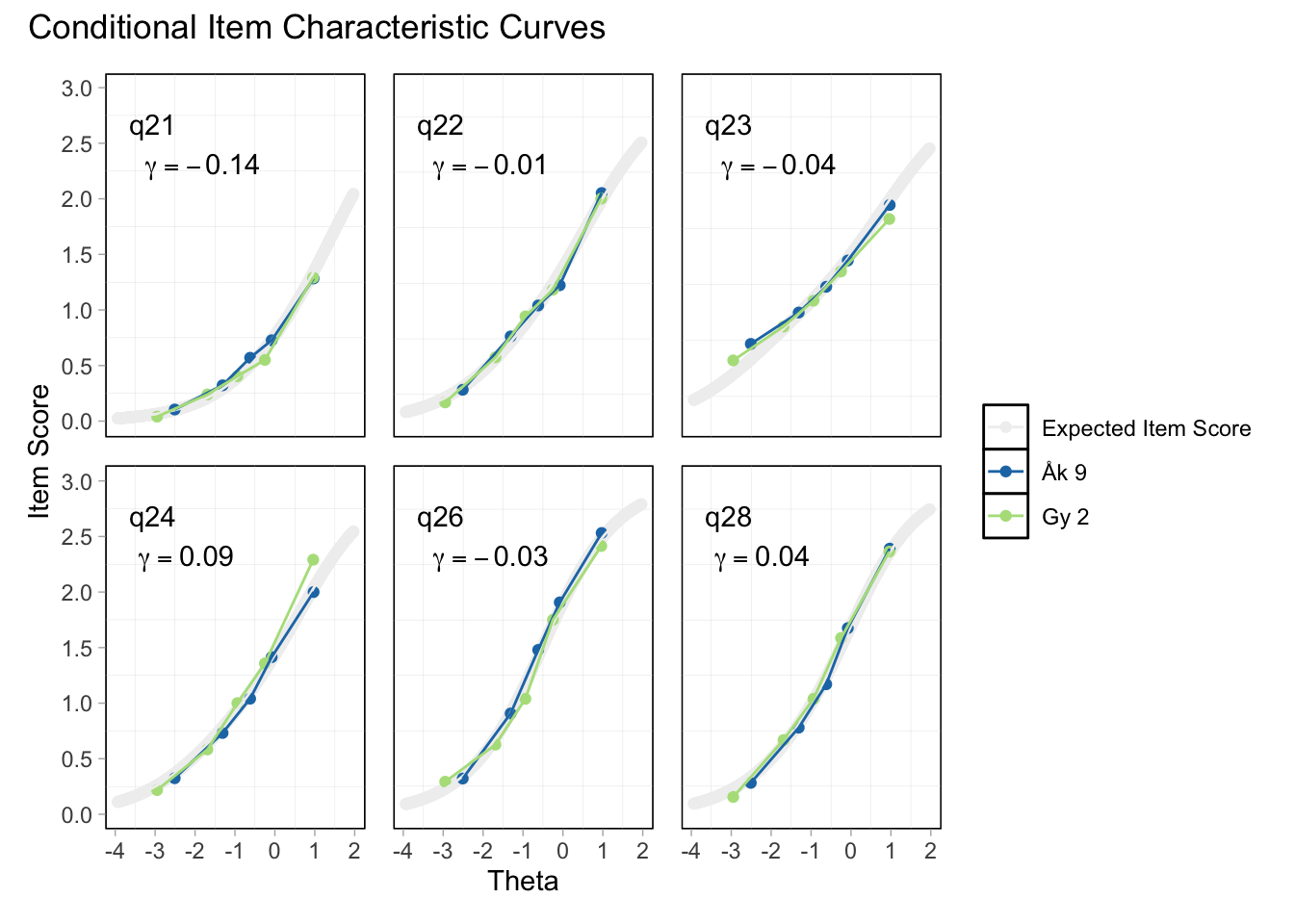
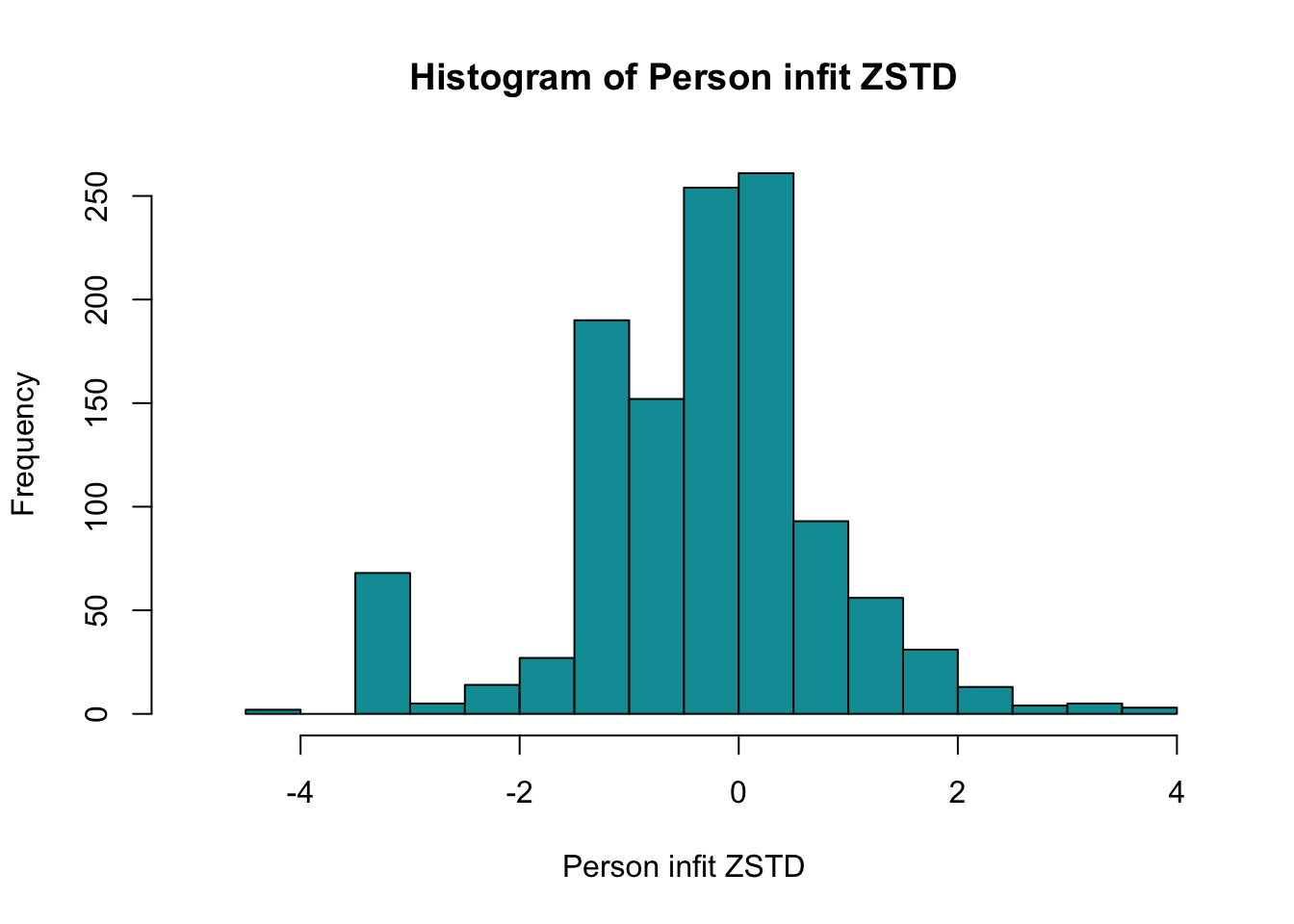
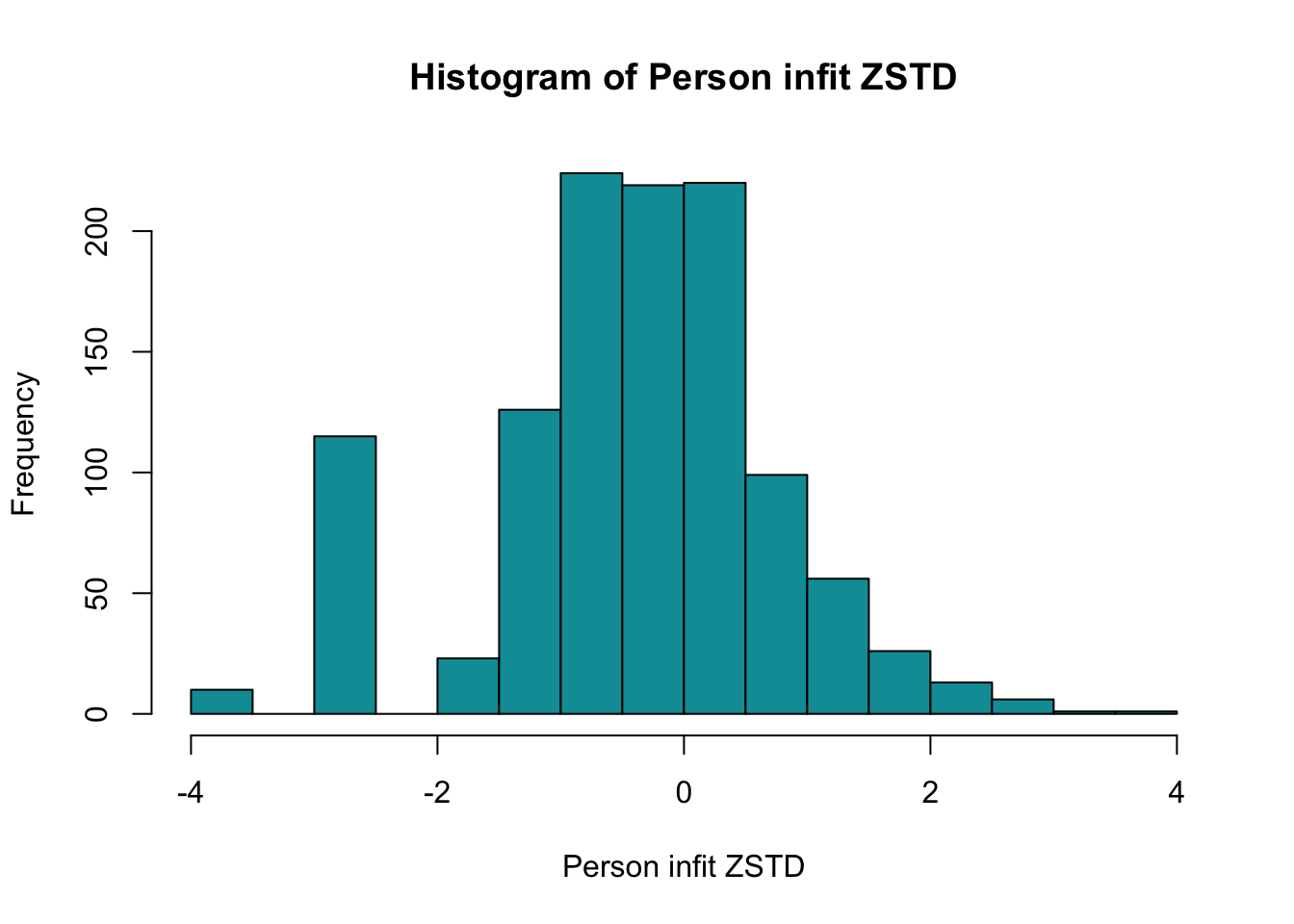
Ingen underfit, alla items verkar höra till samma/närliggande konstrukt
Overfit på q28 och q26 - dessa är “core items” för depression respektive ångest i PHQ och GAD-enkäterna
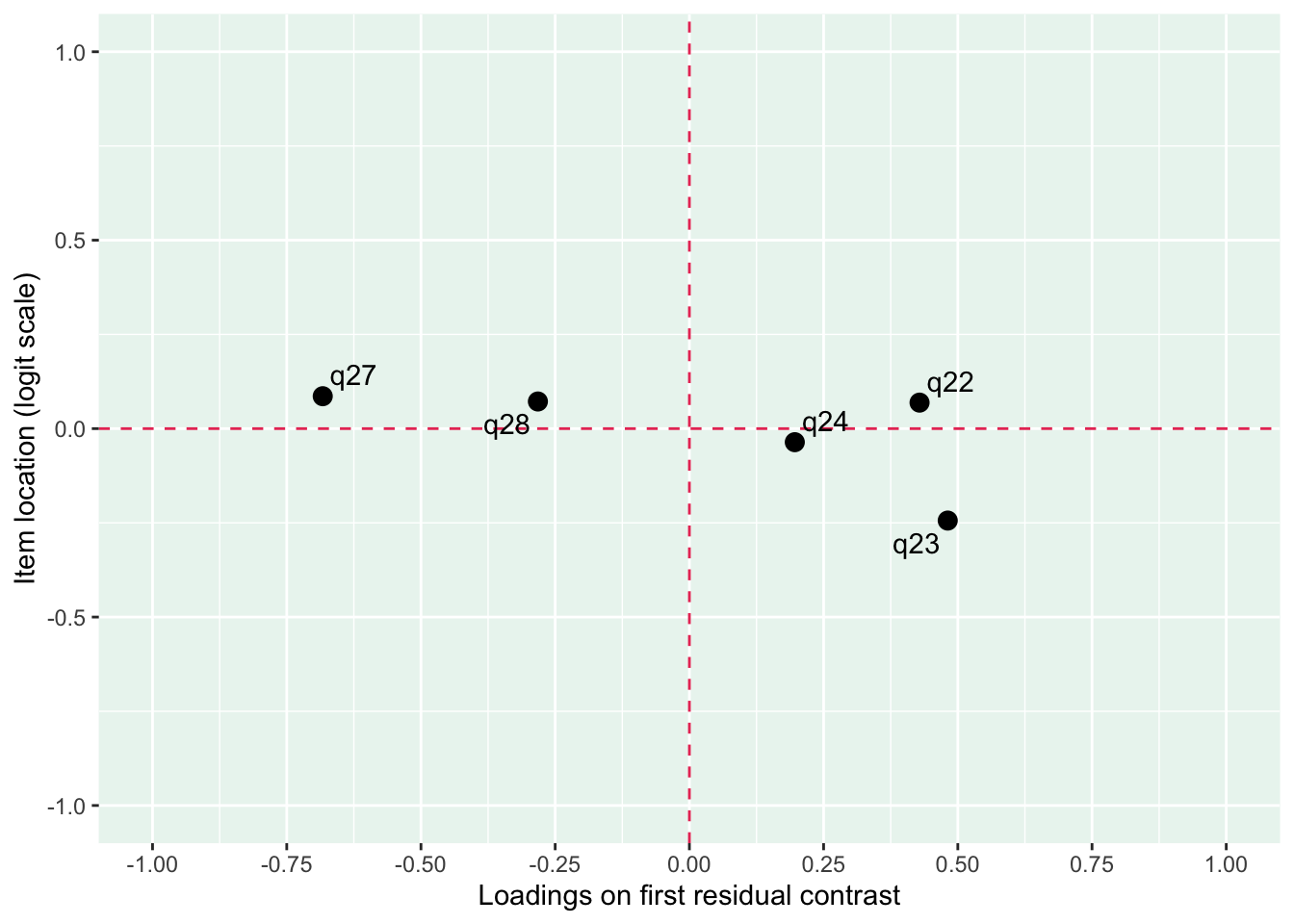
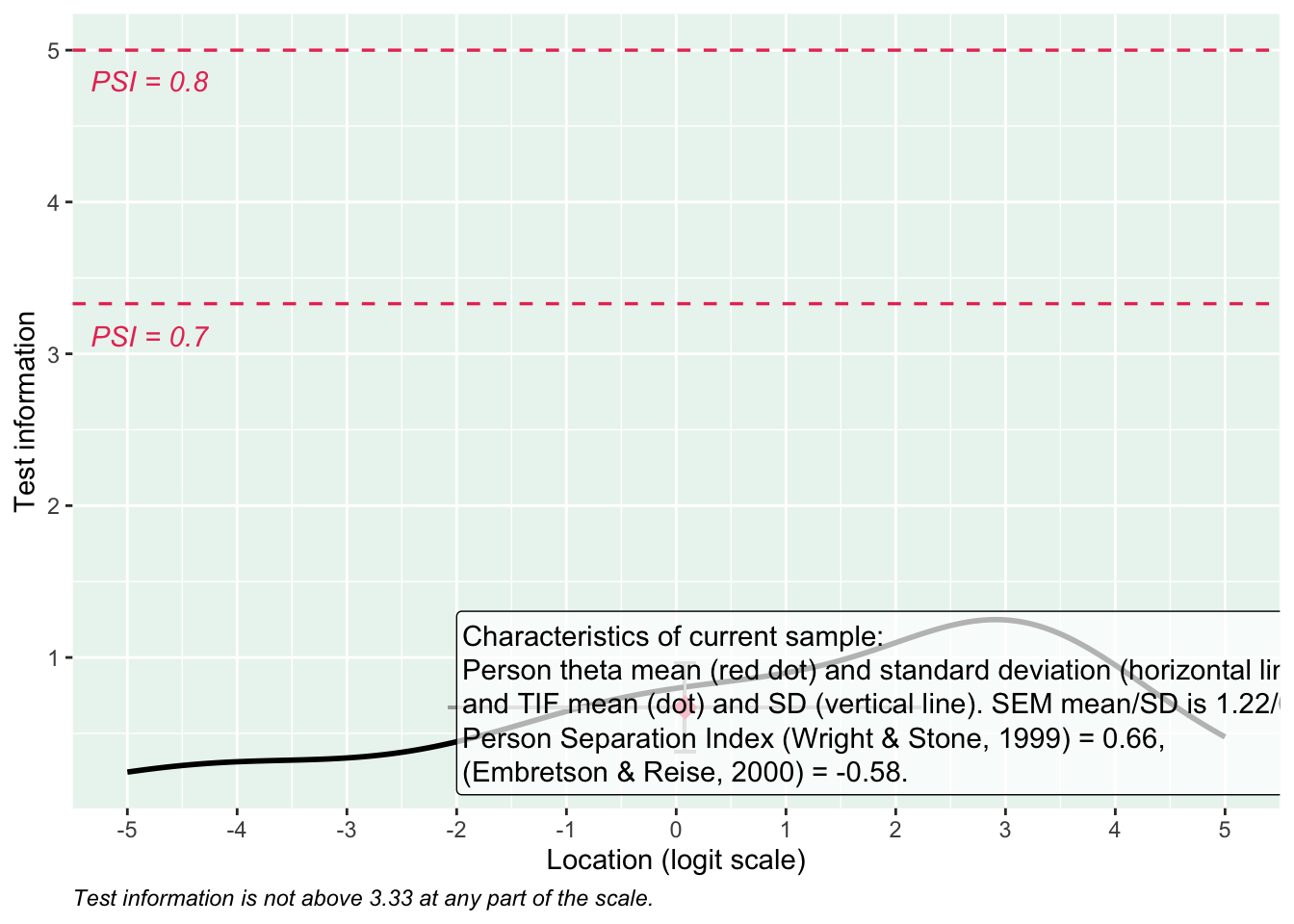
PCA 1.82
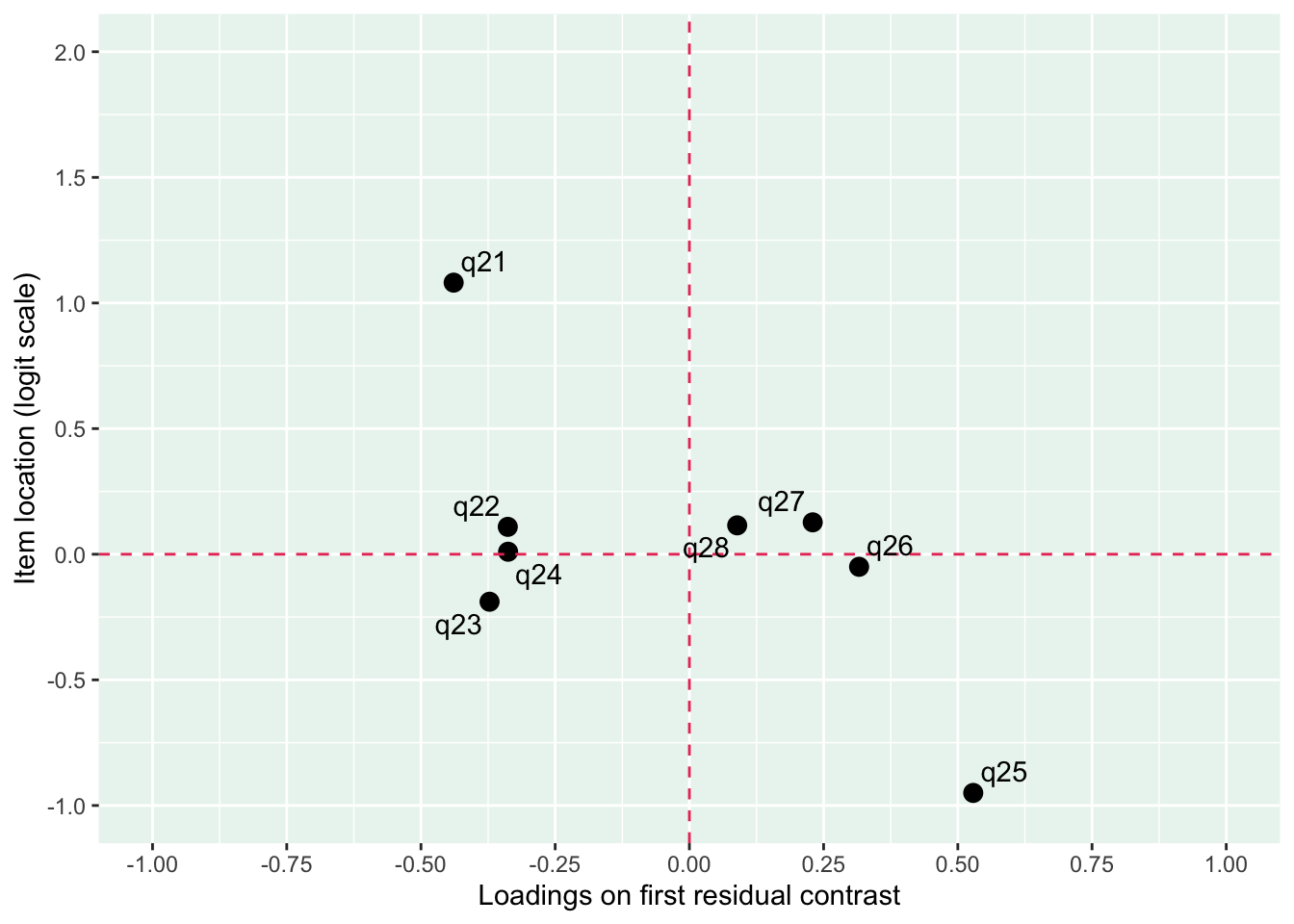
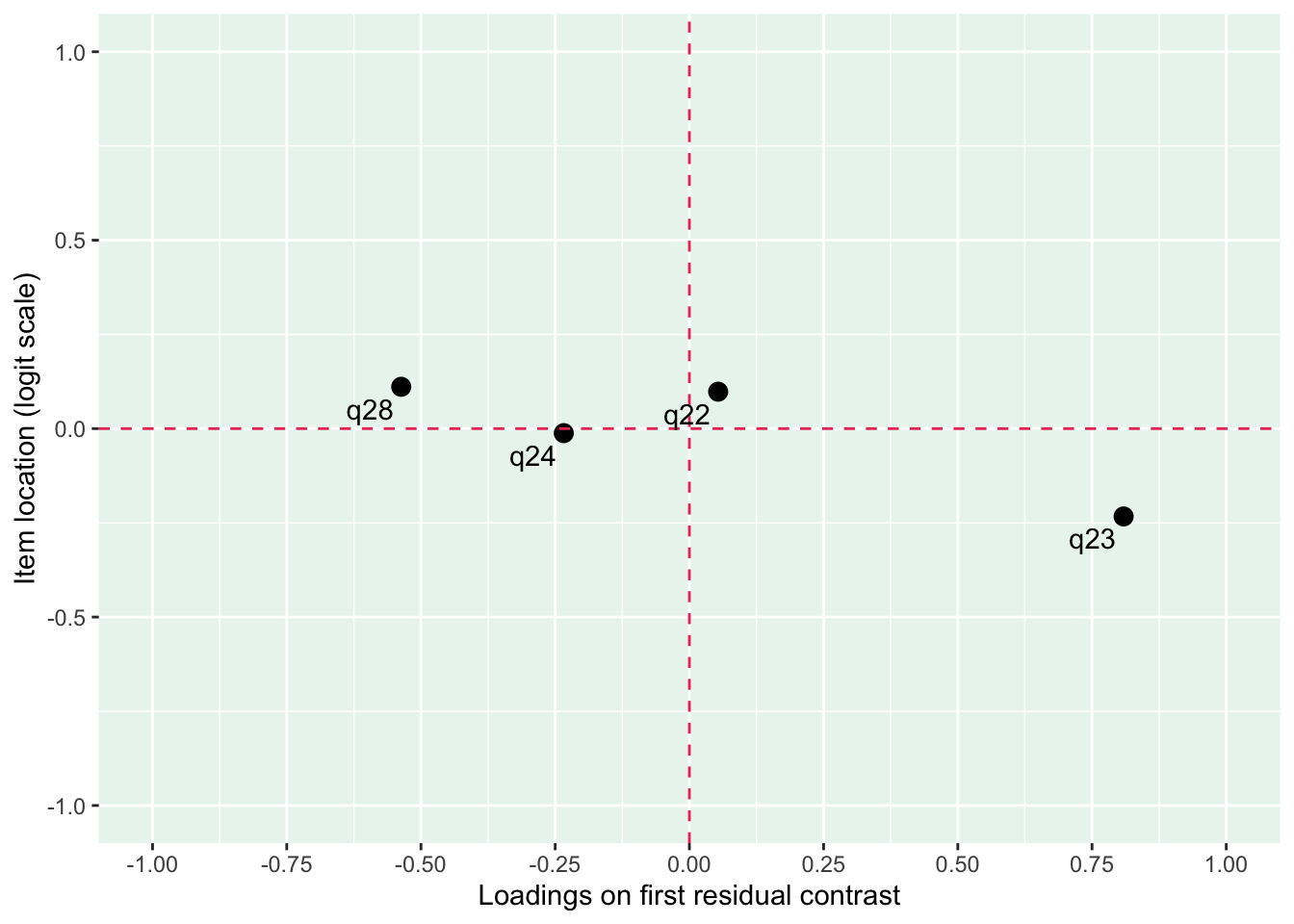
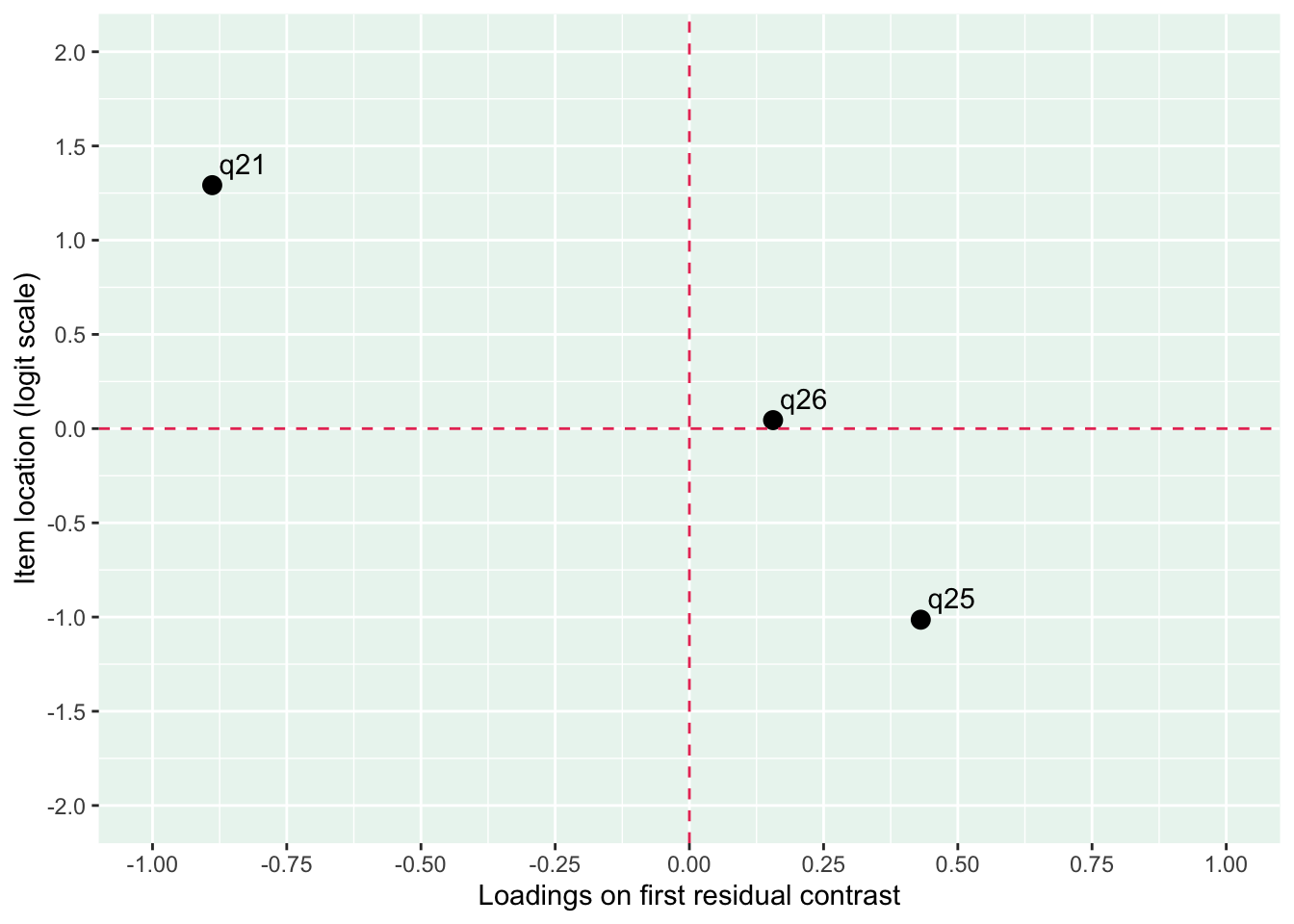
