### Tar bort observationer som inte är tjej eller killedf<-df%>%filter(!grepl("annan könsidentitet|vill inte svara", tolower(q3)))df<-df%>%filter(!is.na(q3))### Byter namn på demografiska variablercount(df, q3)
# A tibble: 2 × 2
q3 n
<chr> <int>
1 Kille 671
2 Tjej 719
Code
count(df, q1)
# A tibble: 2 × 2
q1 n
<chr> <int>
1 År 2 på gymnasiet 744
2 Årskurs 9 i grundskolan 646
Code
count(df, q6)
# A tibble: 5 × 2
q6 n
<chr> <int>
1 Annat boende 19
2 Bostadsrätt 333
3 Hyreslägenhet 266
4 Villa/parhus/radhus 767
5 <NA> 5
# A tibble: 2 × 2
Kön n
<chr> <int>
1 Kille 671
2 Tjej 719
Code
count(df, q7, q8, q9)
# A tibble: 53 × 4
q7 q8 q9 n
<chr> <chr> <chr> <int>
1 I Sverige I Sverige I Sverige 863
2 I Sverige I Sverige I ett land i övriga Europa 37
3 I Sverige I Sverige I ett land i övriga Norden 16
4 I Sverige I Sverige I ett land i övriga världen 77
5 I Sverige I Sverige <NA> 1
6 I Sverige I ett land i övriga Europa I Sverige 29
7 I Sverige I ett land i övriga Europa I ett land i övriga Europa 28