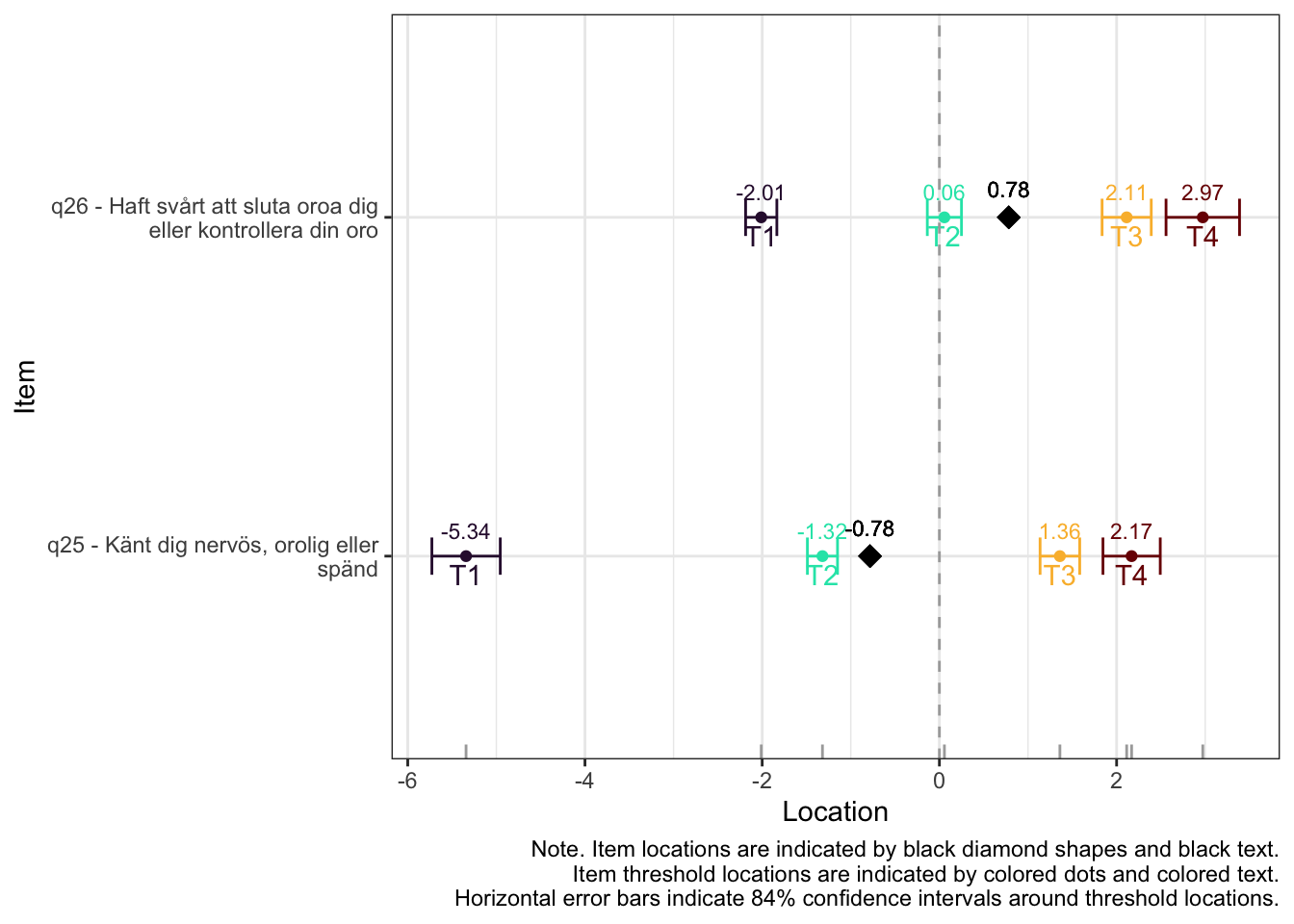
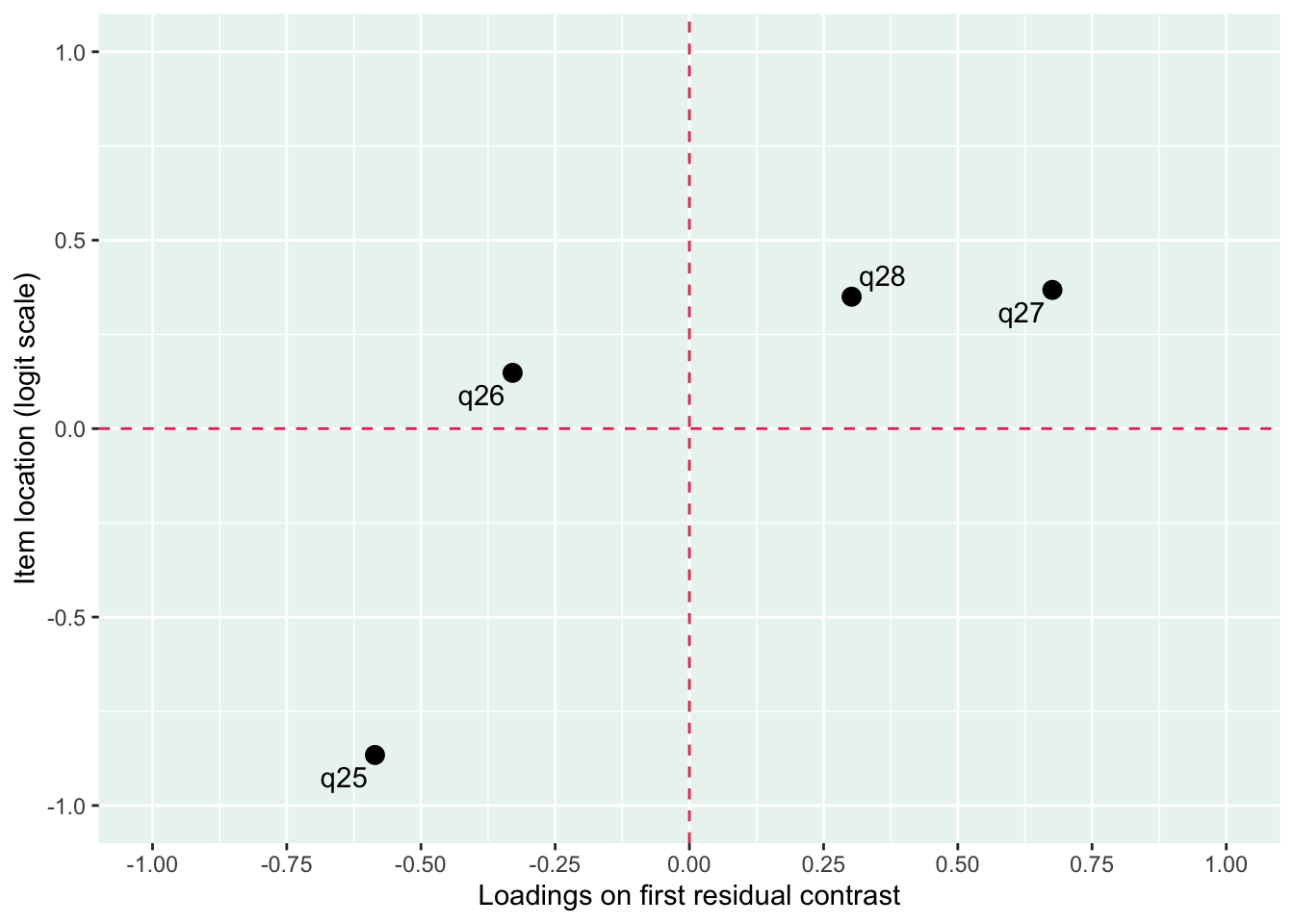
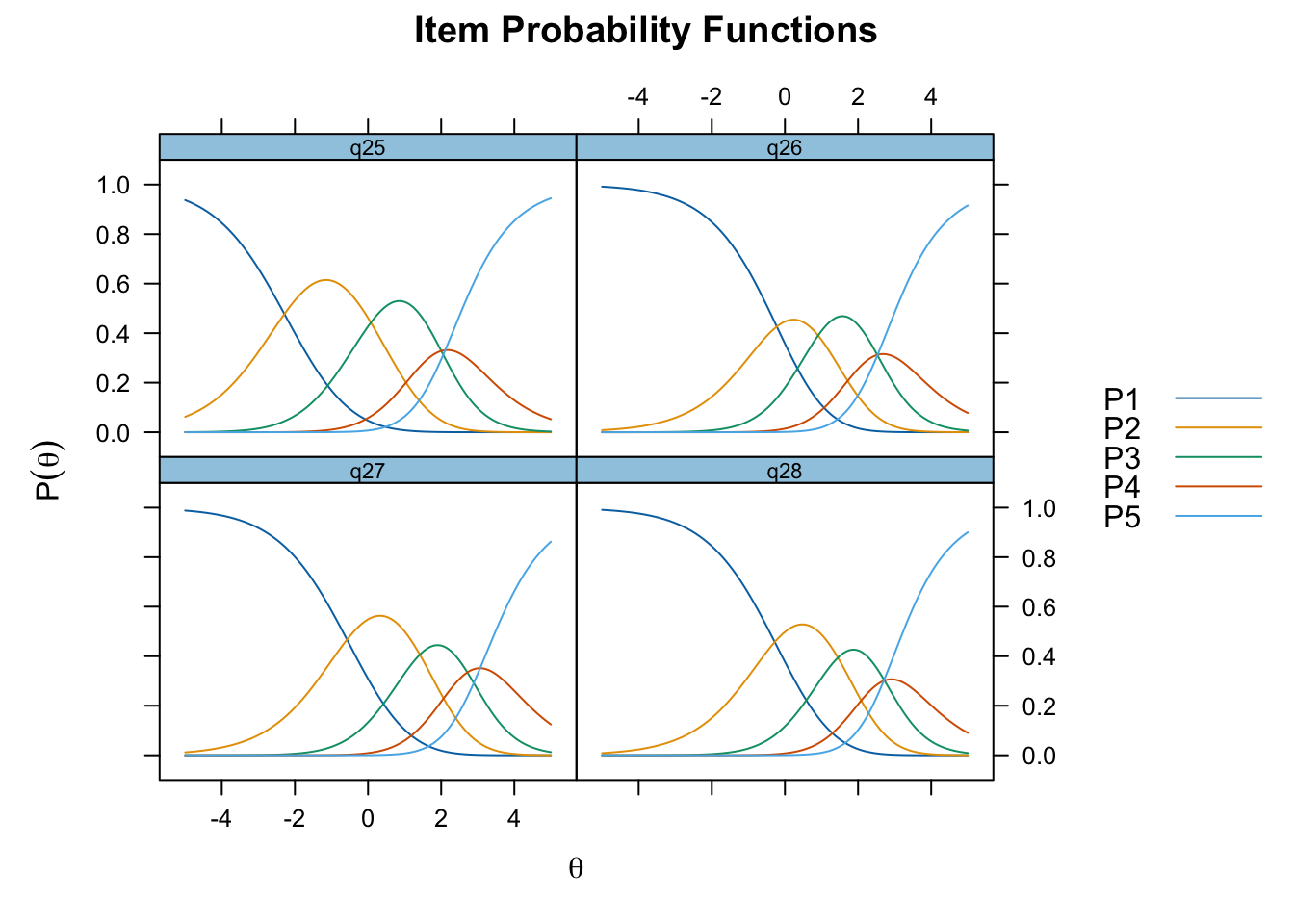
Lokalt beroende främst mellan q26 “oro” och q25 “nervös, orolig, spänd”, samt q27 “minskat intresse” och q28 “nedstämd och hopplöst”
dessa par är PHQ-2 (depression) och GAD-2 (oro/ångest), så de förväntas vara lika varandra, och minst en publicerad artikel har identifierat PHQ-items som för lika varandra när de används i PHQ-9, d.v.s. i kontexten av items som mäter något bredare än bara depression.
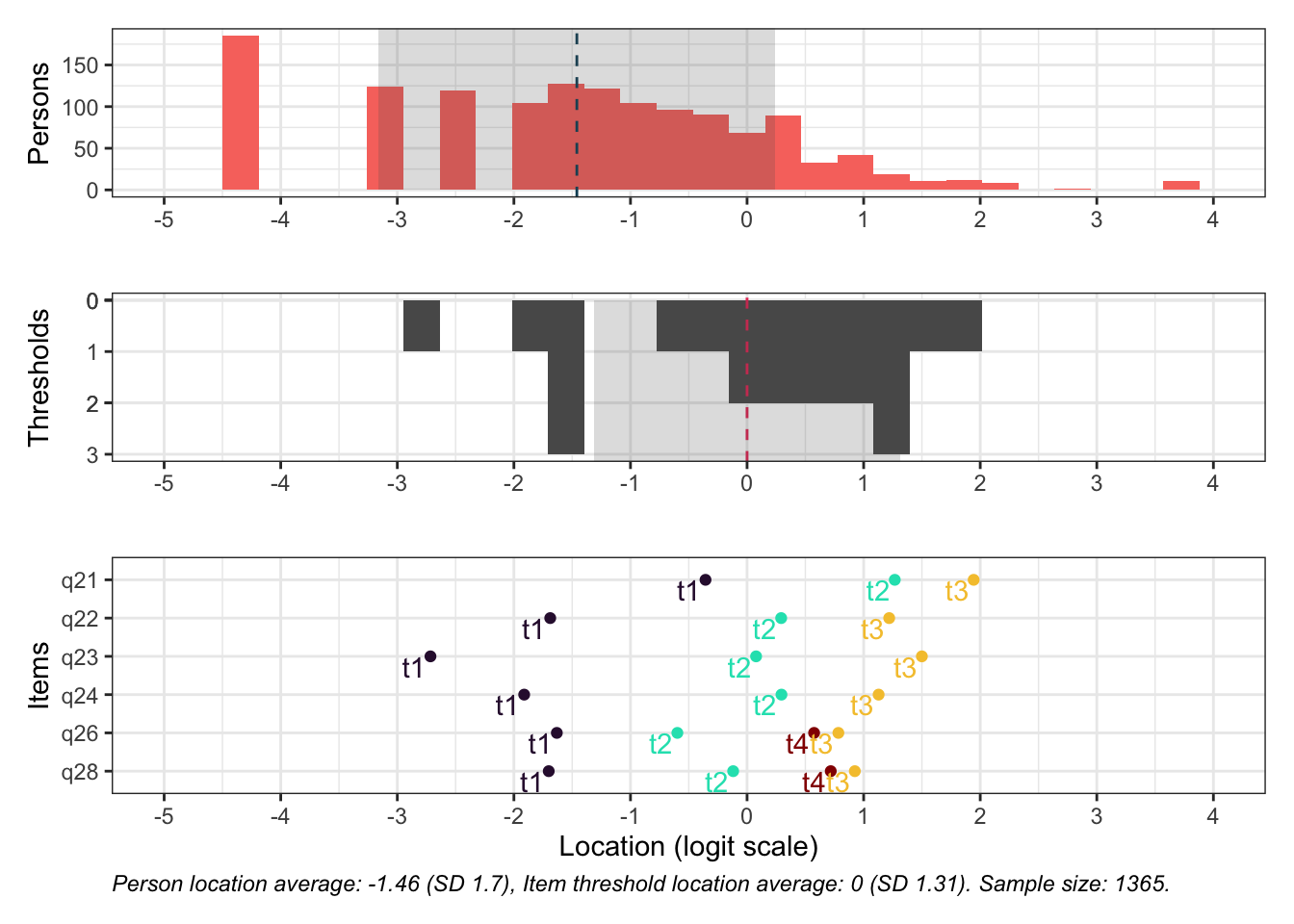
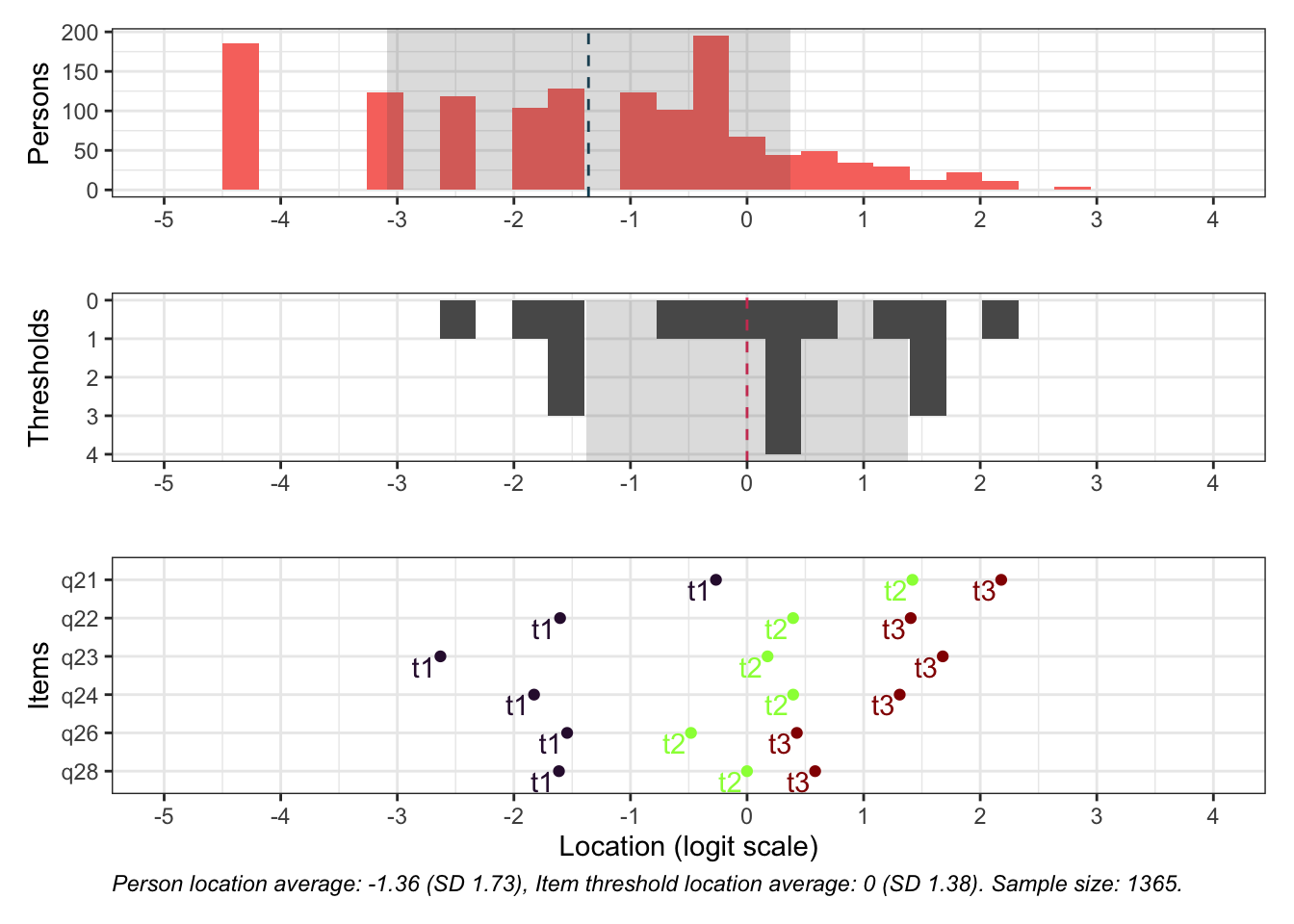
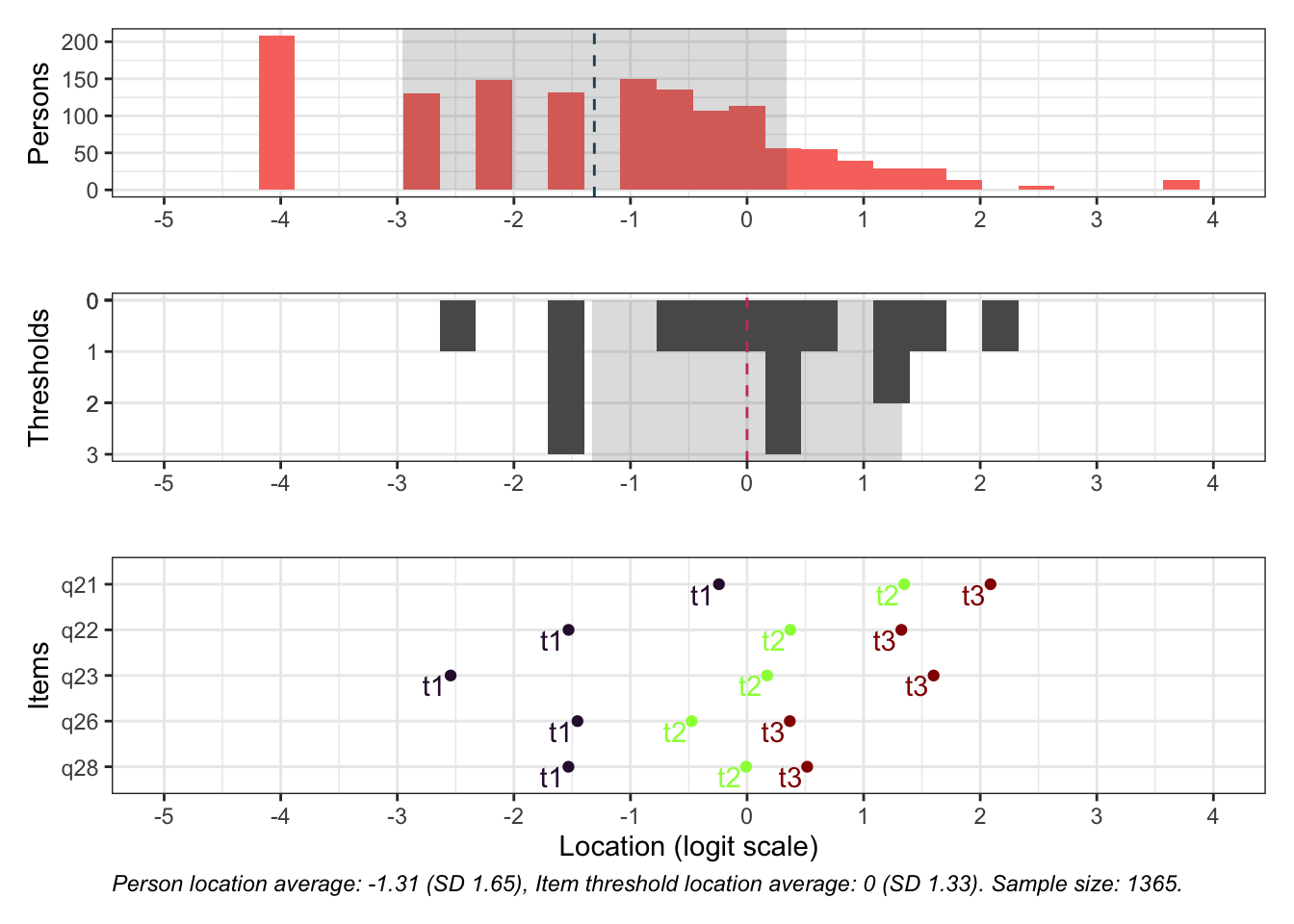
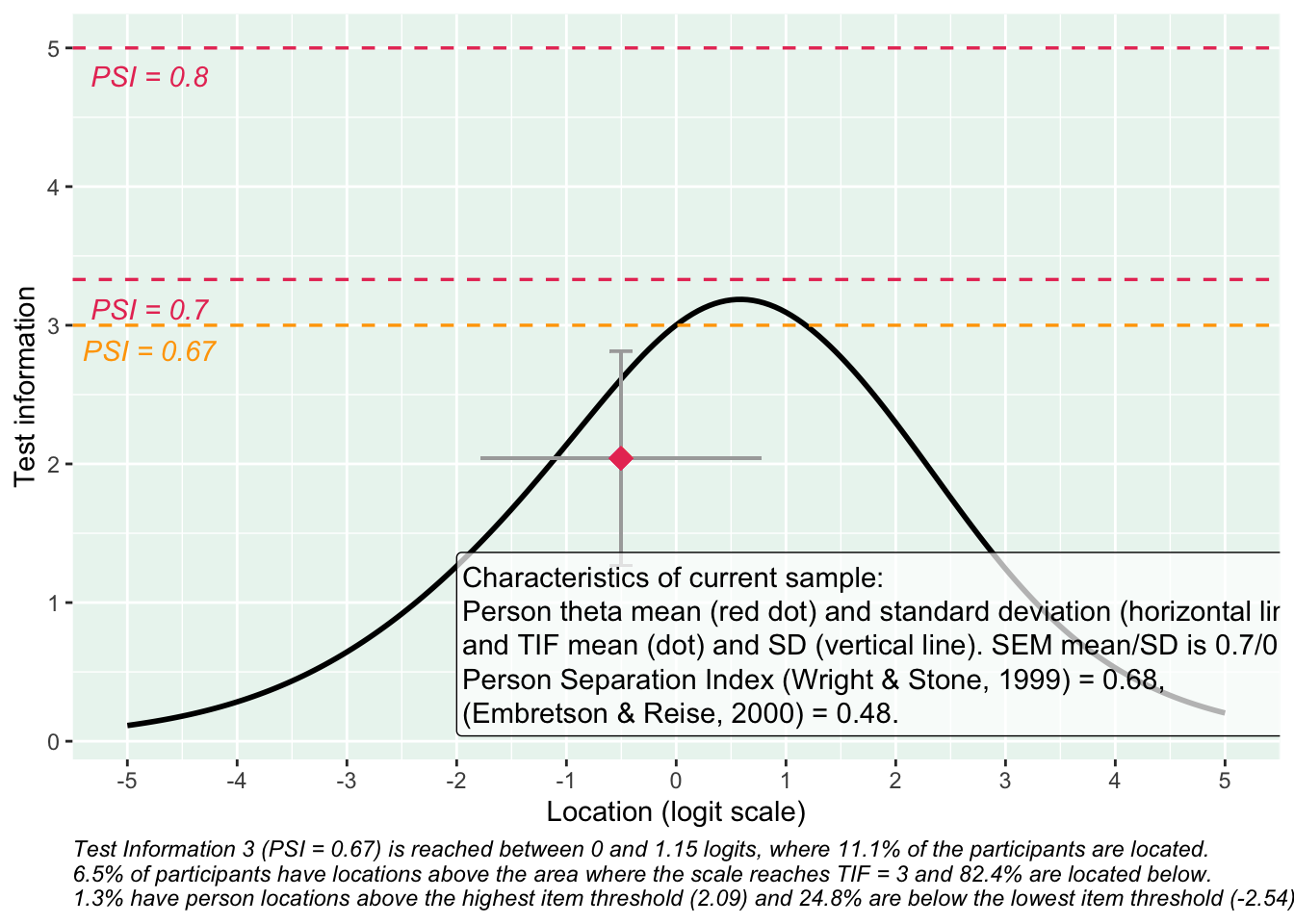
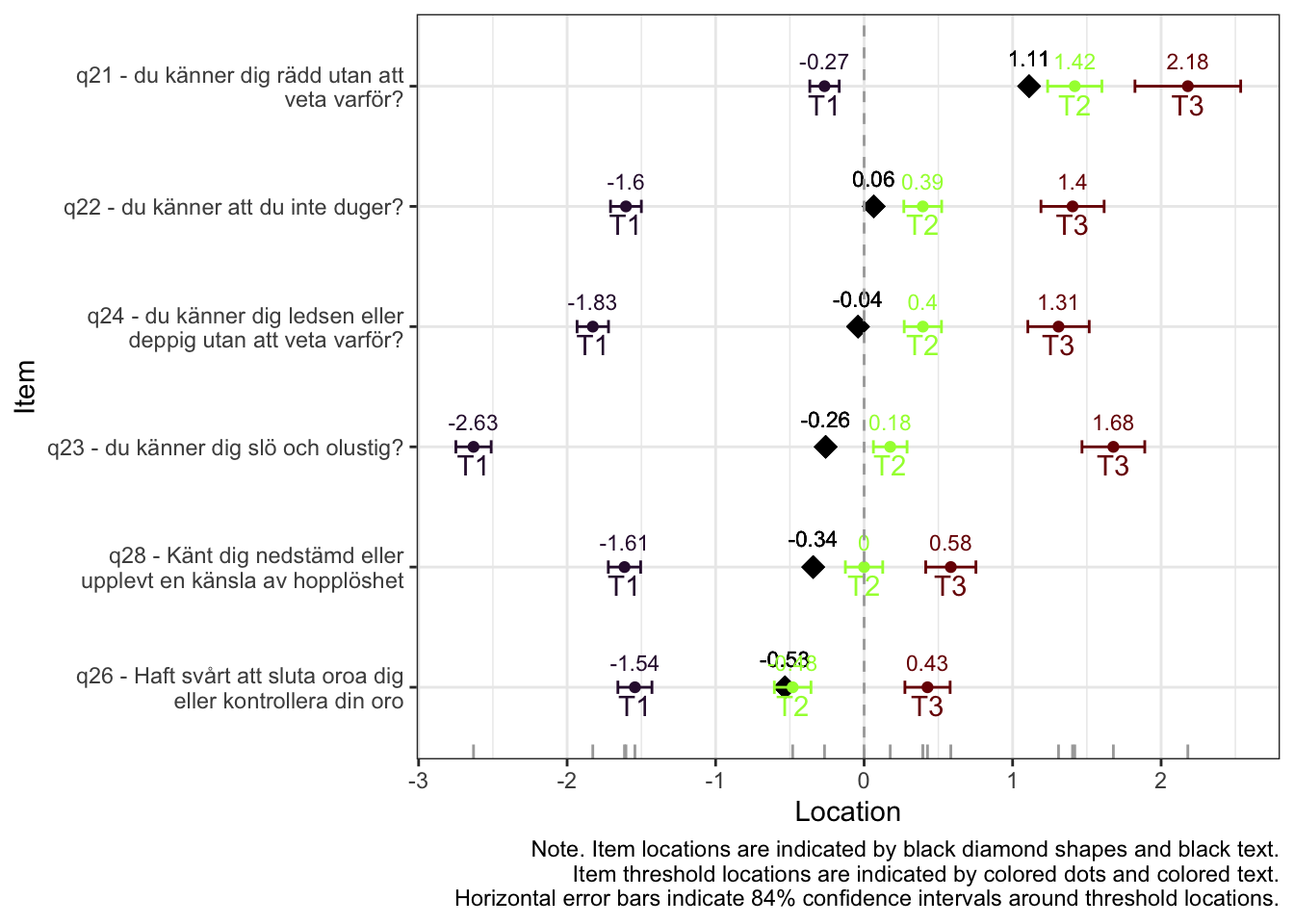
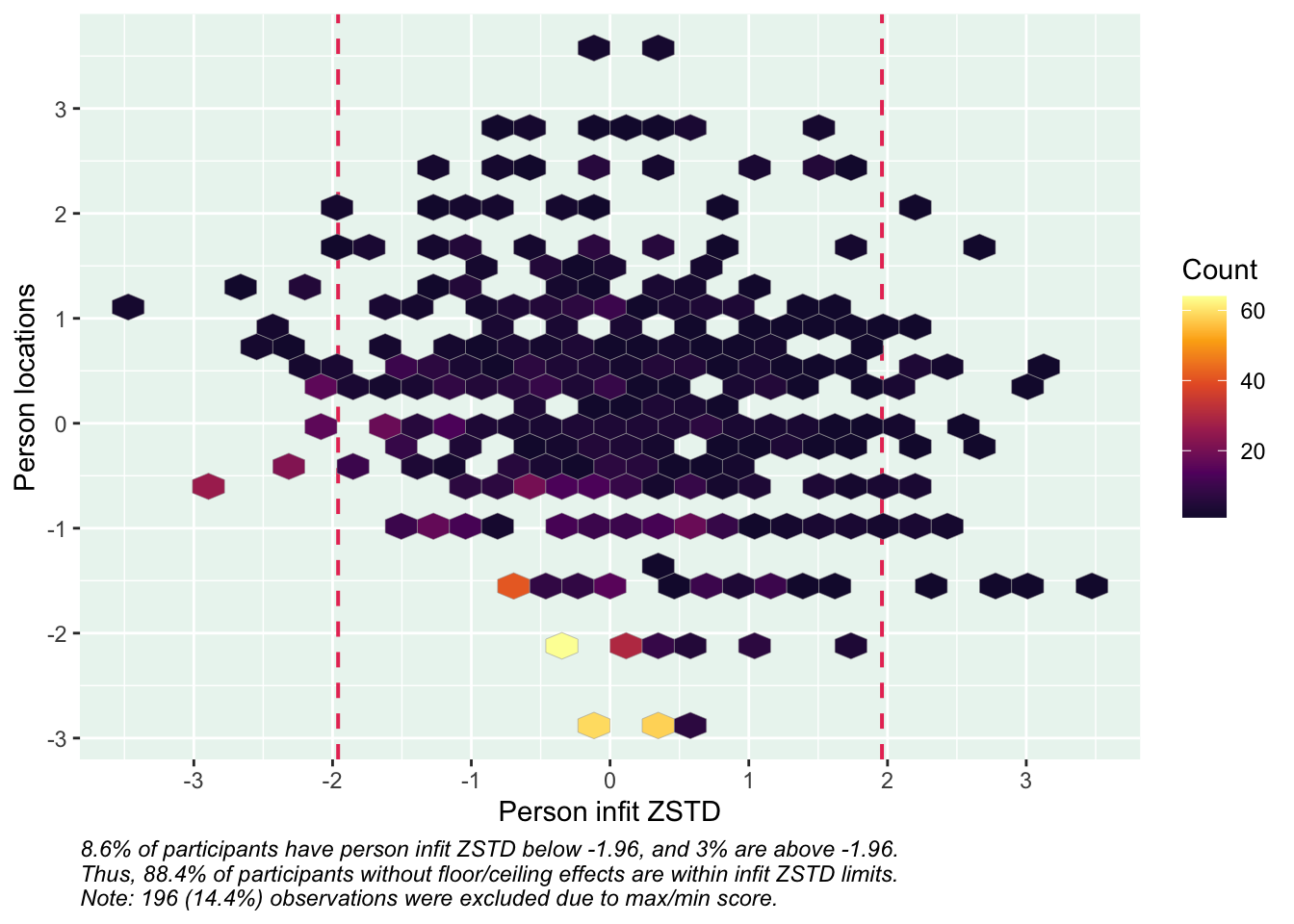
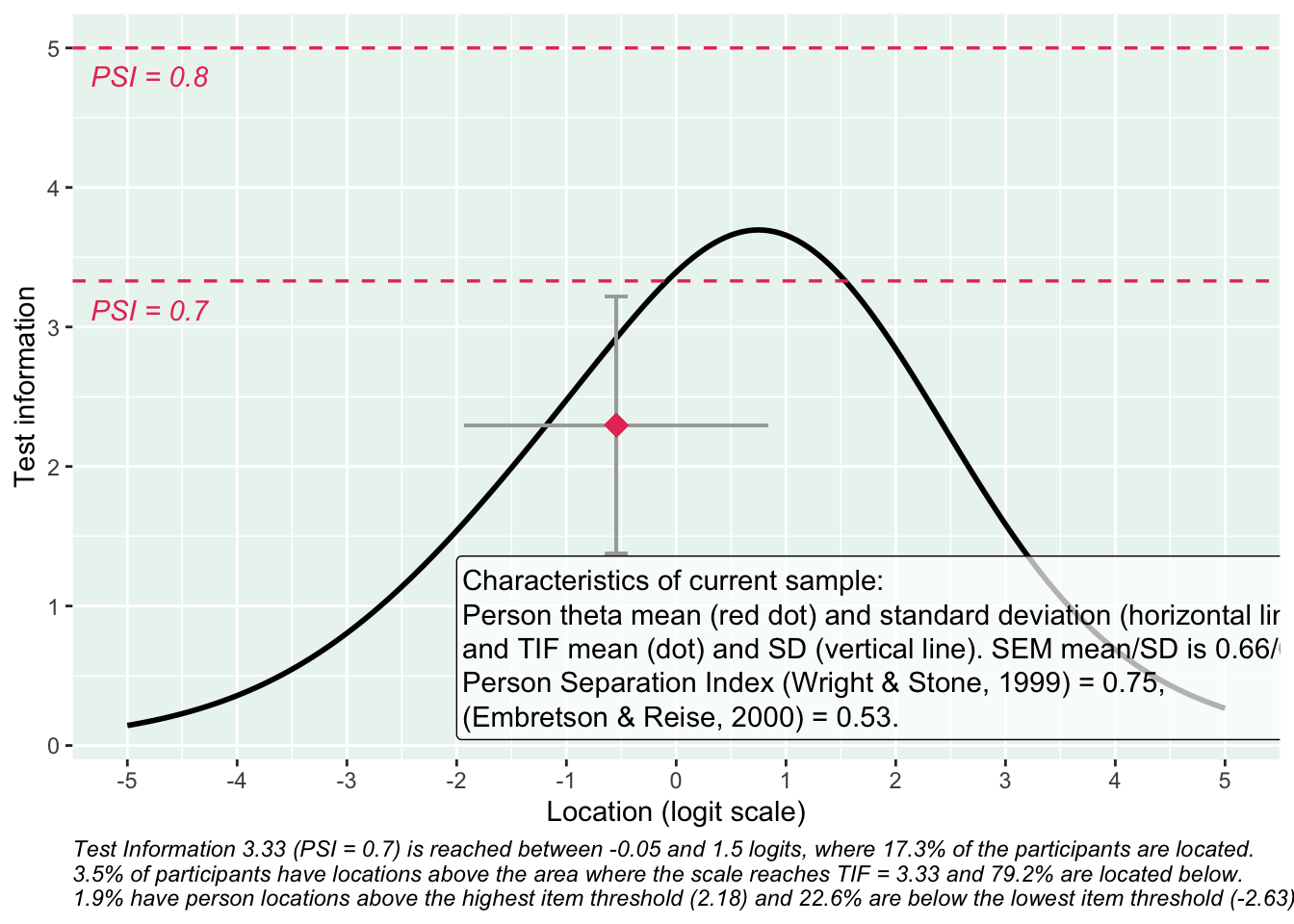
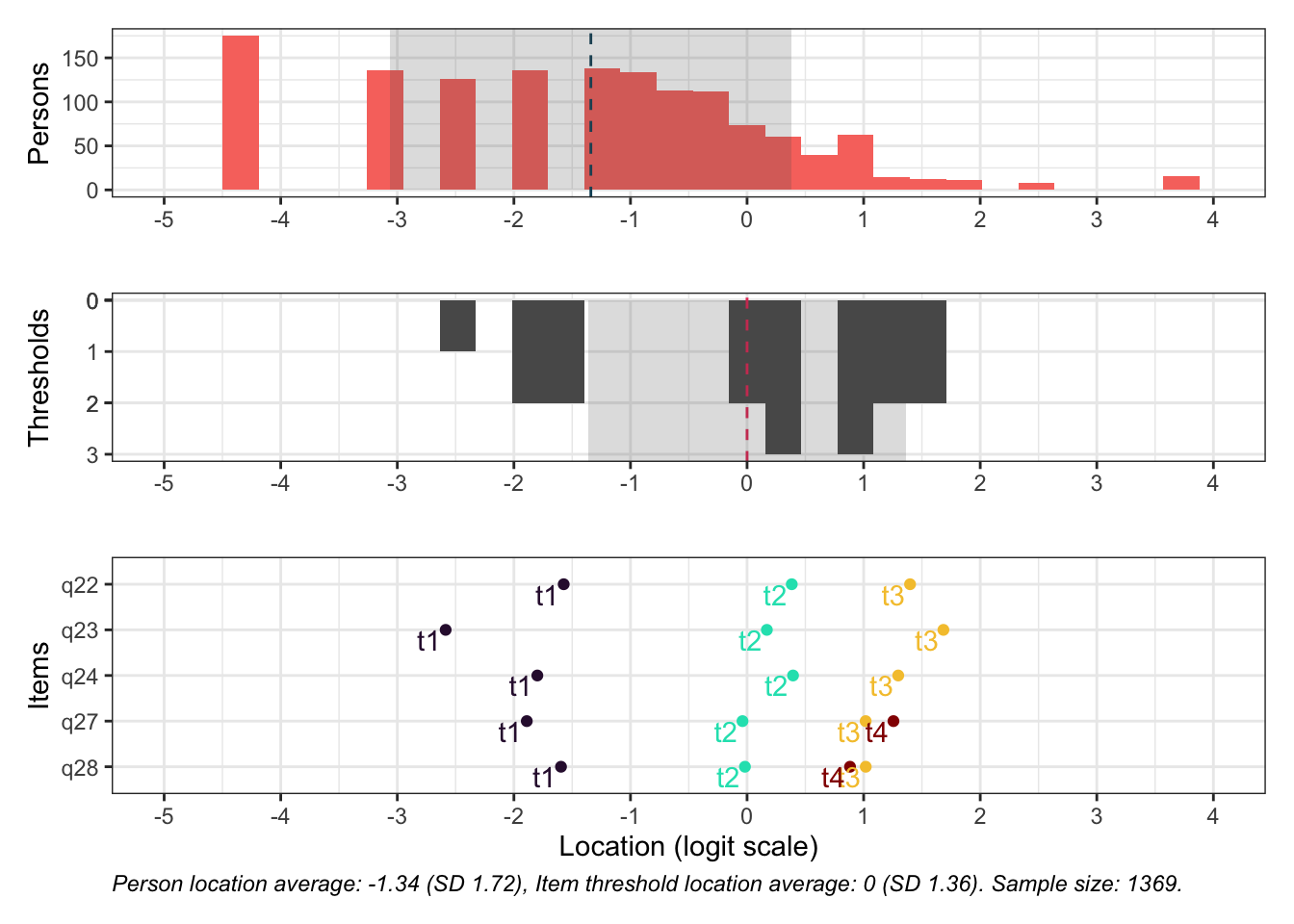