8 I Sverige I ett land i övriga Europa I ett land i övriga världen 6
9 I Sverige I ett land i övriga Norden I Sverige 13
10 I Sverige I ett land i övriga Norden I ett land i övriga Europa 3
# ℹ 43 more rows
Code
### Koda om kön till numerisk + rätt etiketter# d$Kön<-recode(d$Kön,"'Tjej'=1;'Kille'=2",as.factor=FALSE)# d$Kön <- labelled(d$Kön, labels = c("Tjej" = 1, "Kille" = 2))# # d$Årskurs<-recode(d$Årskurs,"'Årskurs 9 i grundskolan'=1;'År 2 på gymnasiet'=2",as.factor=FALSE)# d$Åsrkurs <- labelled(d$Årskurs, labels = c("årskurs 9" = 1, "år 2" = 2))d$Kön<-factor(d$Kön)d$Årskurs<-factor(d$Årskurs, labels =c("Åk 9","Gy 2"))
Code
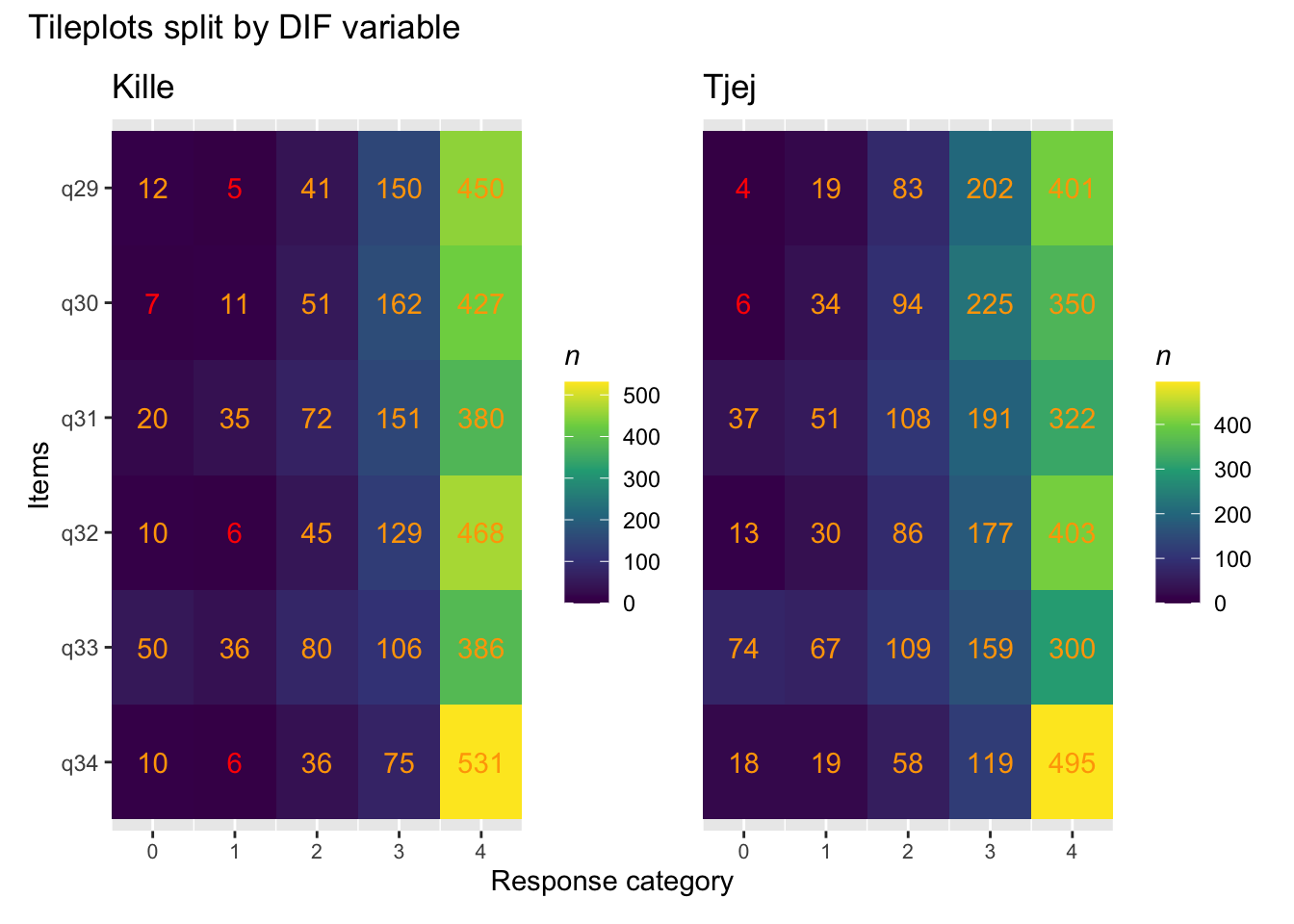
RIdifTileplot<-function(data, dif_var){if(is.factor(dif_var)==FALSE){if(n_distinct(dif_var)>12){stop("More than 12 DIF levels are not allowed")}else{dif_var<-as.factor(dif_var)}}difplots<-data%>%add_column(dif ={{dif_var}})%>%split(.