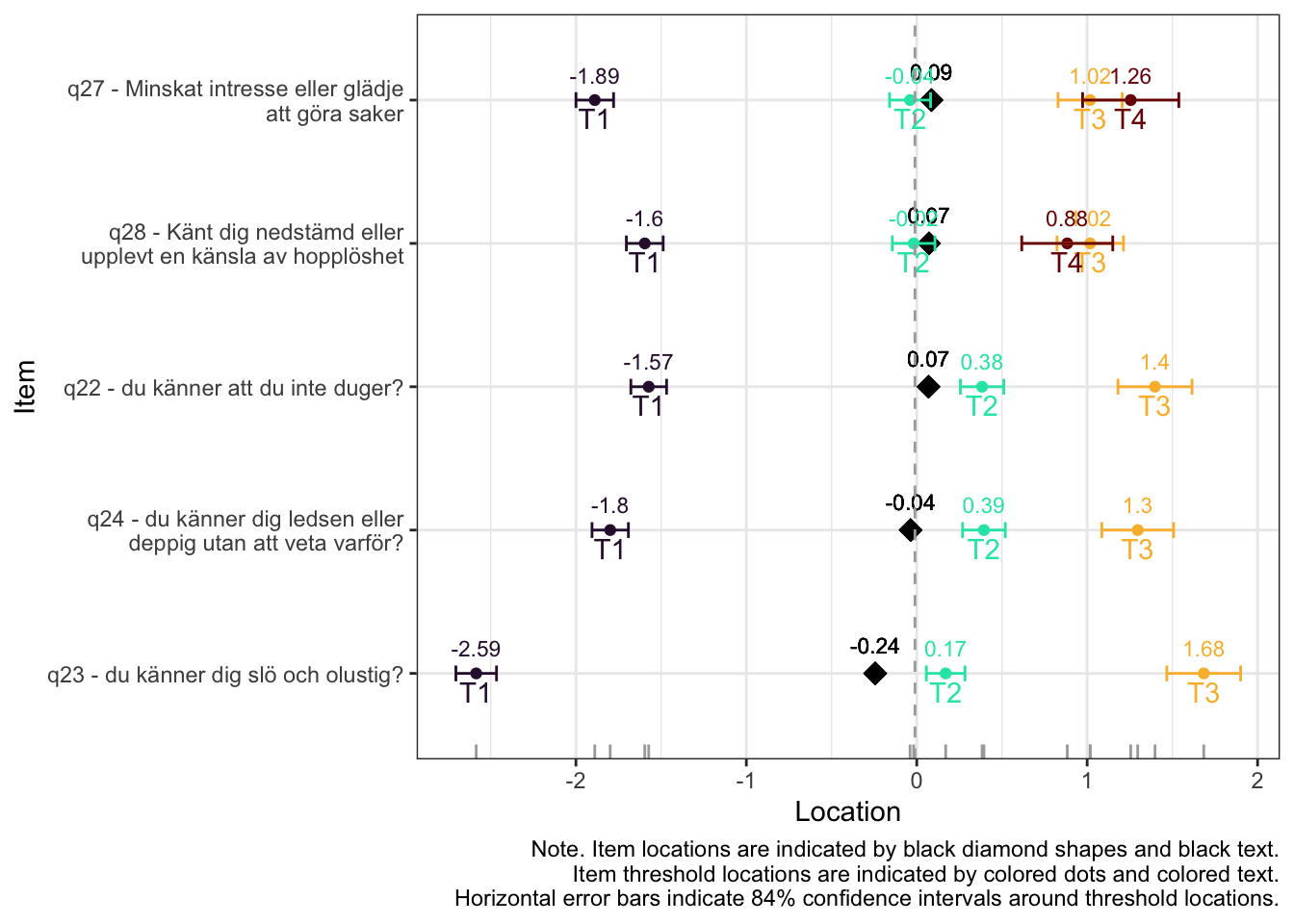
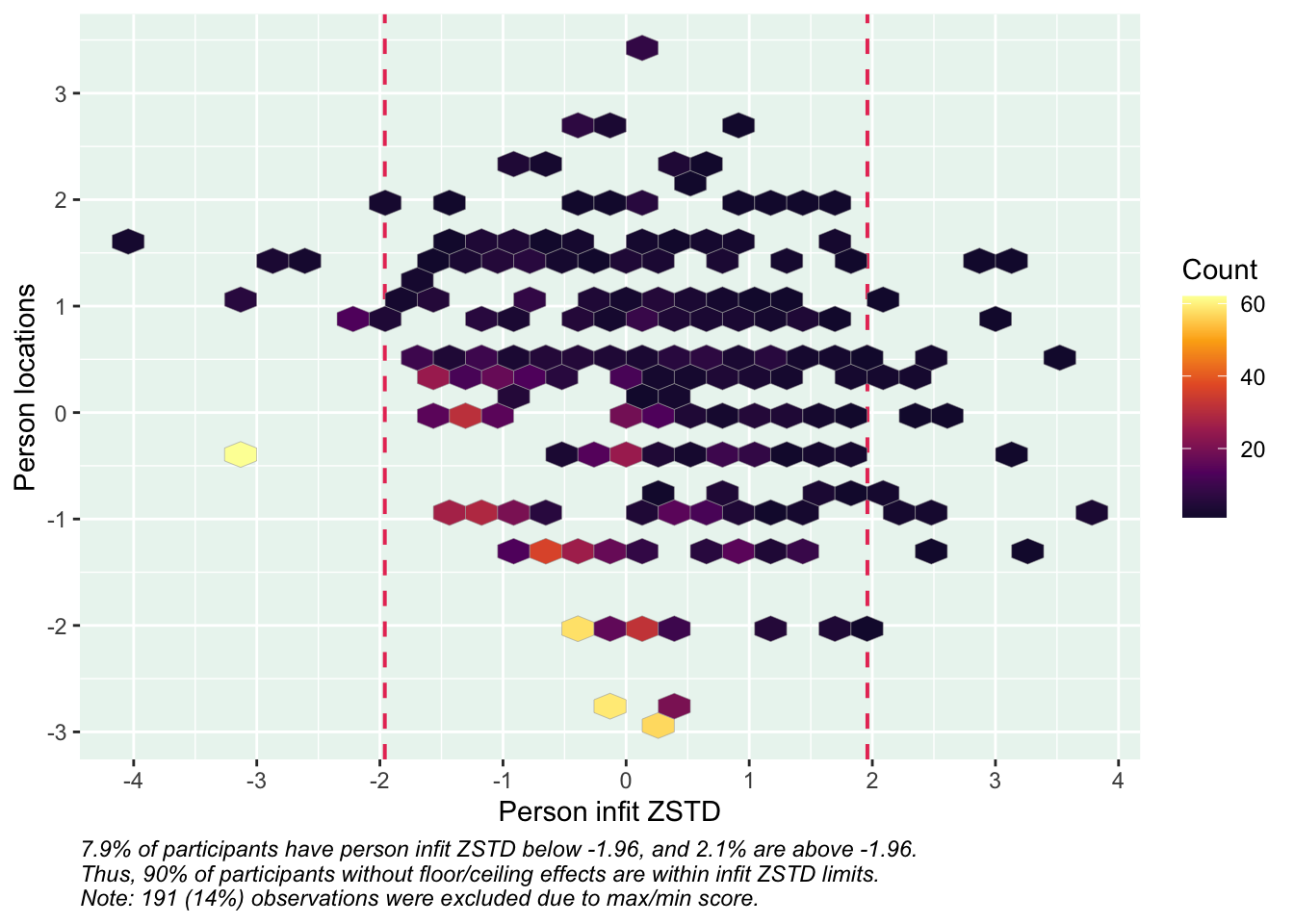
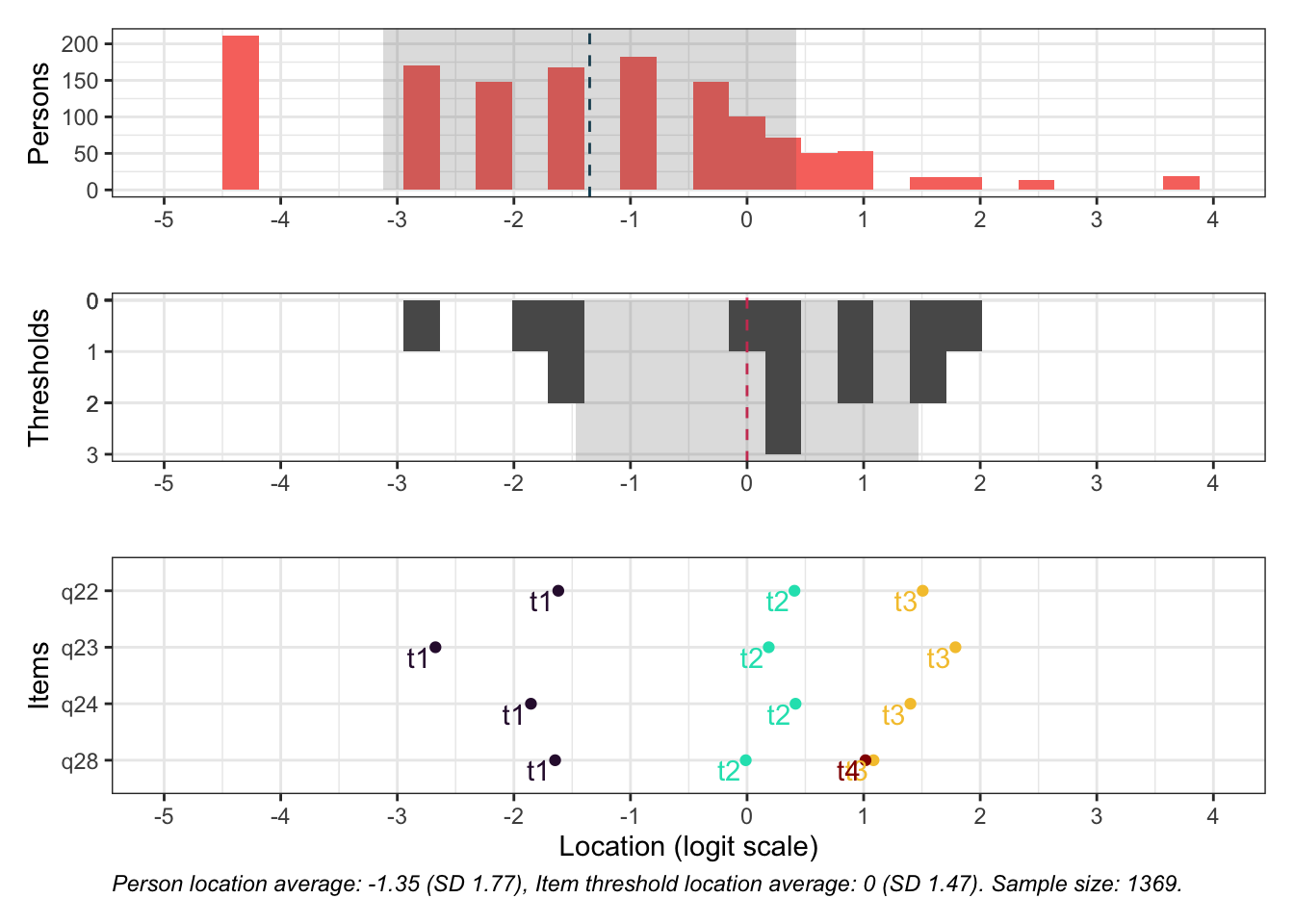
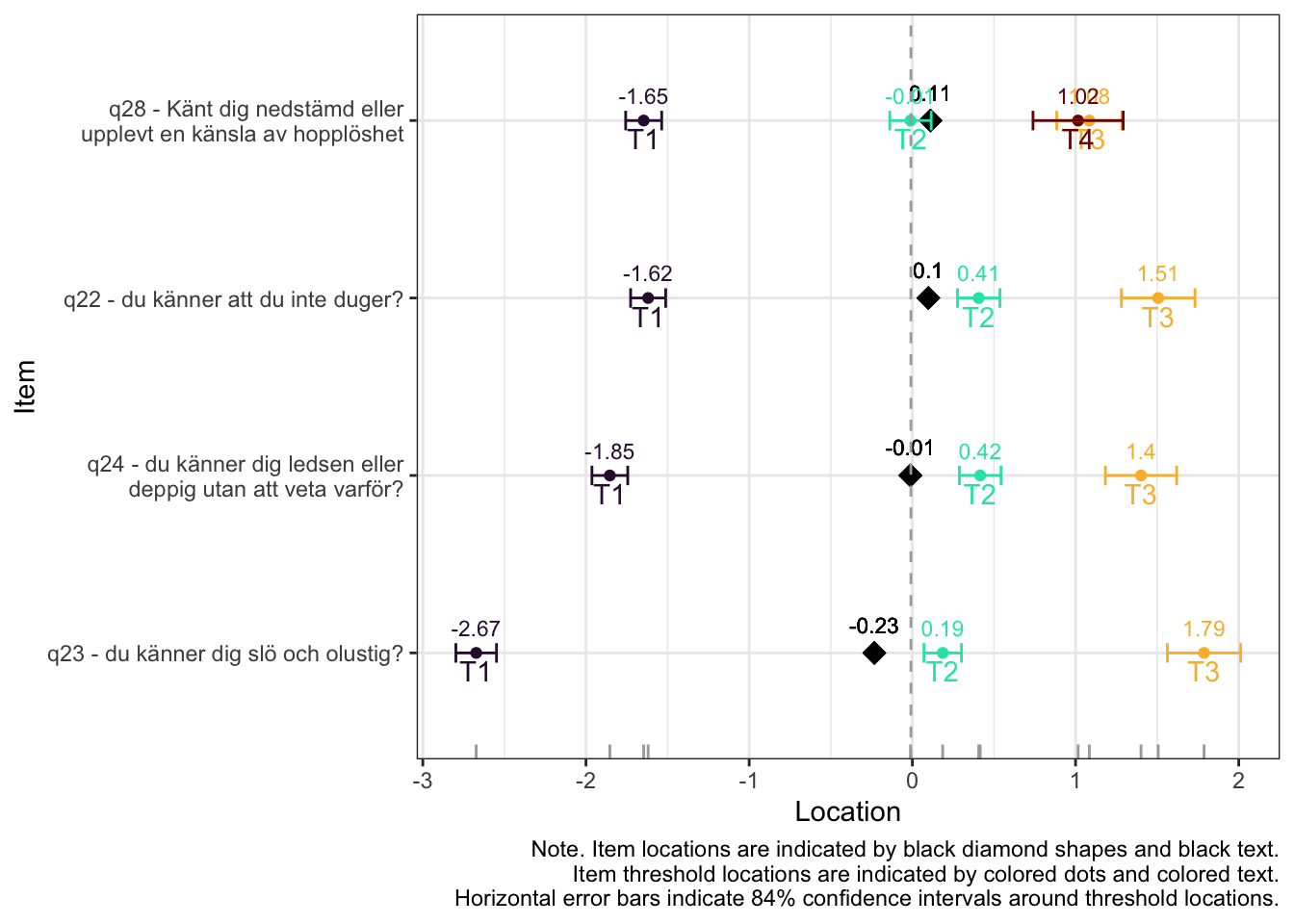
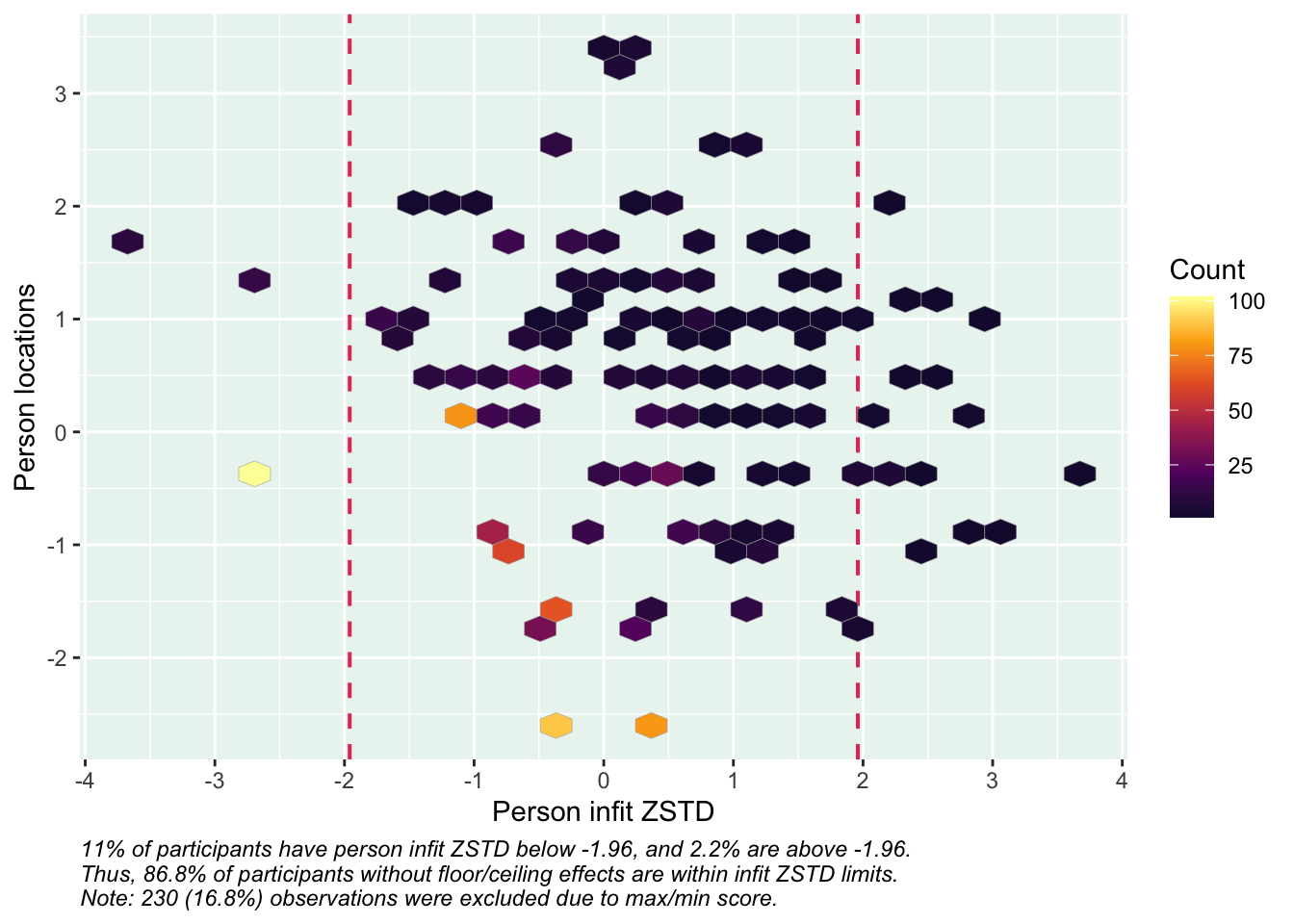
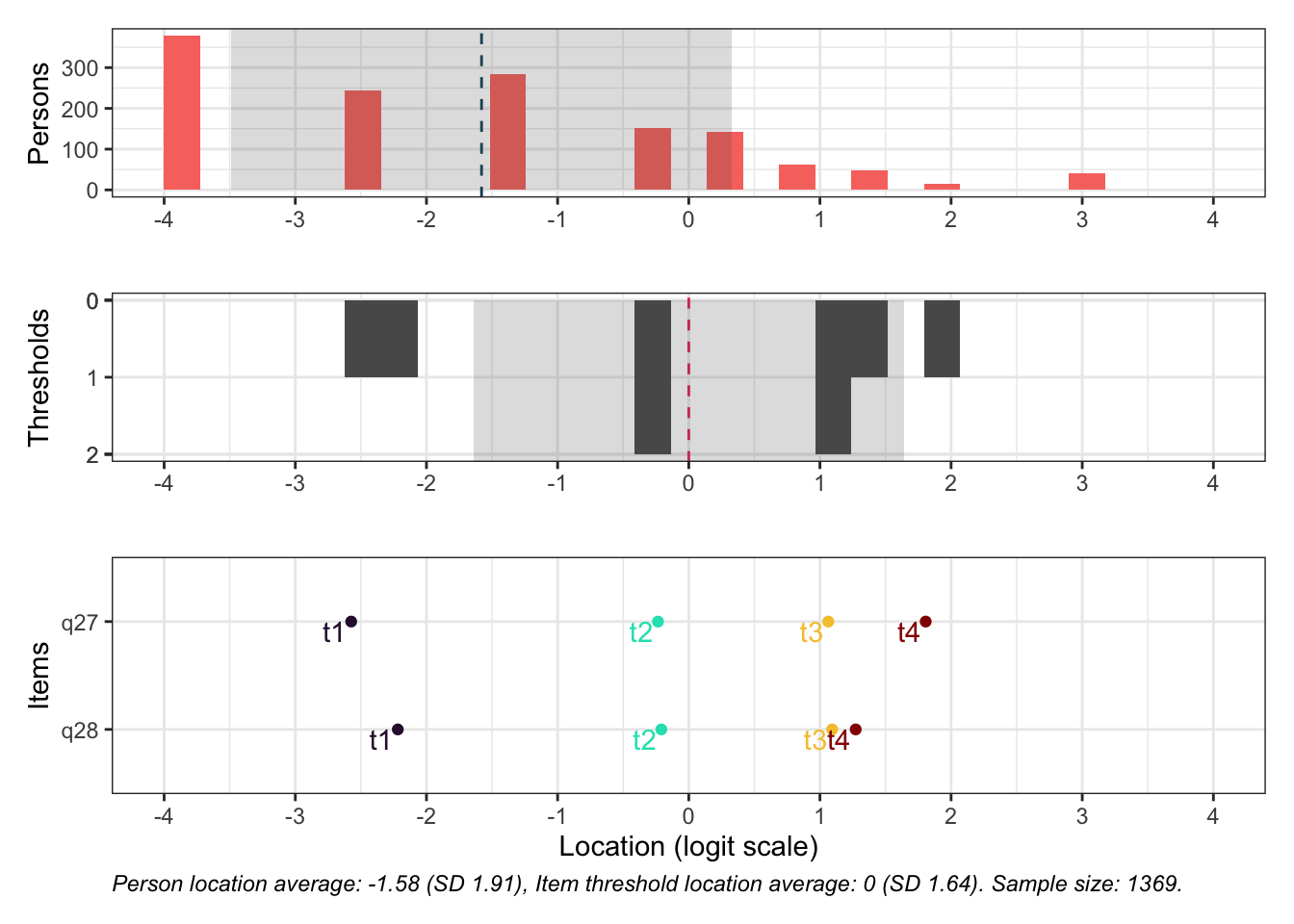
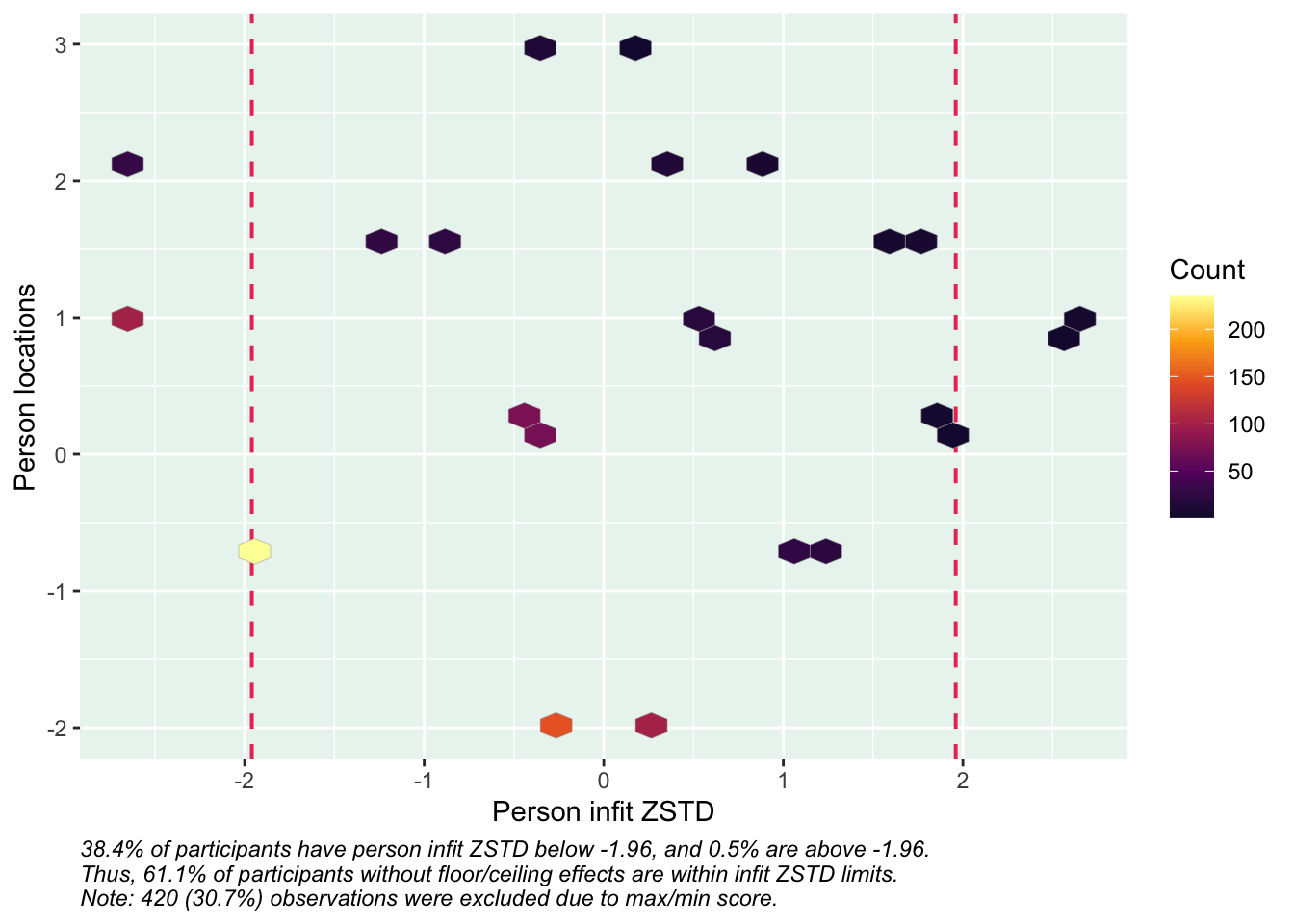
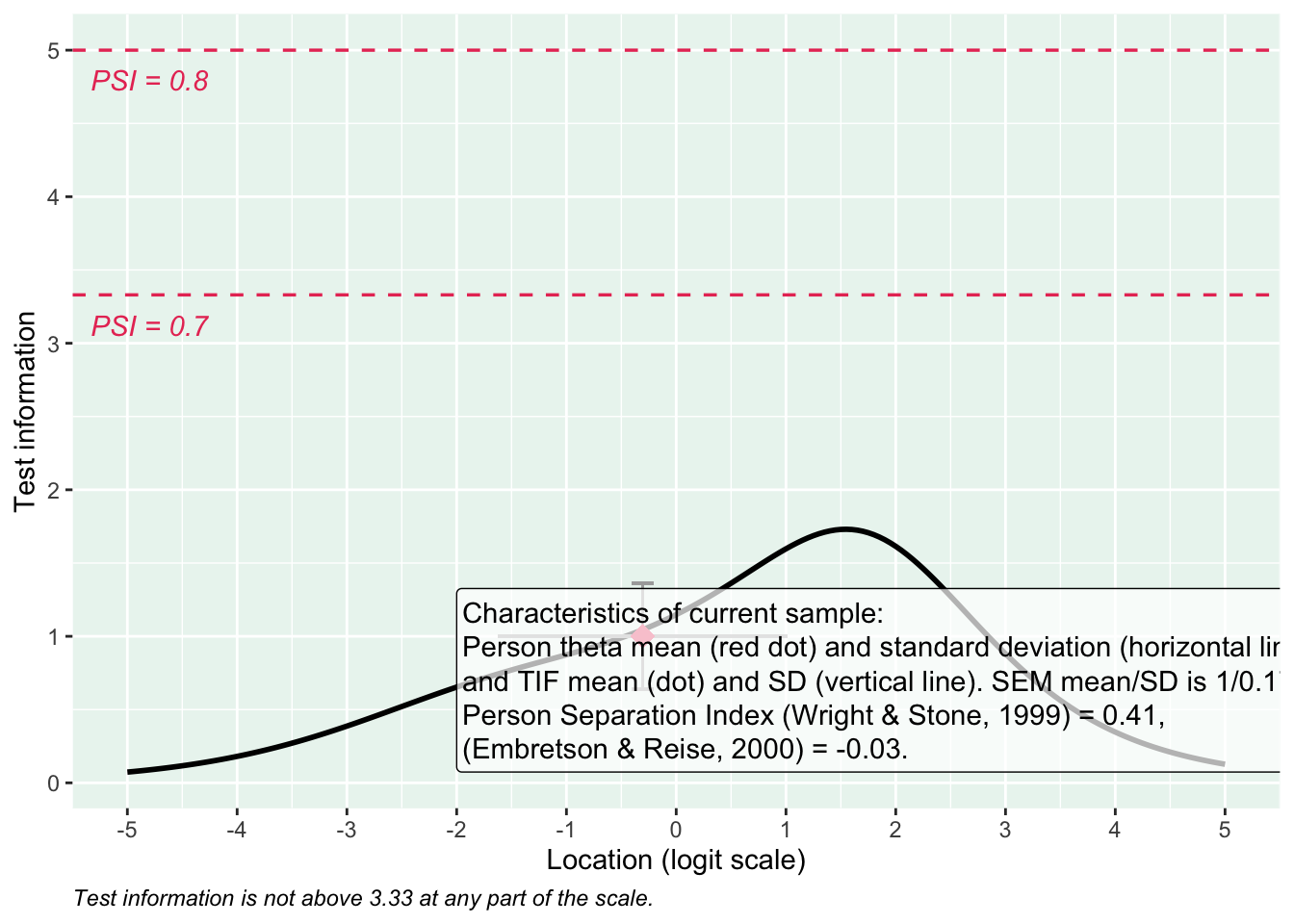
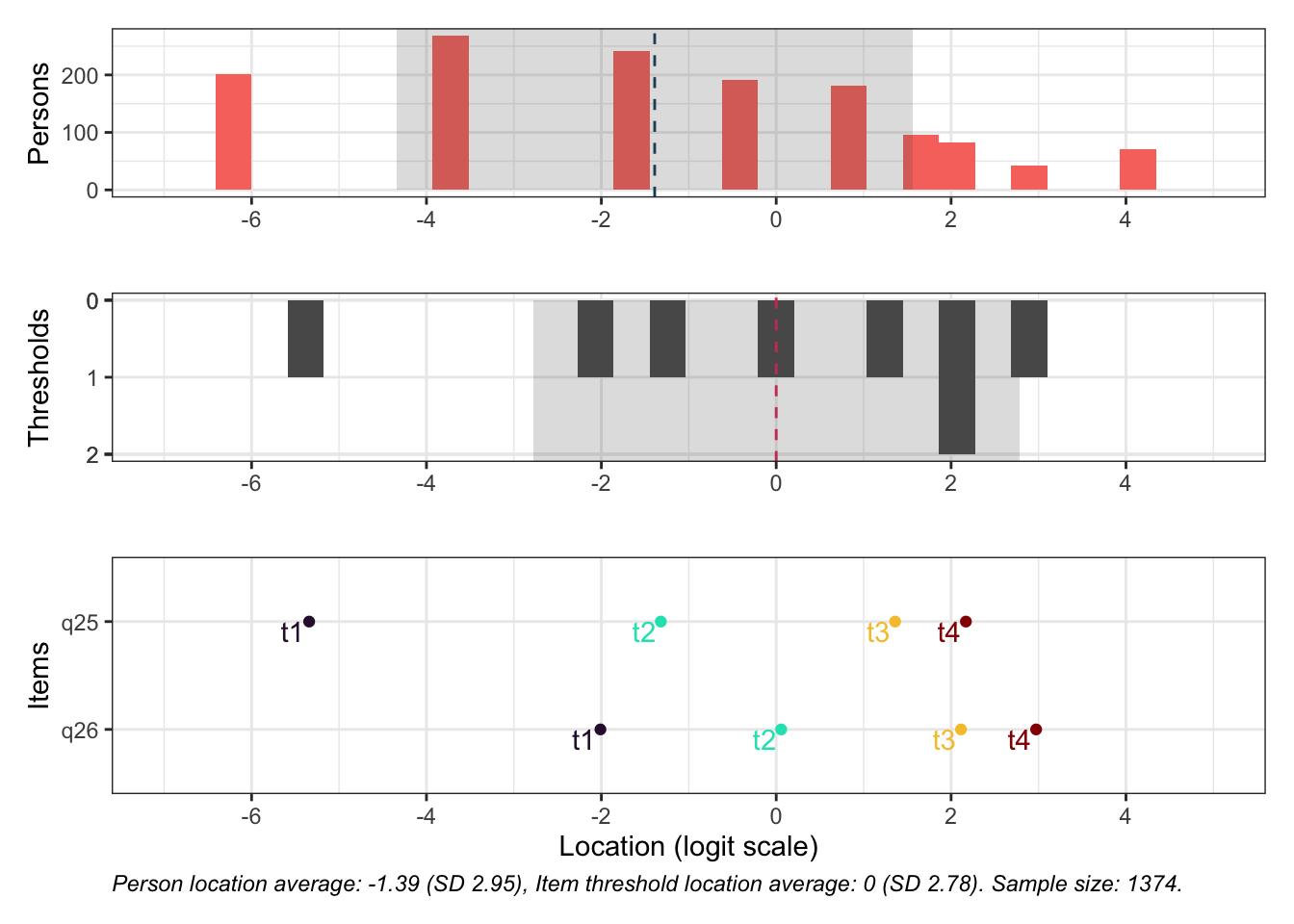
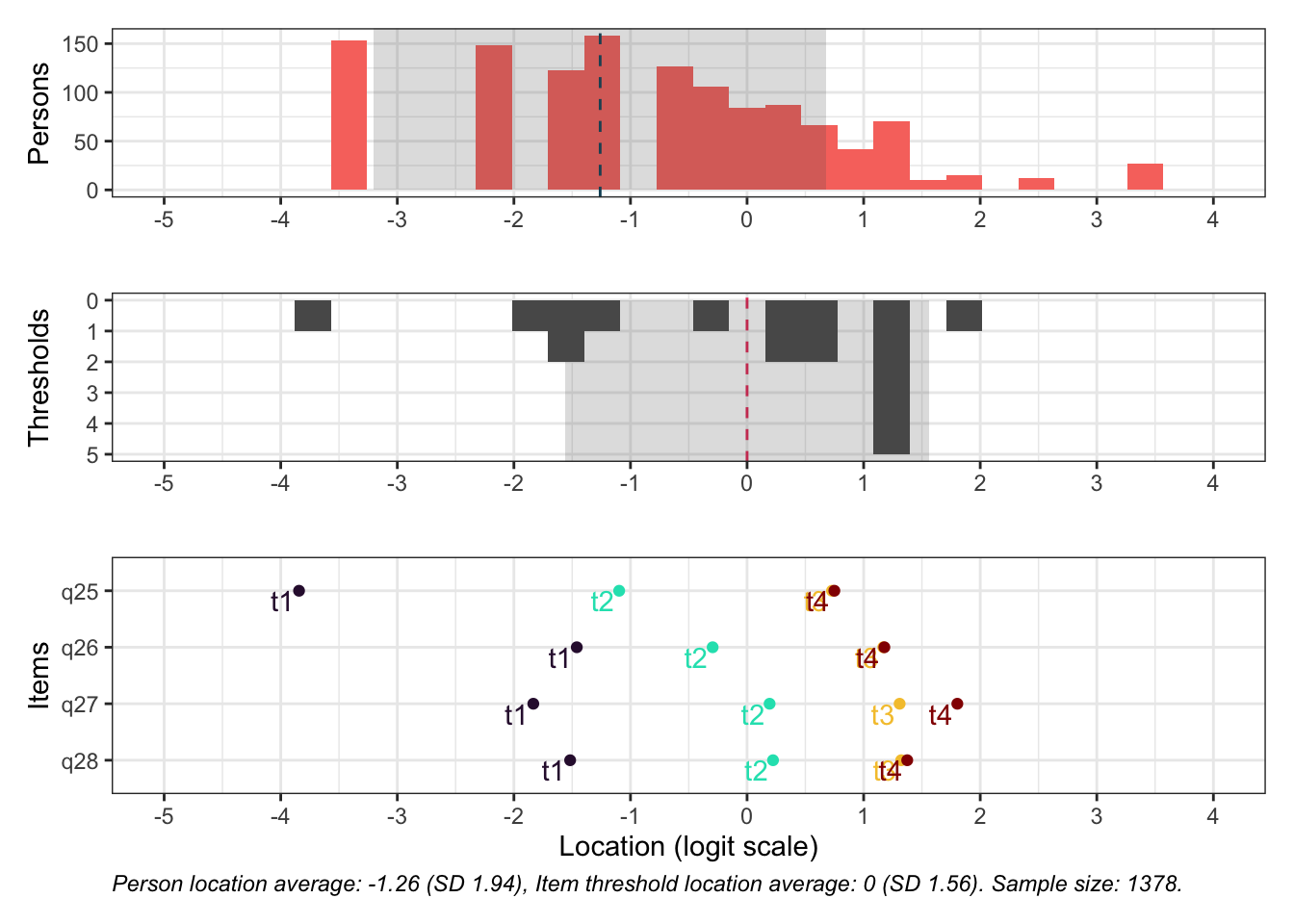
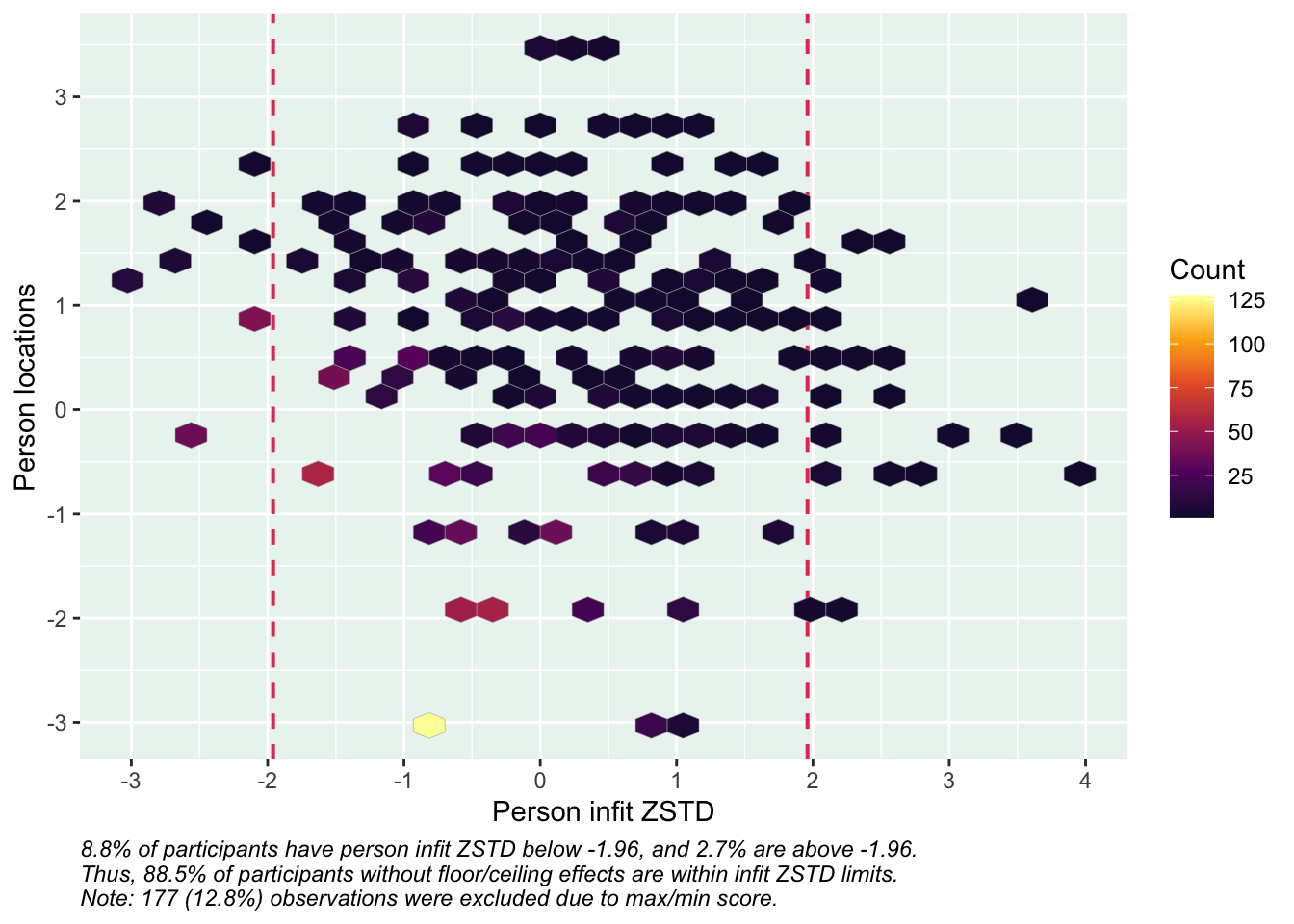
Targeting ok förutom ganska ycket golveffekter dvs. vi kan inte mäta så bra där det förekommer lägre värden av psykisk ohälsa, vilket är väntat.