$dif)%>%map(~RItileplot(.x%>%select(!dif))+labs(title =.x$dif))plots<-patchwork::wrap_plots(difplots, axes ="collect", guides =NULL)+patchwork::plot_annotation(title ="Tileplots split by DIF variable")return(plots)}
4.2 Välbefinnande
Code
count(df, q13, q20)
# A tibble: 29 × 3
q13 q20 n
<chr> <chr> <int>
1 Aldrig Lika bra 1
2 Aldrig Lite bättre 2
3 Aldrig Lite sämre 5
4 Aldrig Mycket bättre 5
5 Aldrig Mycket sämre 8
6 Ganska ofta Lika bra 203
7 Ganska ofta Lite bättre 161
8 Ganska ofta Lite sämre 66
9 Ganska ofta Mycket bättre 114
10 Ganska ofta Mycket sämre 12
# ℹ 19 more rows
# A tibble: 25 × 3
q21 q28 n
<chr> <chr> <int>
1 Aldrig/sällan En eller två dagar 262
2 Aldrig/sällan Flera dagar 112
3 Aldrig/sällan Inte besvärats alls 470
4 Aldrig/sällan Mer än hälften av dagarna 32
5 Aldrig/sällan Nästan varje dag 25
6 Aldrig/sällan <NA> 2
7 Ganska ofta En eller två dagar 30
8 Ganska ofta Flera dagar 29
9 Ganska ofta Inte besvärats alls 7
10 Ganska ofta Mer än hälften av dagarna 10
# ℹ 15 more rows
Code