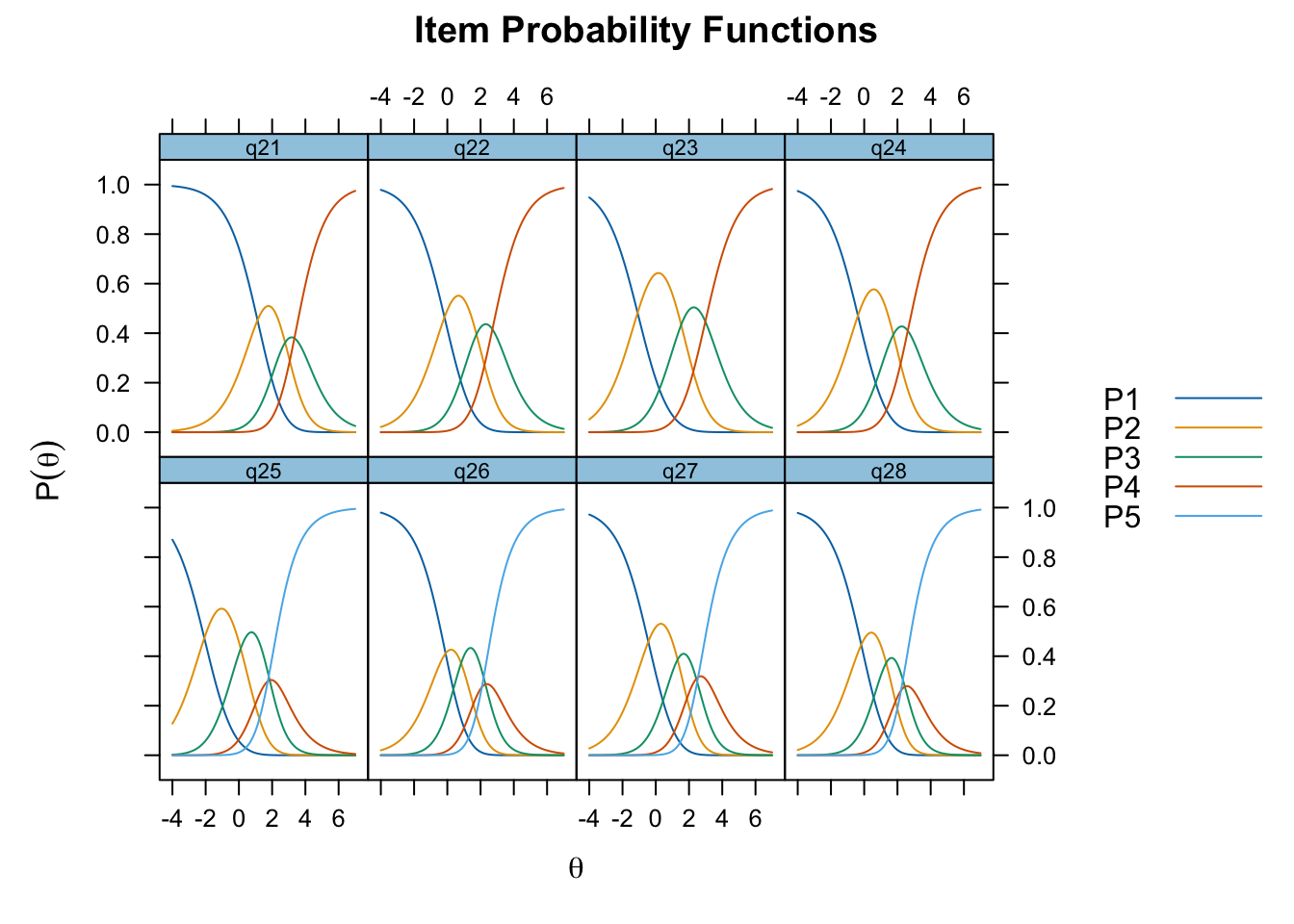
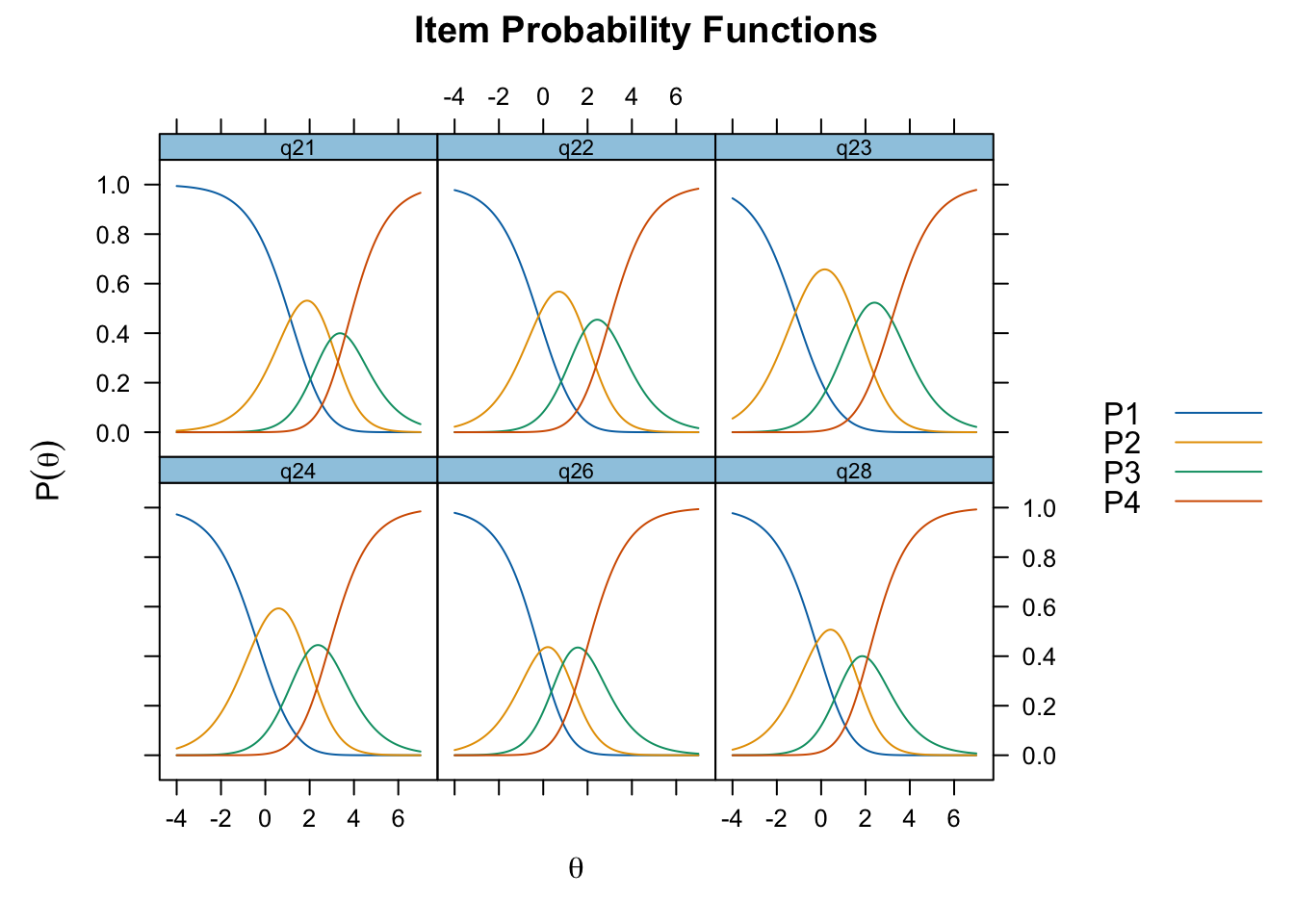
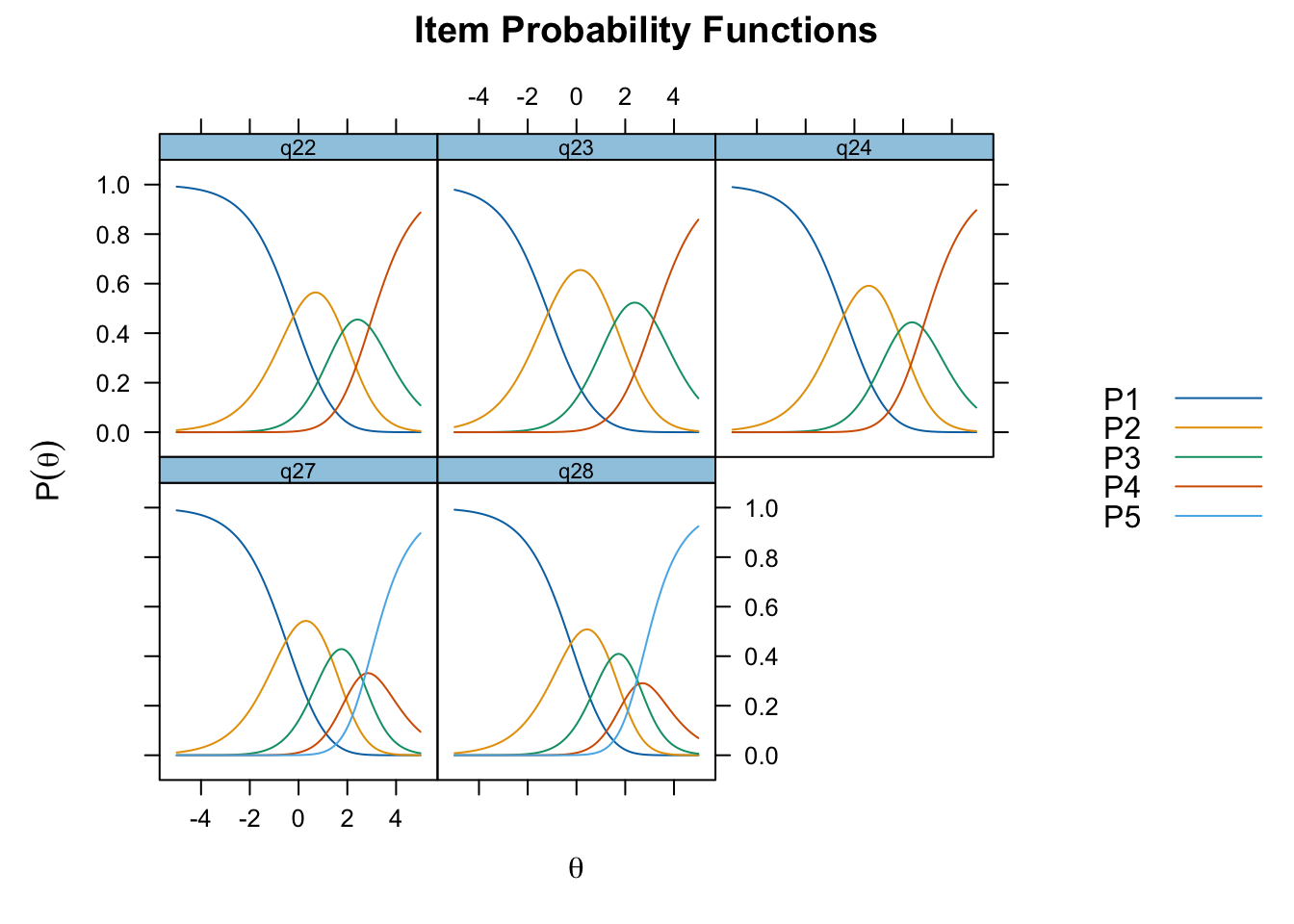
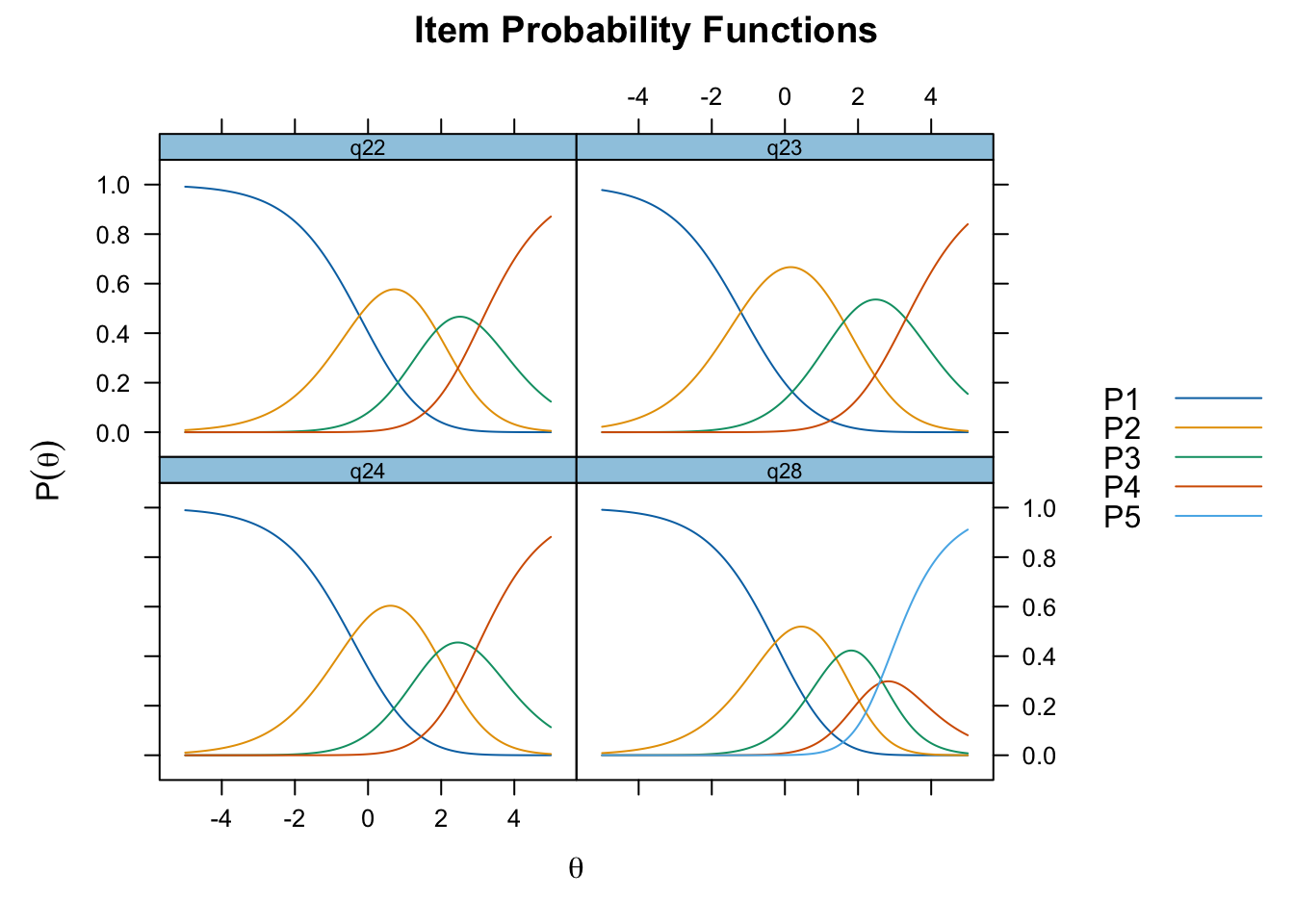
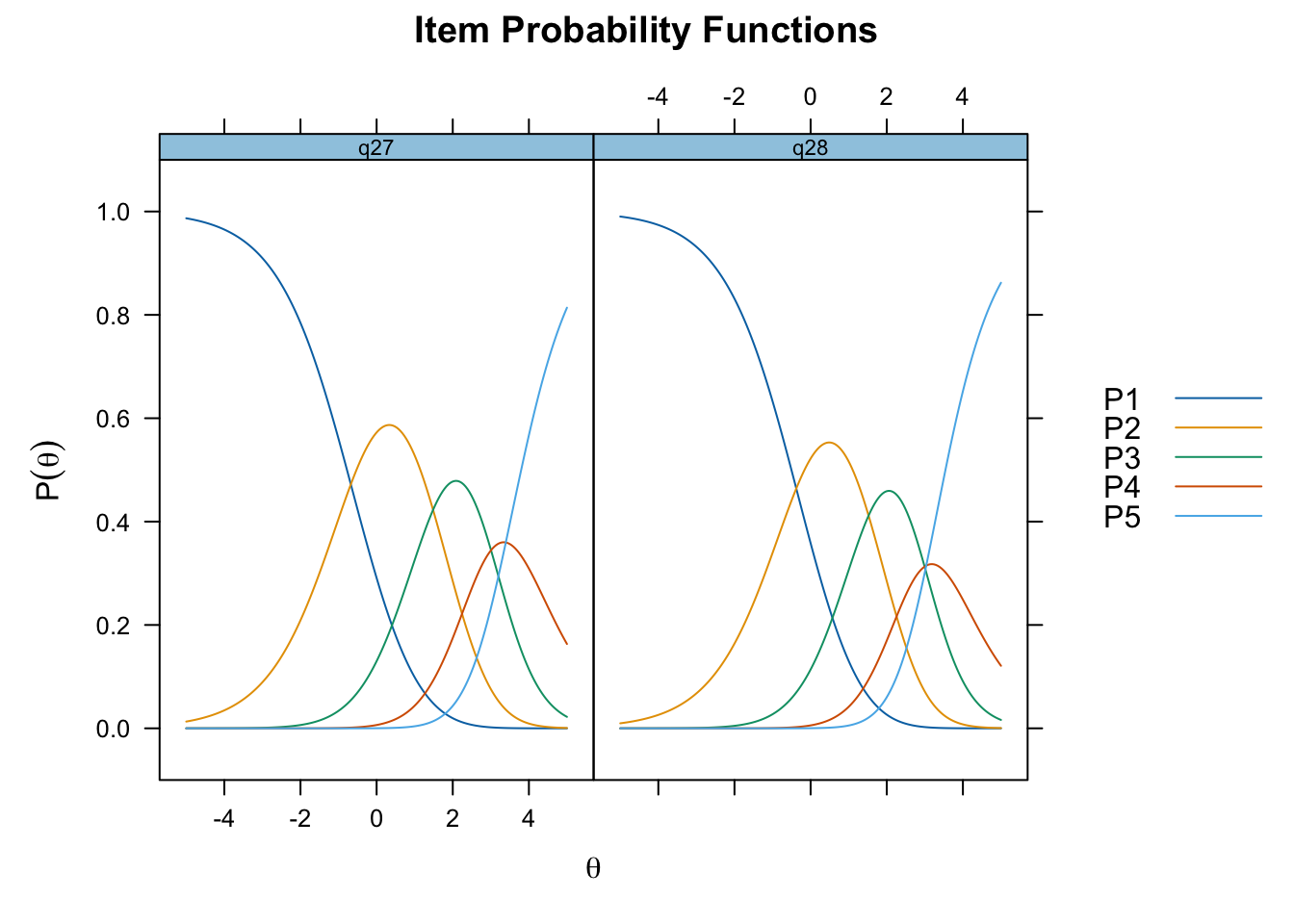
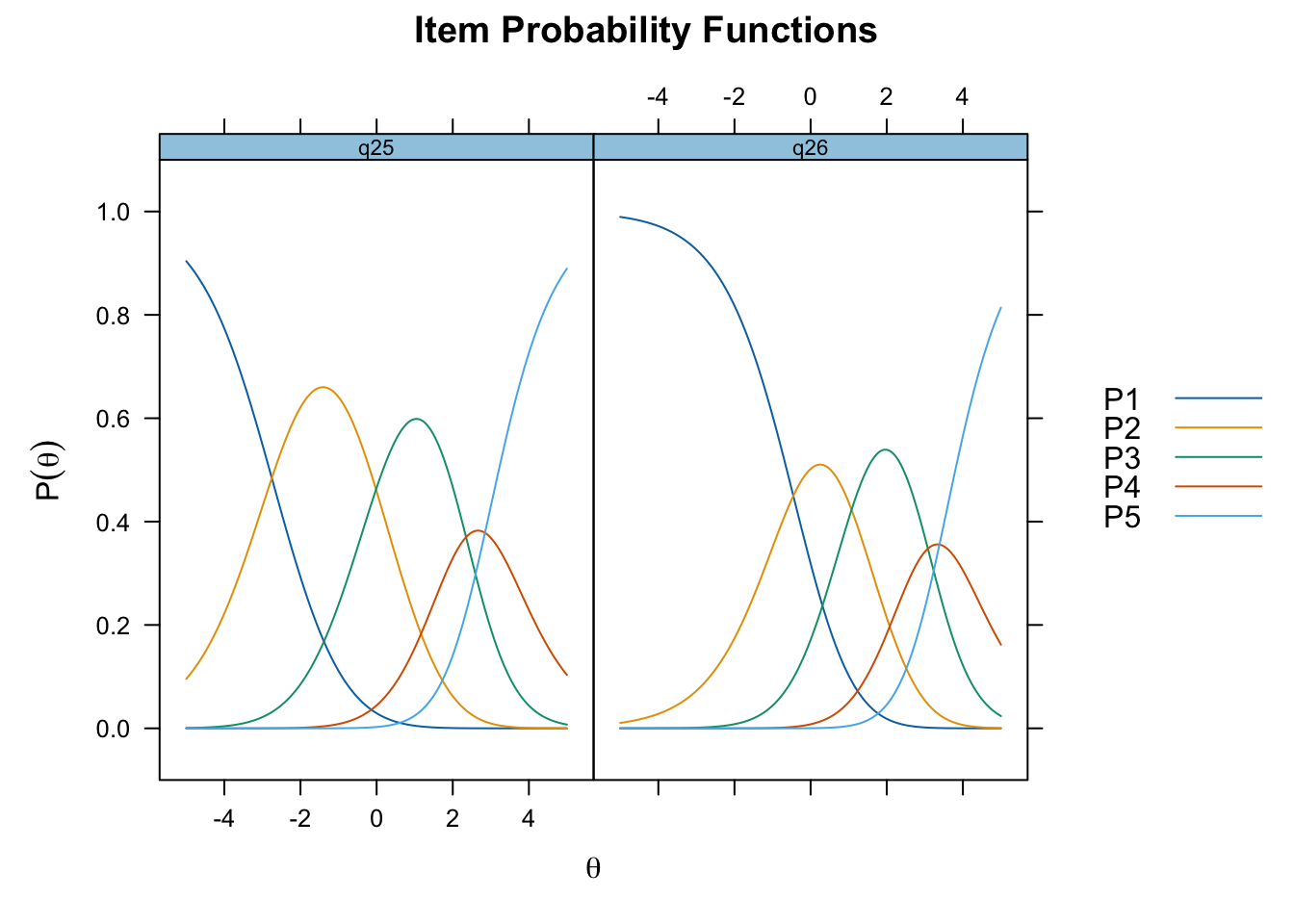
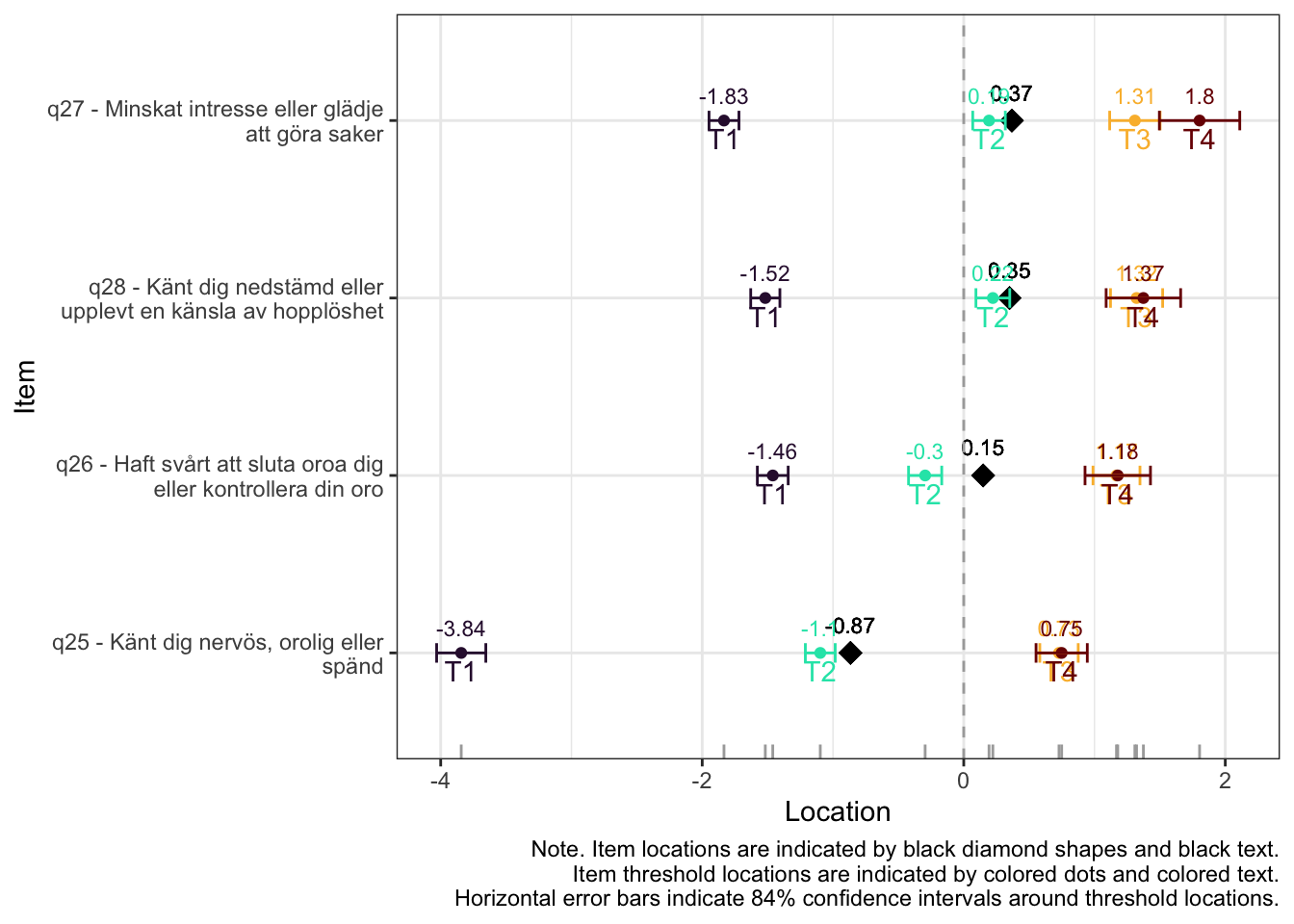
Oordnade svarskategorier på q28, q26 och q25, i samtliga fall gällande de två översta kategorierna
De understa svarskategorierna fungerar utmärkt, vilket är viktigt för 25-28 där vi la till en svarskategori, vilket har gett goda resultat.
3.13 Eliminering av item
Även om det inte är det primära syftet är det intressant att se om det går att hitta en uppsättning items som fungerar tillsammans.
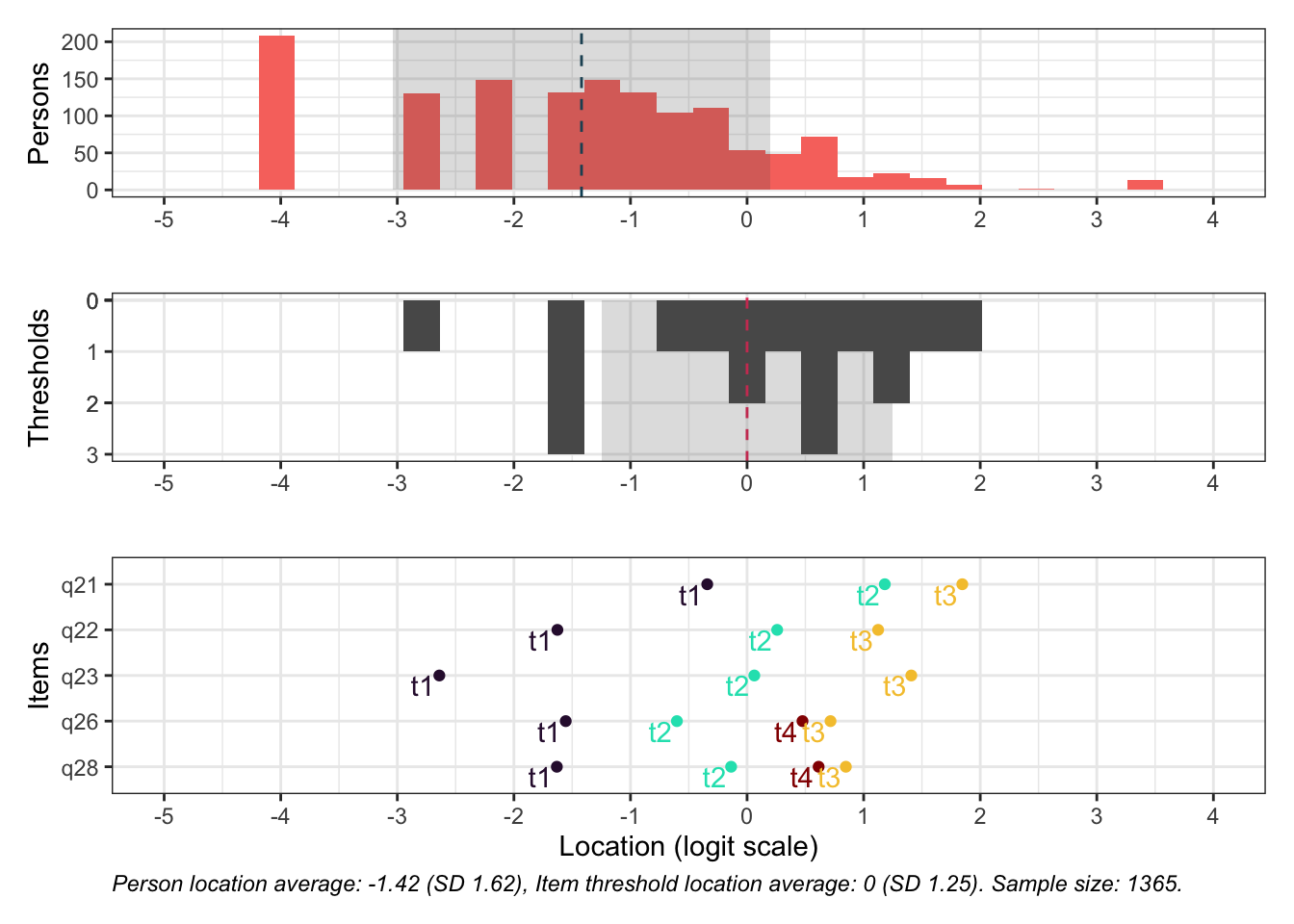
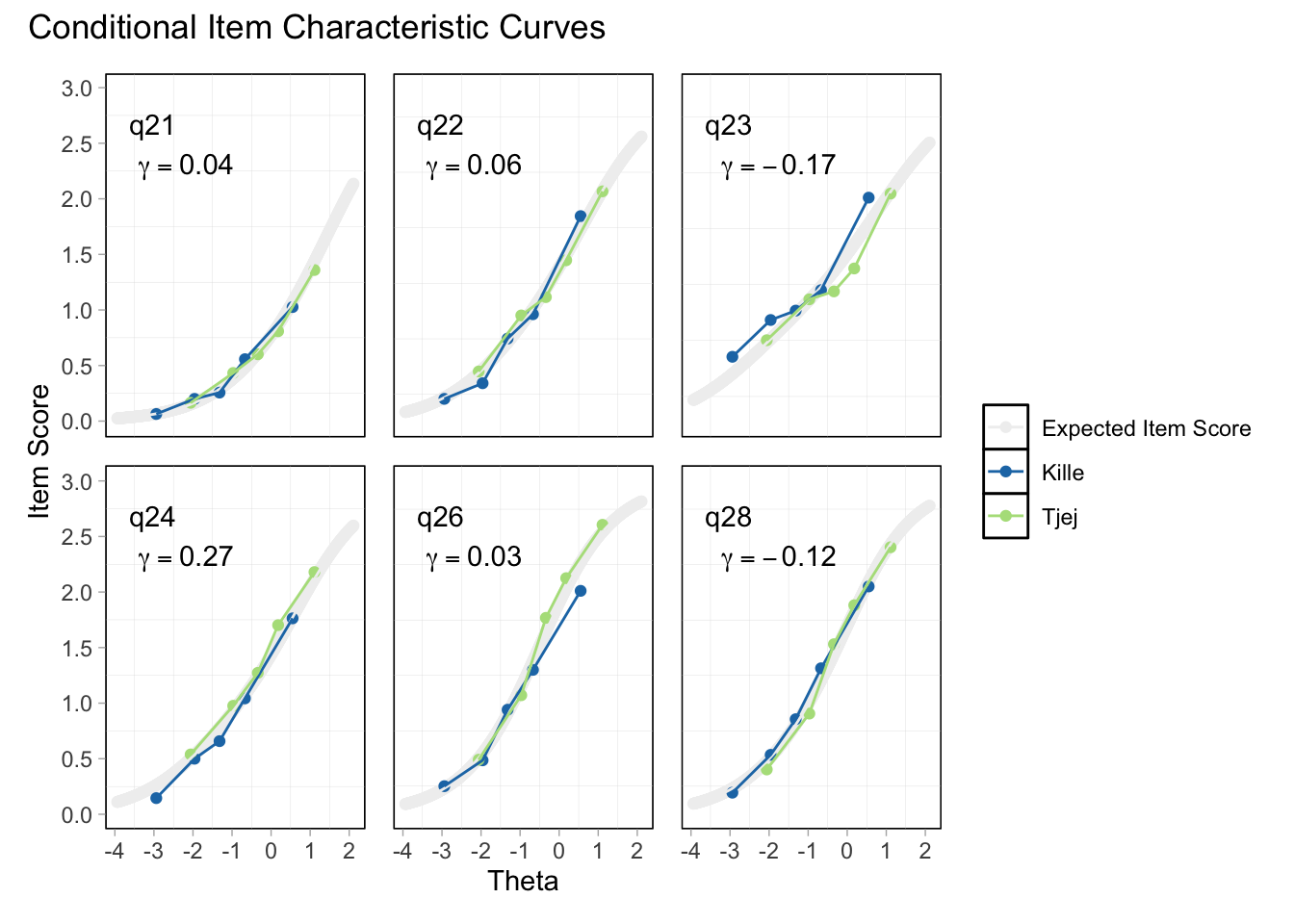
Ser ganska bra ut. Item 24 möjligen overfit, men inga residualkorrelationer, så det bör inte vara problematiskt. Översta svarskategorierna för 26 och 28 fortfarande oordnade.
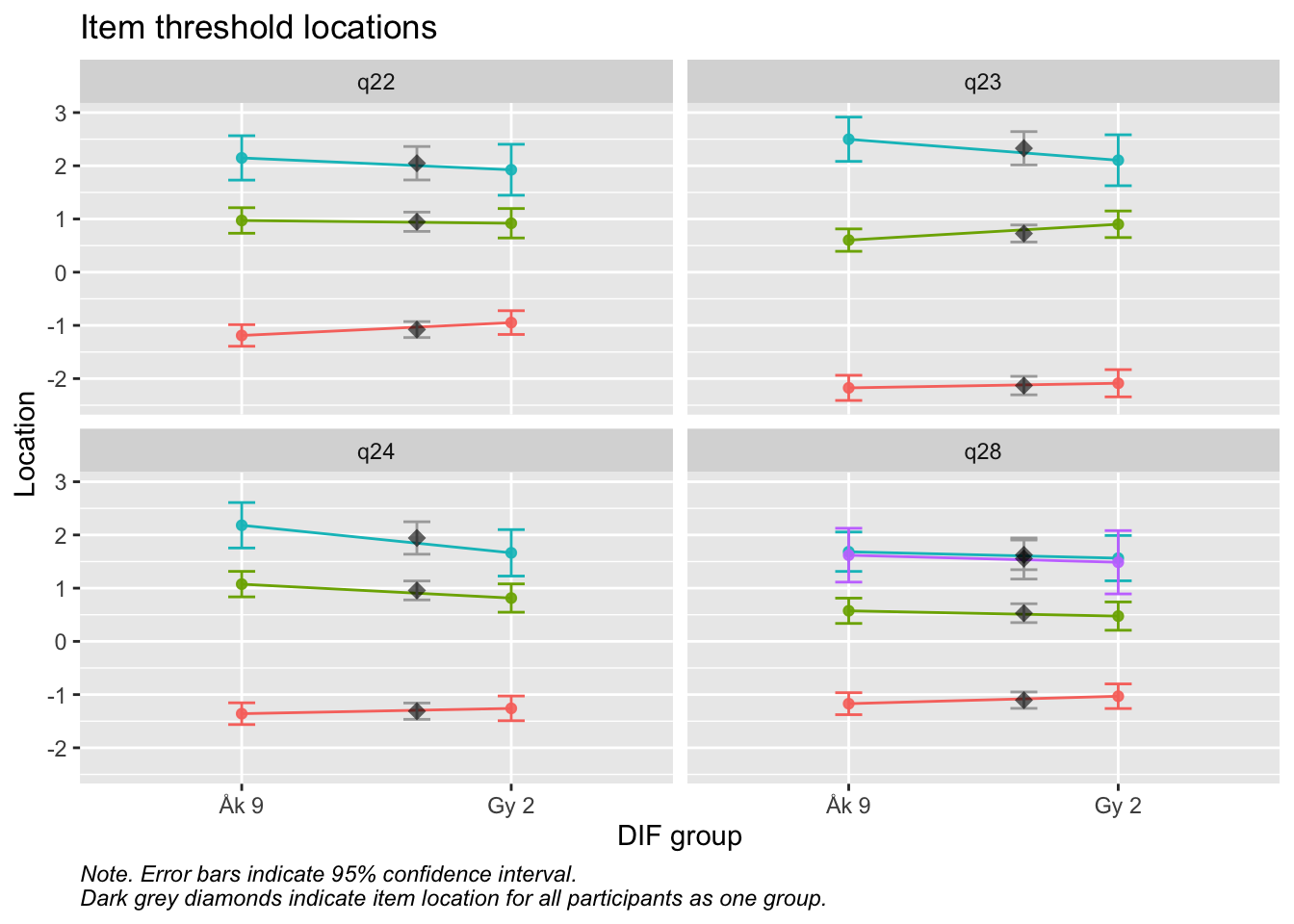
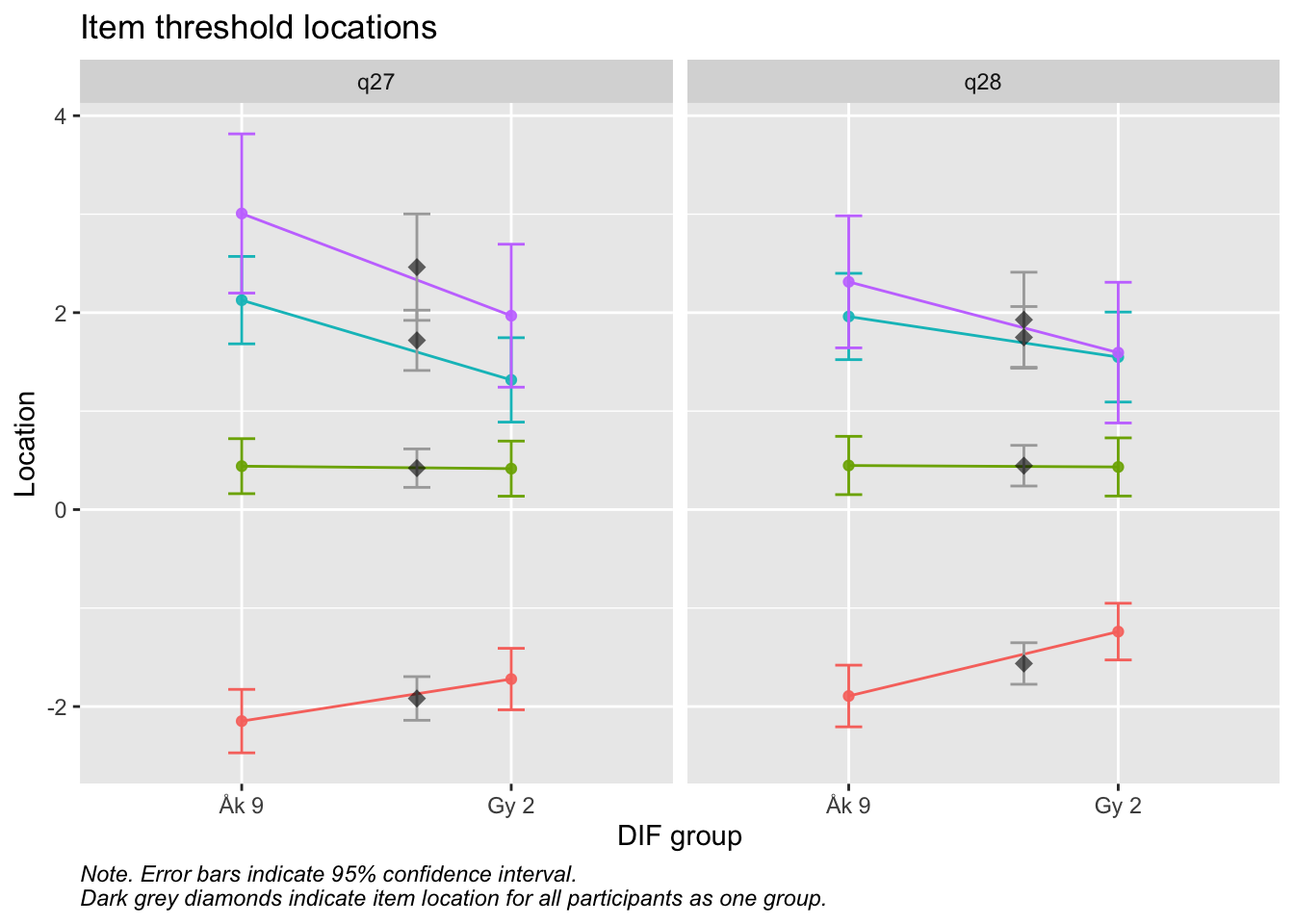
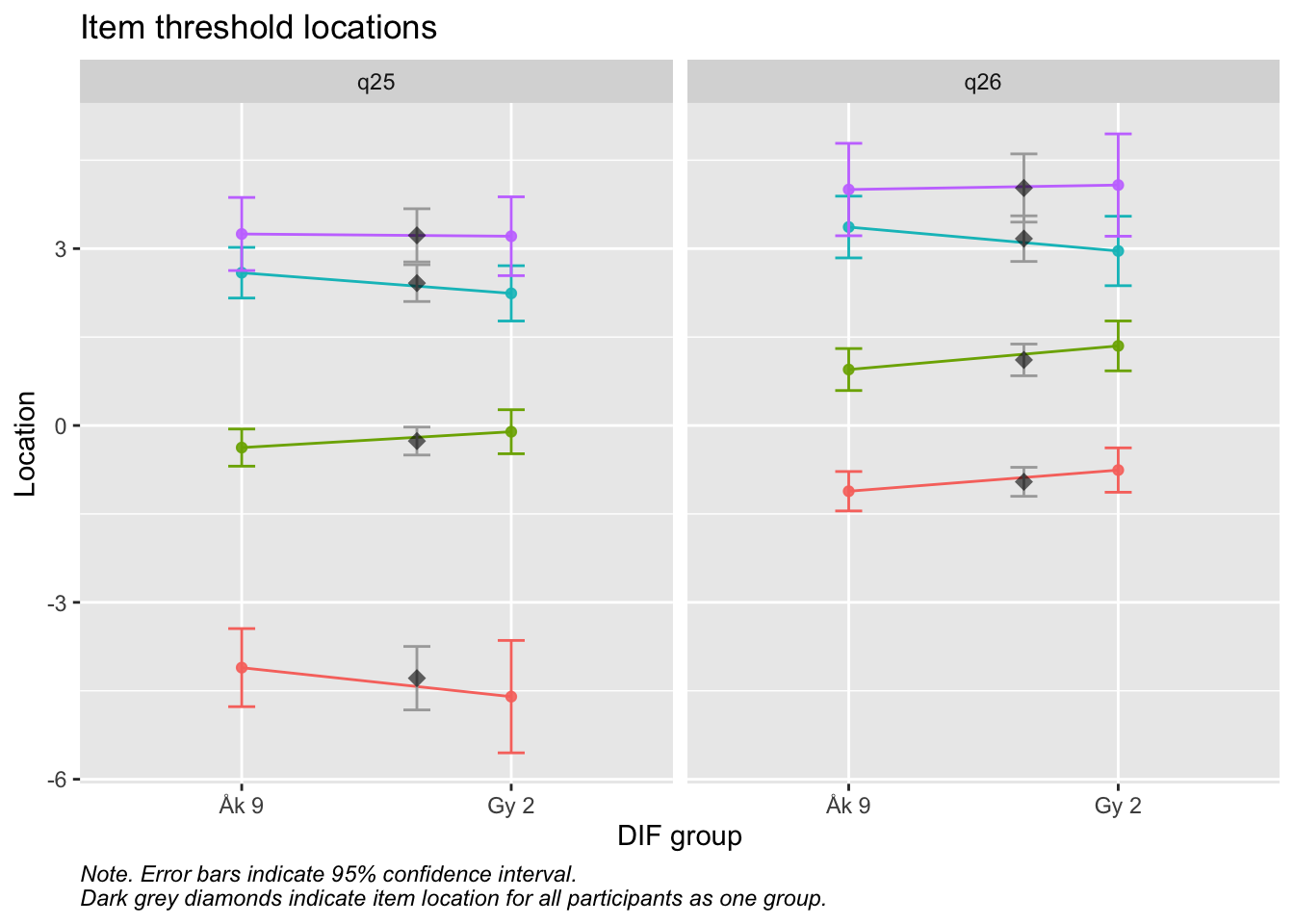
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
Code
RIdifThreshFigLR(d_psf_d, d_dif__psf_d$Årskurs)
Mokken visar samma dimension
ingen underfit
q28 möjligen overfit
PCA 1.61
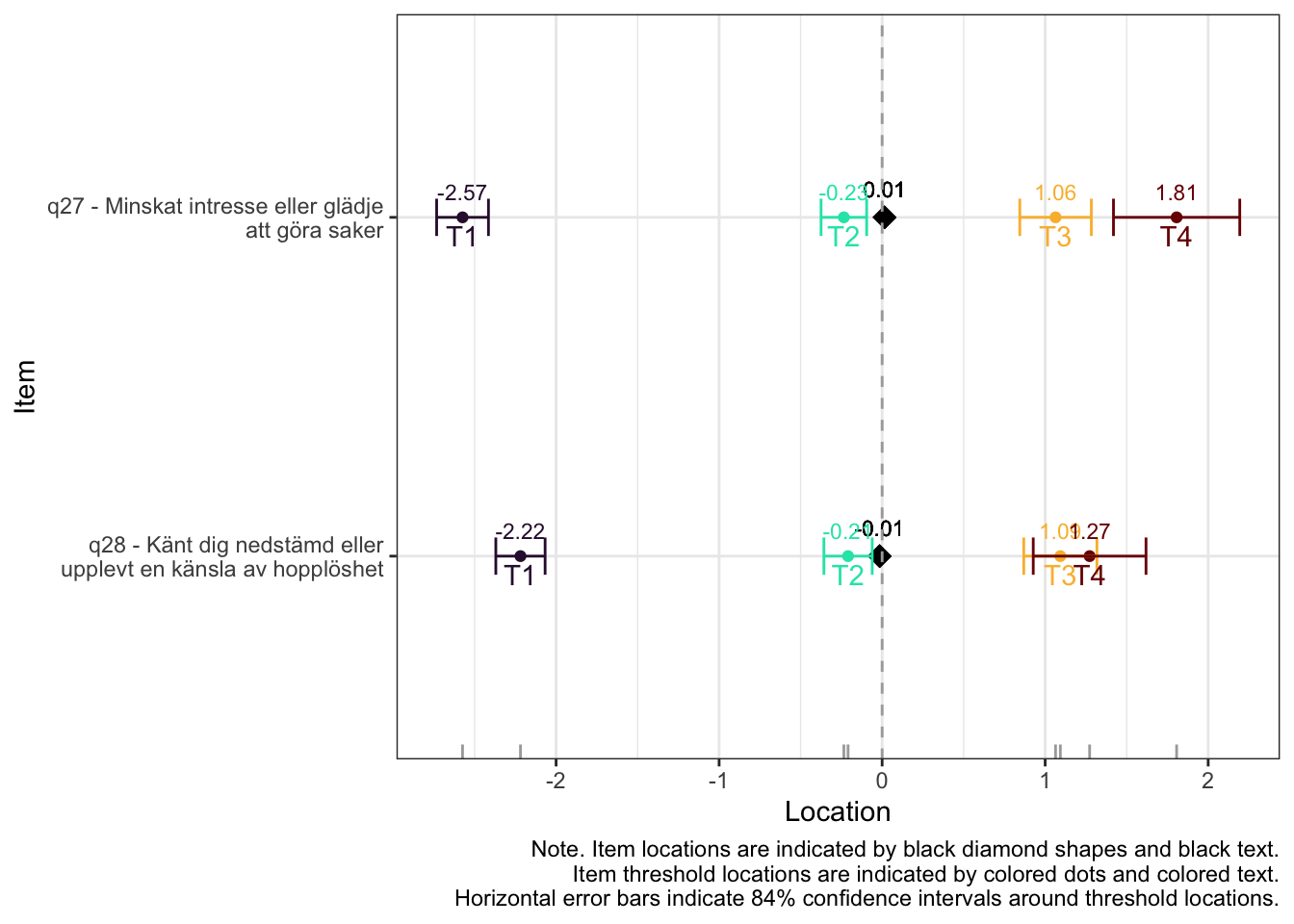
Lokalt beroende mellan q28 och q27 (PHQ-2)
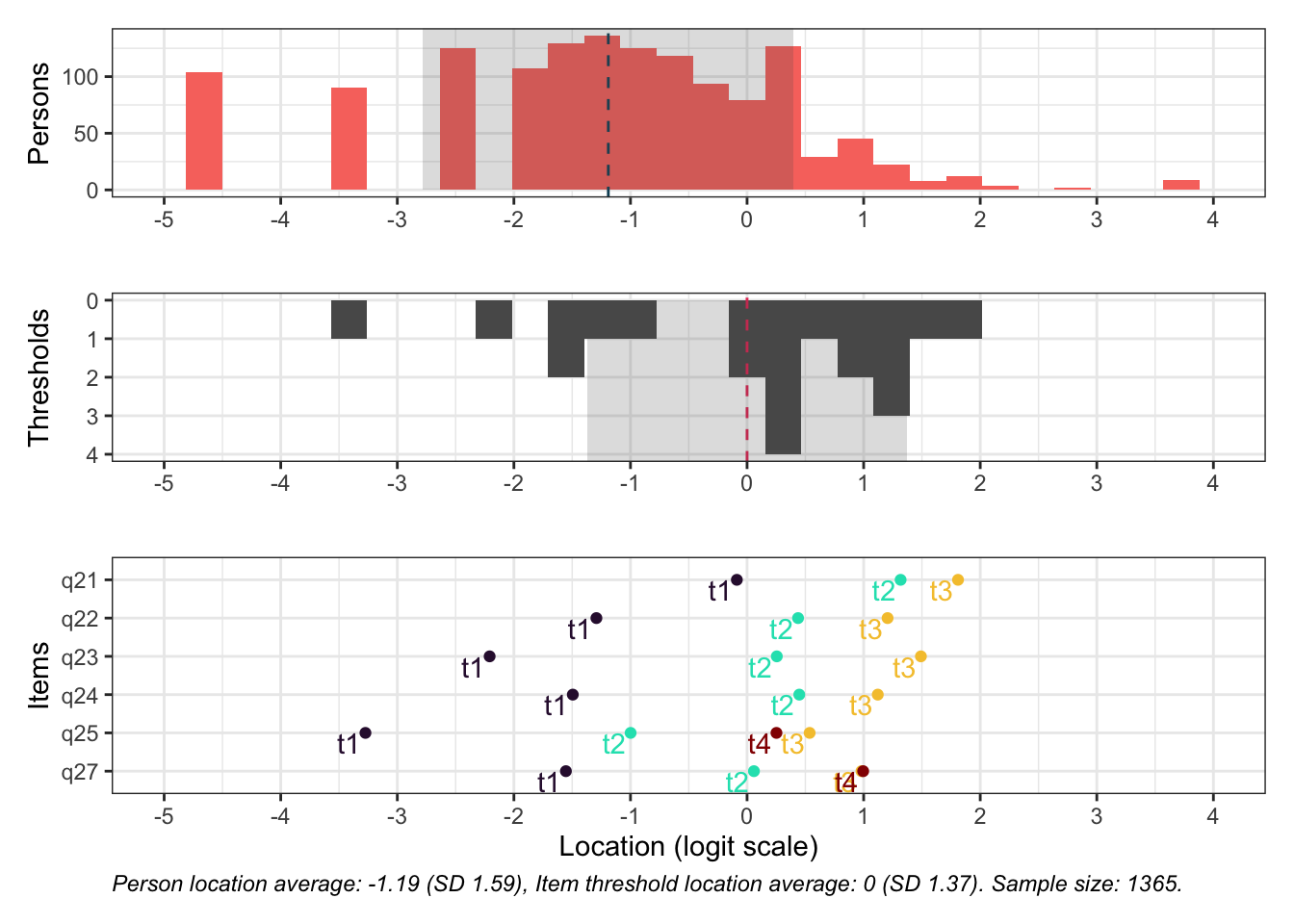
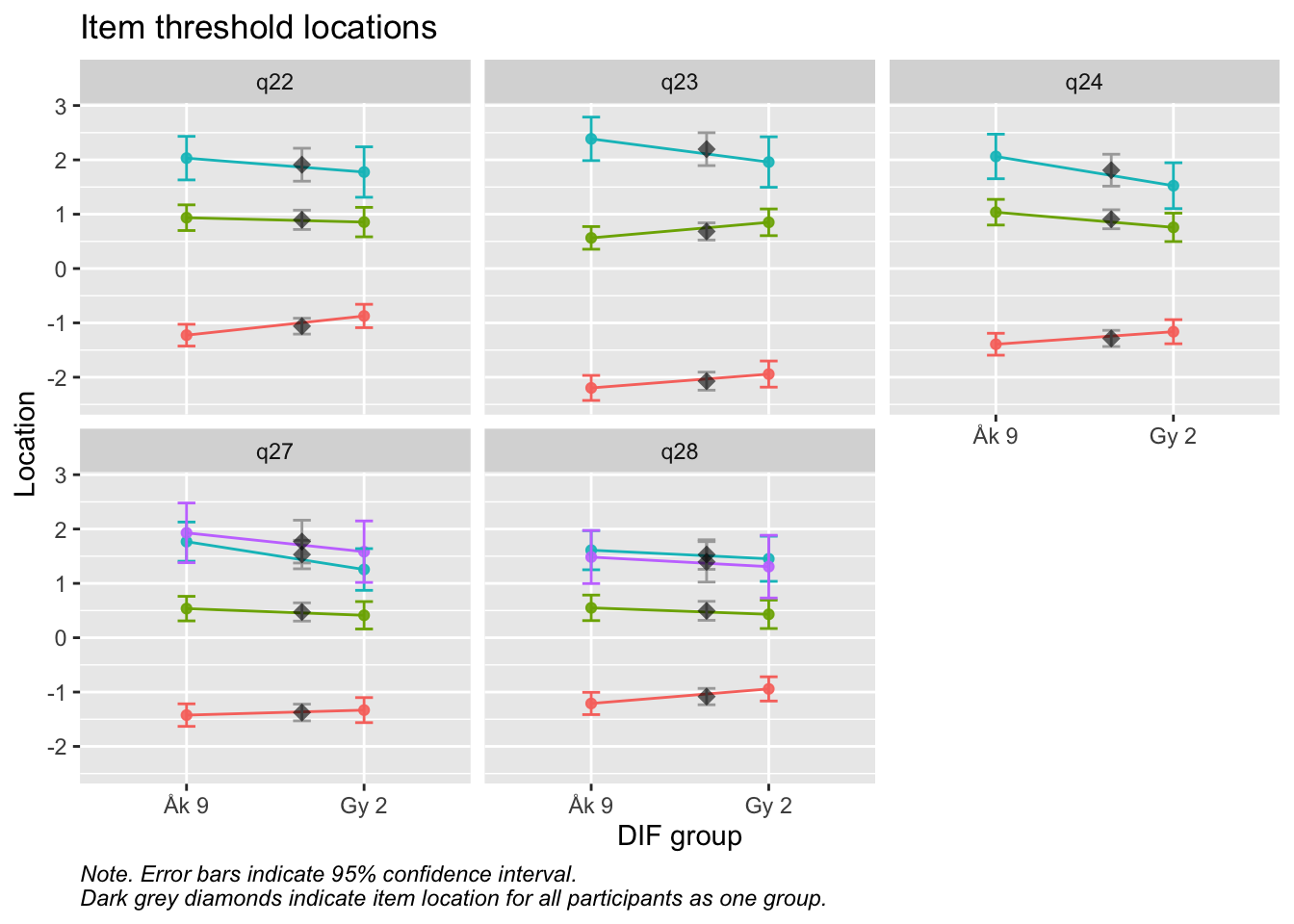
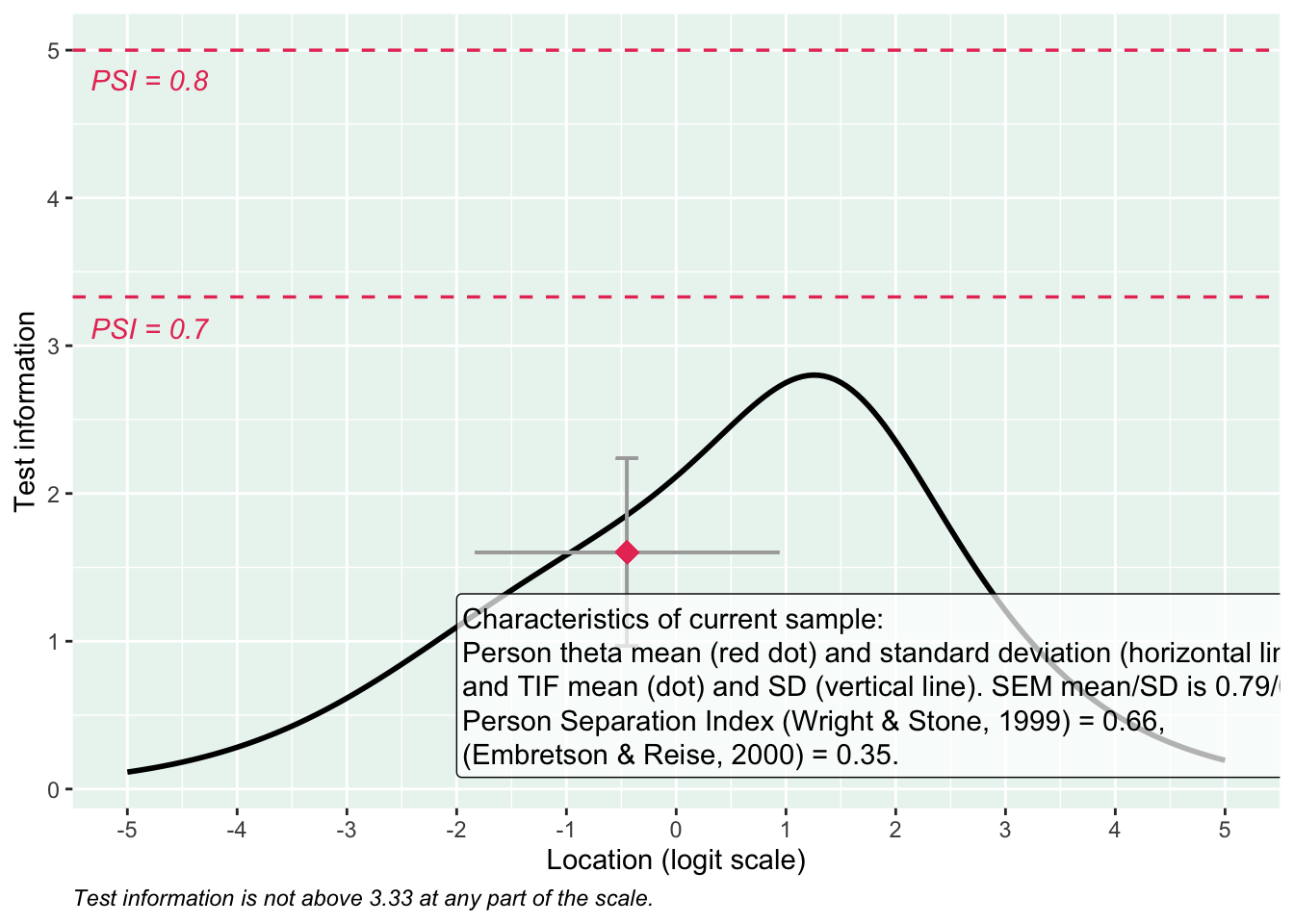
Targeting visar stora golveffekter: svårt att mäta lägre nivåer av psykisk ohälsa
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
Code
RIdifThreshFigLR(d_psf_d, d_dif__psf_d$Kön)
Code
RIpartgamDIF(d_psf_d, d_dif__psf_d$Årskurs)
[1] "No statistically significant DIF found."
Code
RIdifTableLR(d_psf_d, d_dif__psf_d$Årskurs)
Item locations
Standard errors
Item
Åk 9
Gy 2
MaxDiff
All
SE_Åk 9
SE_Gy 2
SE_All
q22
0.644
0.633
0.011
0.639
0.146
0.166
0.110
q23
0.309
0.306
0.003
0.308
0.147
0.167
0.110
q24
0.633
0.406
0.227
0.529
0.148
0.159
0.108
q28
0.677
0.624
0.053
0.652
0.168
0.194
0.127
Note:
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
Code
RIdifThreshFigLR(d_psf_d, d_dif__psf_d$Kön)
Code
RIpartgamDIF(d_psf_d, d_dif__psf_d$Årskurs)
[1] "No statistically significant DIF found."
Code
RIdifTableLR(d_psf_d, d_dif__psf_d$Årskurs)
Item locations
Standard errors
Item
Åk 9
Gy 2
MaxDiff
All
SE_Åk 9
SE_Gy 2
SE_All
q27
0.857
0.495
0.362
0.671
0.236
0.223
0.161
q28
0.707
0.584
0.123
0.640
0.219
0.224
0.155
Note:
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
Code
RIdifThreshFigLR(d_psf_å, d_dif__psf_å$Kön)
Code
RIpartgamDIF(d_psf_å, d_dif__psf_å$Årskurs)
[1] "No statistically significant DIF found."
Code
RIdifTableLR(d_psf_å, d_dif__psf_å$Årskurs)
Item locations
Standard errors
Item
Åk 9
Gy 2
MaxDiff
All
SE_Åk 9
SE_Gy 2
SE_All
q25
0.339
0.186
0.153
0.273
0.259
0.314
0.196
q26
1.8
1.908
0.108
1.838
0.255
0.288
0.189
Note:
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
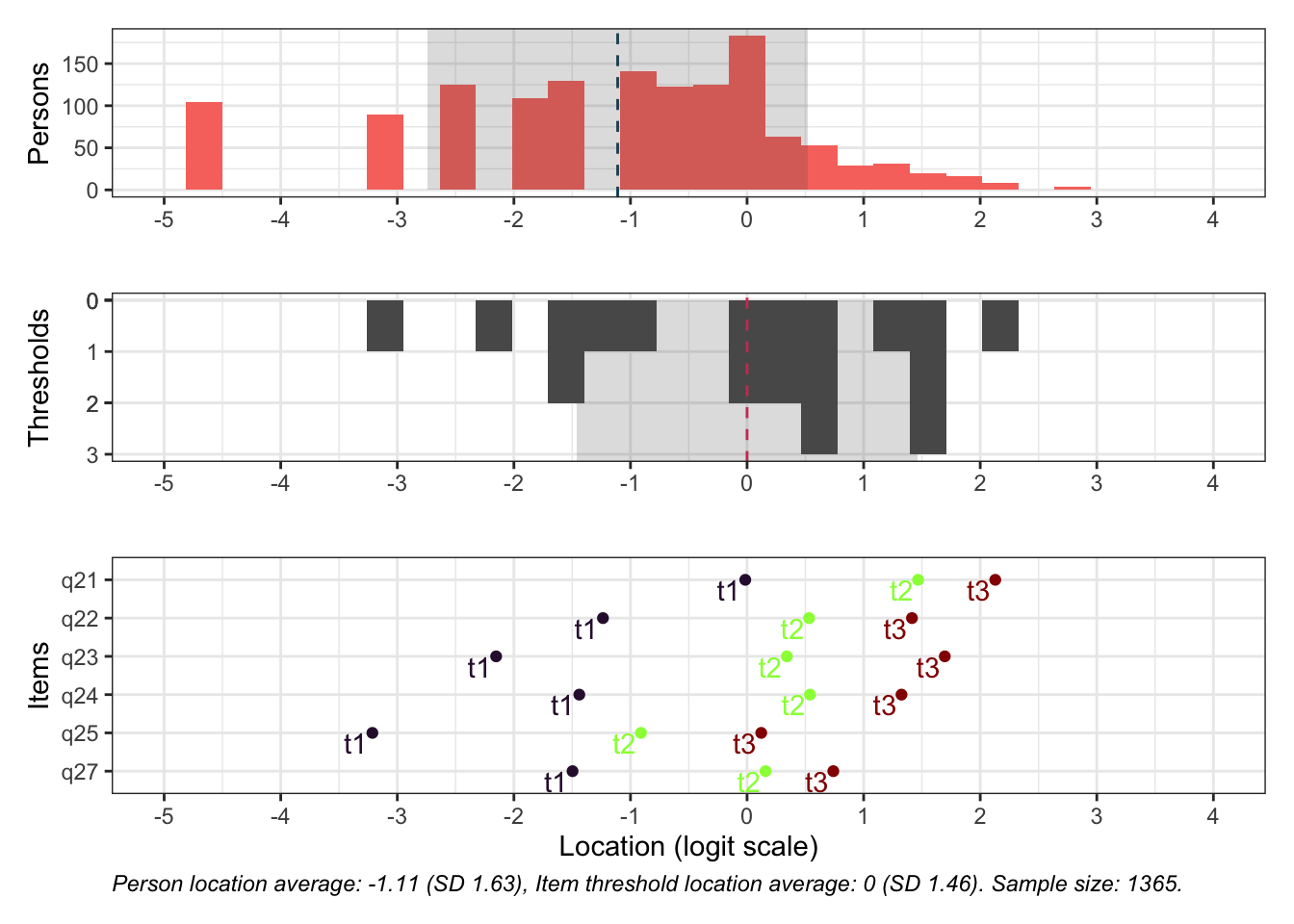
Även om item-restscore inte indikerar någon klar problematik med dimensionaliteten så finns påtagliga residualkorrelationer mellan de två item-paren.
3.21 Preliminär riskgruppsanalys
Vi använder ordinal sum score >= 5 som cutoff (fem eller högre), utifrån att 3 normalt sett använts, men vi har lagt till en svarskategori som den nästa lägsta.