psf<-c("q21", "q22", "q23", "q24", "q25", "q26", "q27", "q28")# Koda om till numeriska + etiktter. Låga värden = låg riskd<-d%>%mutate(across(q21:q24, ~recode(.x,"'Aldrig/sällan'=0; 'Ibland'=1; 'Ganska ofta'=2; 'Mycket ofta'=3", as.factor =FALSE)))%>%mutate(across(q21:q24, ~labelled(.x, labels =c("Aldrig/sällan"=0,"Ibland"=1,"Ganska ofta"=2,"Mycket ofta"=3))))d<-d%>%mutate(across(q25:q28, ~recode(.x,"'Inte besvärats alls'=0; 'En eller två dagar'=1; 'Flera dagar'=2; 'Mer än hälften av dagarna'=3; 'Nästan varje dag'=4", as.factor =FALSE)))%>%mutate(across(q25:q28, ~labelled(.x, labels =c("Inte besvärats alls"=0,"En eller två dagar"=1,"Flera dagar"=2,"Mer än hälften av dagarna"=3, "Nästan varje dag"=4))))#d$q20<-recode(d$q20,"'Mycket bättre'=0;'Lite bättre'=1; 'Lika bra'=2; 'Lite sämre'=3; 'Mycket sämre'=4",as.factor=FALSE)#d$q20 <- labelled(d$q20, labels = c("Mycket bättre" = 0, "Lite bättre" = 1, "Lika bra" = 2, "Lite sämre" = 3,"Mycket sämre" = 4))count(d, q21)