Utifrån targeting-figuren i analysen med alla depressions items har vi sum score >=6 på items q22+q23+q24 som motsvarar samma mätvärde (theta) som ovan använda cutoff för q27 och q28.
Snarlika siffror. Lite större skillnad för pojkarna.
3.21.3 Depression jämförelse
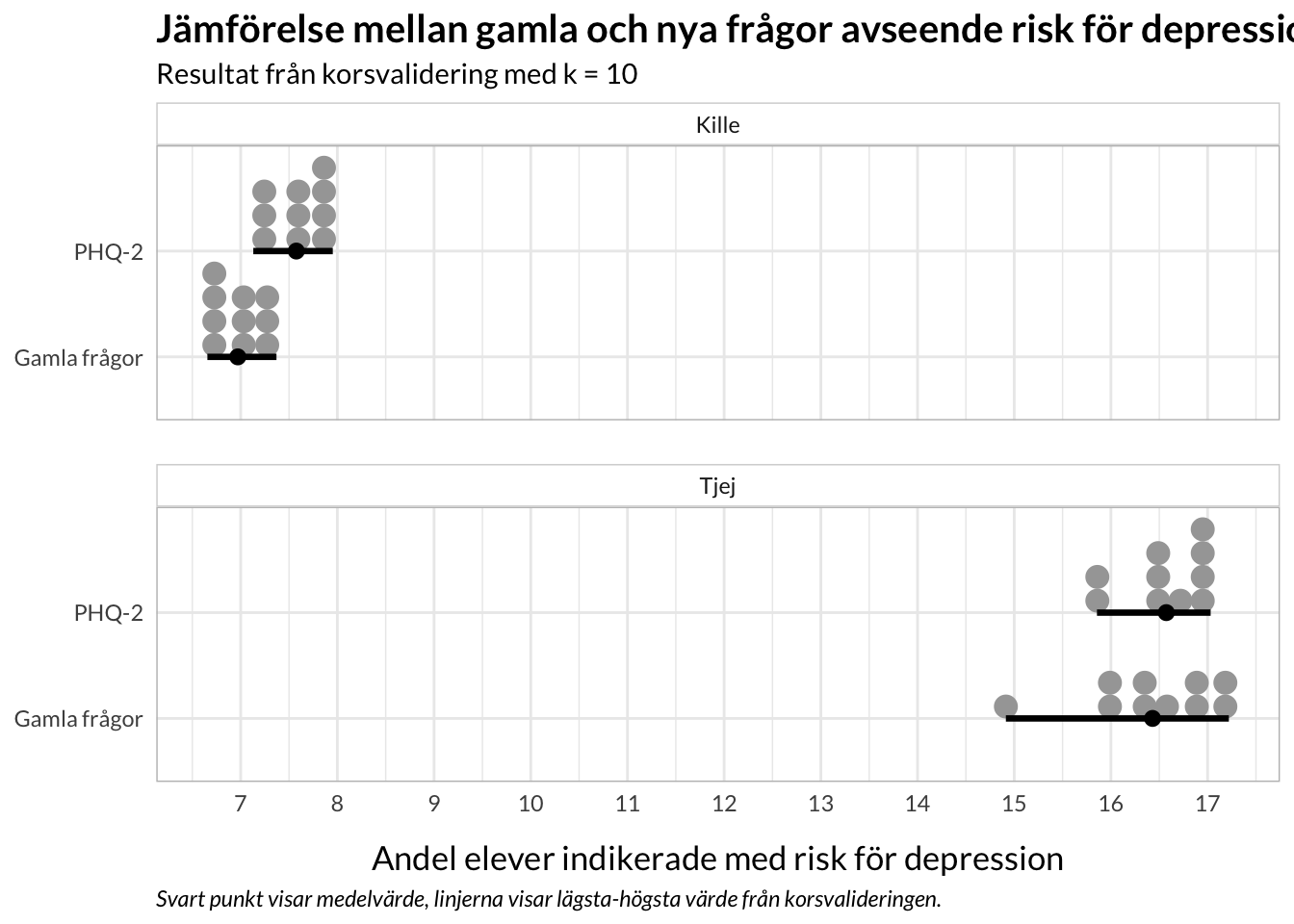
Vi behöver korsvalidera detta för att se om jämförelsen är stabil även när vi varierar samplet. Korsvalidering gör en slumpmässig indelning av samplet, i vårt fall används 10 delar (subsampel). Sedan upprepas testet 10 gånger, varje gång med något subsampel borttaget. Vi stratifierar indelningen av samplet på Årskurs för att säkerställa likvärdighet i subsamplen.
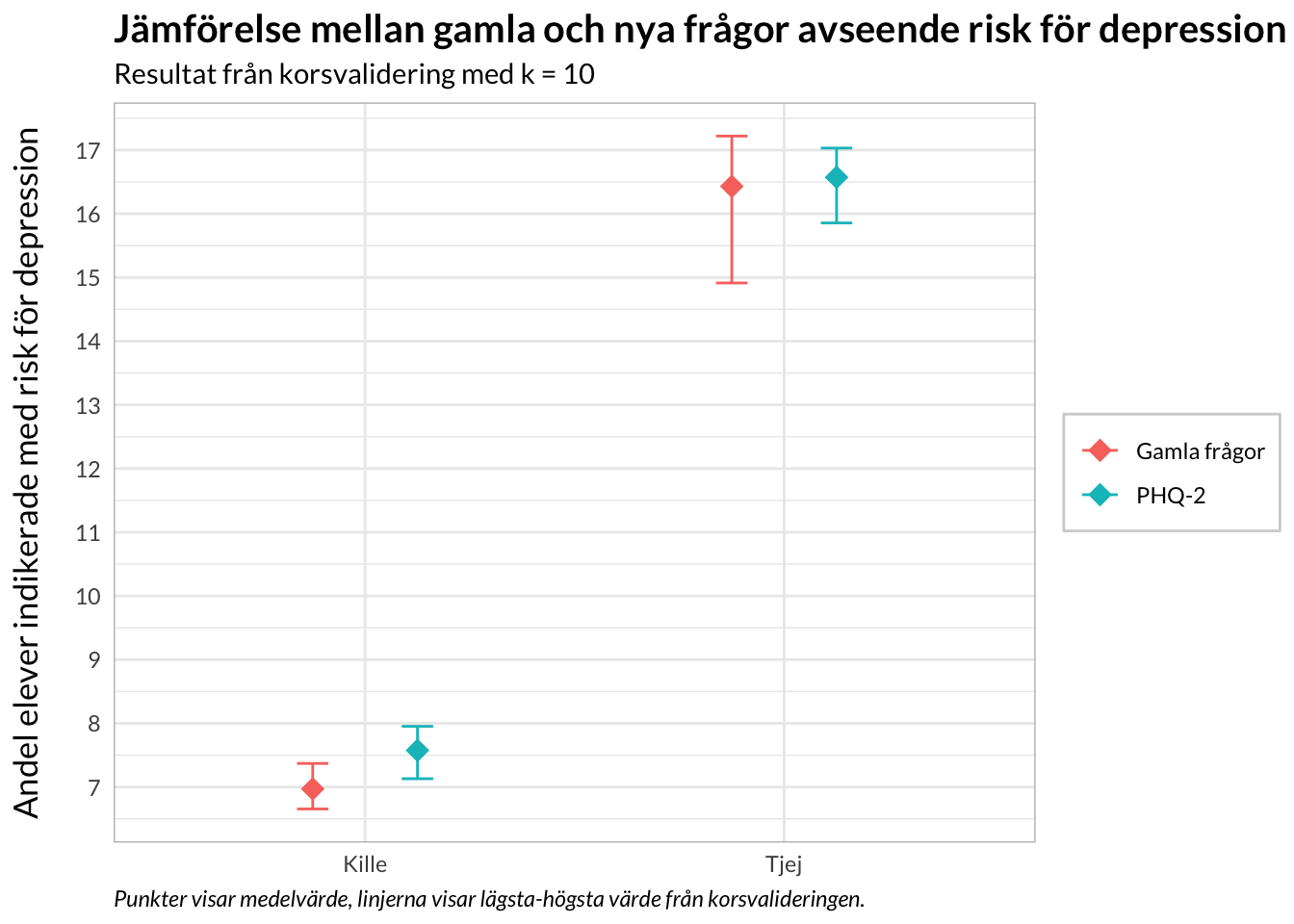
nya_alla<-map_dfr(1:10, ~analysis(d_folds$splits[[.x]])%>%group_by(Kön)%>%count(phq_risk)%>%mutate(percent =n*100/sum(n)))%>%ungroup()%>%rename(dep_risk =phq_risk)%>%add_column(items ="PHQ-2")gamla_alla<-map_dfr(1:10, ~analysis(d_folds$splits[[.x]])%>%group_by(Kön)%>%count(dep_risk)%>%mutate(percent =n*100/sum(n)))%>%ungroup()%>%add_column(items ="Gamla frågor")library(ggdist)rbind(gamla_alla,nya_alla)%>%filter(dep_risk=="at_risk")%>%ggplot(aes(y =items, x =percent))+# geom_point(position = position_dodge(width = 0.5)) +# geom_errorbar(aes(ymin = lower, ymax = upper),# position = position_dodge(width = 0.5),# width = 0.3)stat_dotsinterval(point_interval ="mean_qi", .width =1)+facet_wrap(~Kön, ncol =1)+scale_x_continuous(breaks =scales::breaks_pretty(10))+theme_rise()+labs(y =NULL, x ="Andel elever indikerade med risk för depression", title ="Jämförelse mellan gamla och nya frågor avseende risk för depression", subtitle ="Resultat från korsvalidering med k = 10", caption ="Svart punkt visar medelvärde, linjerna visar lägsta-högsta värde från korsvalideringen.")
Code
rbind(gamla,nya)%>%filter(dep_risk=="at_risk")%>%ggplot(aes(y =mean, x =Kön, color =items))+geom_point(position =position_dodge(width =0.5), size =4, shape =18)+geom_errorbar(aes(ymin =lower, ymax =upper), position =position_dodge(width =0.5), width =0.15)+labs(x =NULL, color =NULL, y ="Andel elever indikerade med risk för depression", title ="Jämförelse mellan gamla och nya frågor avseende risk för depression", subtitle ="Resultat från korsvalidering med k = 10", caption ="Punkter visar medelvärde, linjerna visar lägsta-högsta värde från korsvalideringen.")+scale_y_continuous(breaks =scales::breaks_pretty(10))+theme_rise()
Det finns lite DIF för kön för gamla items, vilket kan vara det som orsakar att pojkarna har aningen större skillnad i riskidentifikation mellan gamla och nya items. PHQ-2 verkar stabilare än de gamla frågorna, vilket framgår i resultatet för flickorna.