# A tibble: 6 × 2
q29 n
<chr> <int>
1 Aldrig 18
2 Ganska ofta 358
3 Ibland 126
4 Mycket ofta 856
5 Sällan 25
6 <NA> 7
Code
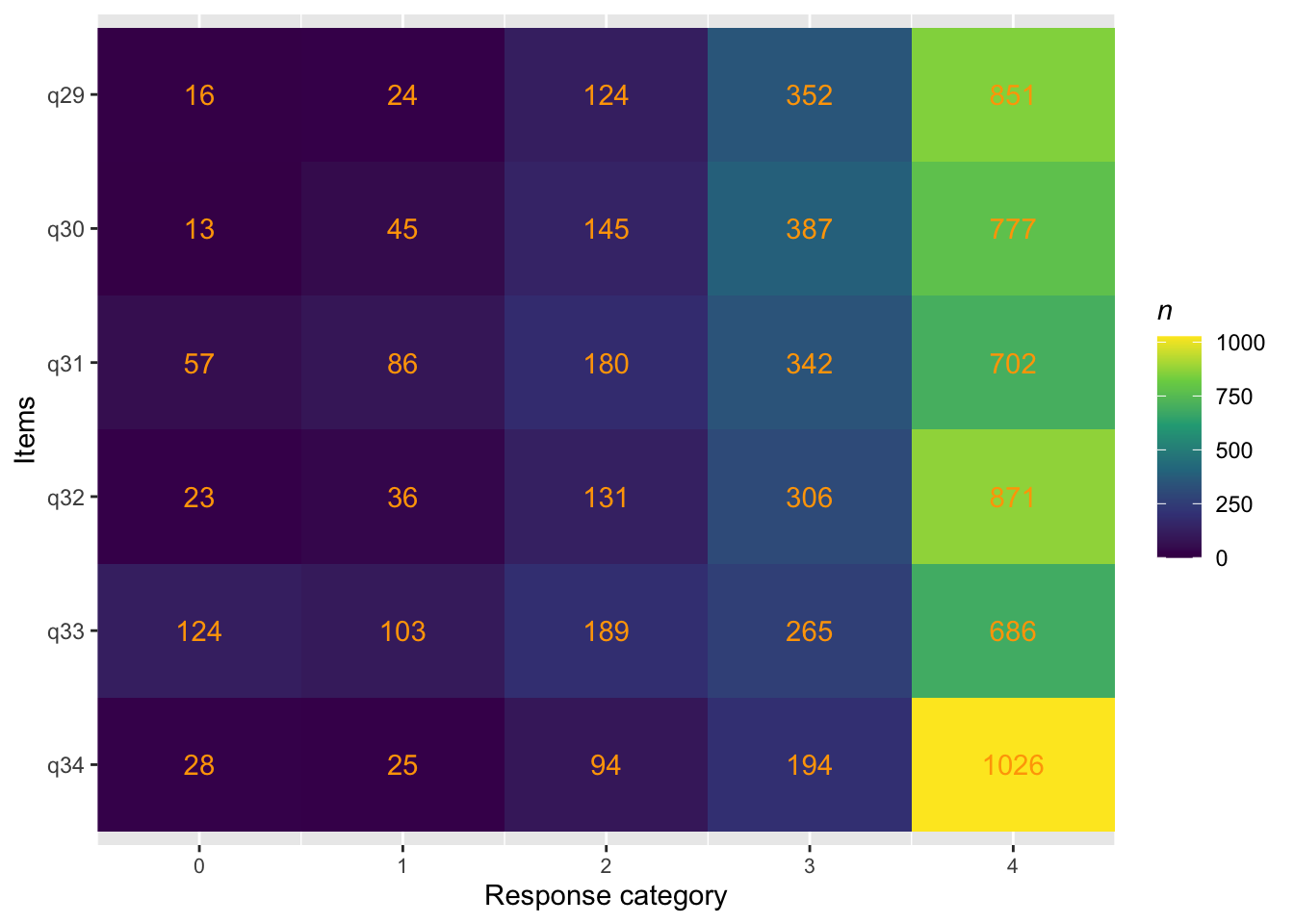
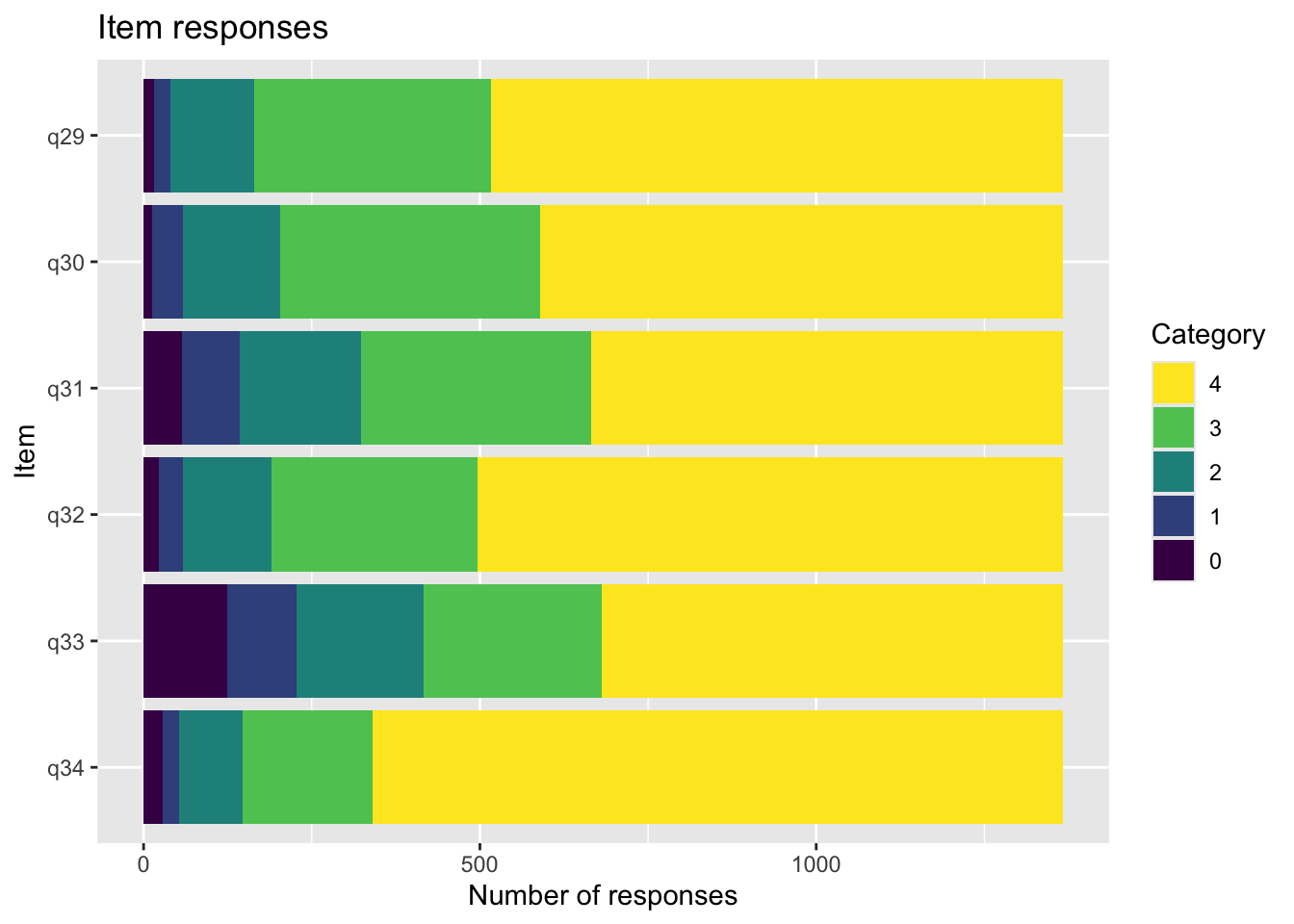
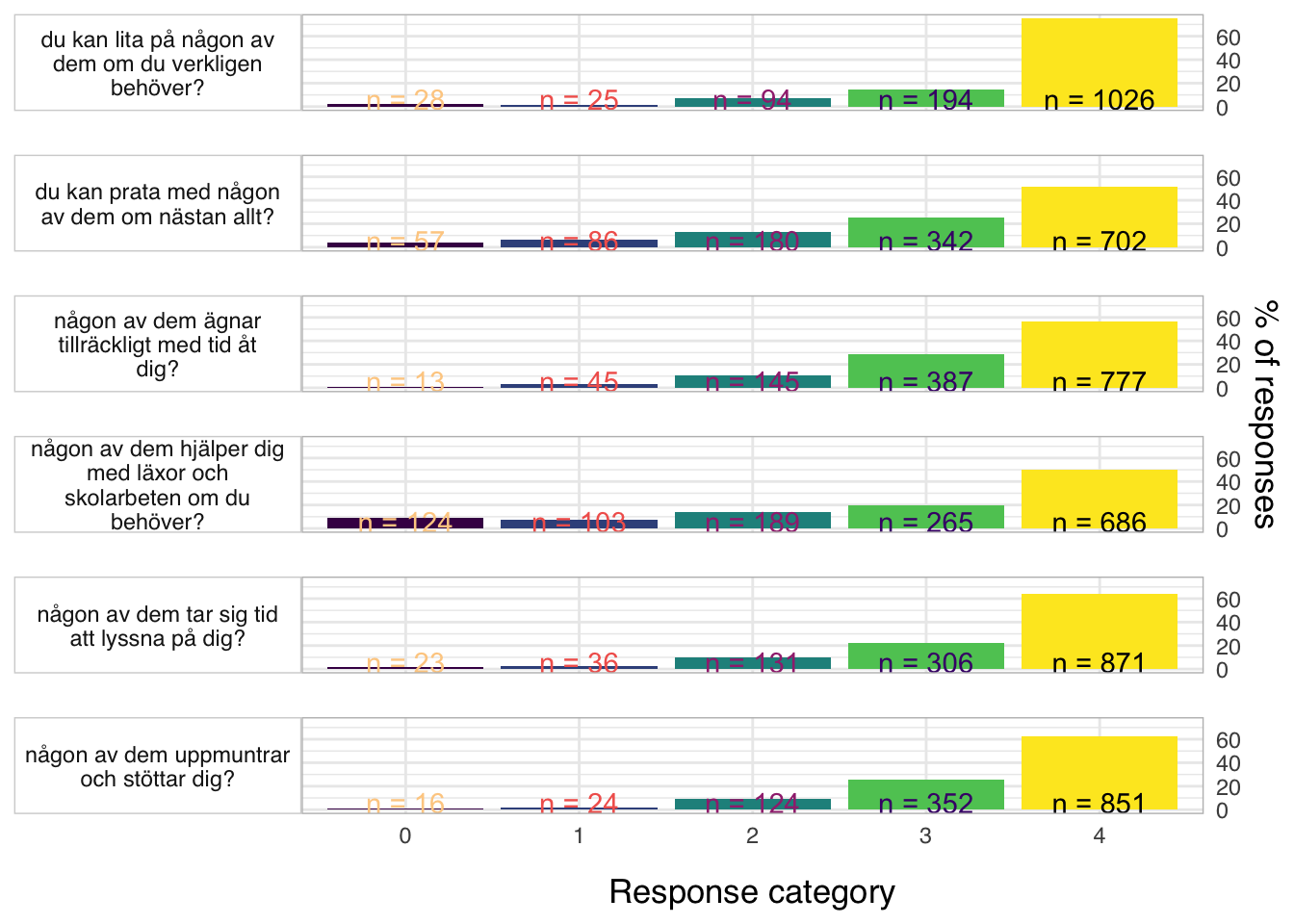
föräldrar<-c("q29", "q30", "q31", "q32", "q33", "q34")# Koda om till numeriska + etiktter. Låga värden = dålig föräldrarelationd<-d%>%mutate(across(q29:q34, ~recode(.x,"'Mycket ofta'=4; 'Ganska ofta'=3; 'Ibland'=2; 'Sällan'=1; 'Aldrig'=0", as.factor =FALSE)))%>%mutate(across(q29:q34, ~labelled(.x, labels =c("Mycket ofta"=4,"Ganska ofta"=3,"Ibland"=2,"Sällan"=1,"Aldrig"=0))))d$q35<-recode(d$q35,"'Ja, alla'=5;'Ja, de flesta'=4; 'Ja, några'=3; 'Nej, ingen'=2; 'Vet inte'=1; 'Umgås inte med kompisar på internet/mobilen'=0",as.factor=FALSE)d$q35<-labelled(d$q35, labels =c("Ja, alla"=5, "Ja, de flesta"=4, "Ja, några"=3, "Nej, ingen"=2,"Vet inte"=1, "Umgås inte med kompisar på internet/mobilen"=0))#d$q36<-recode(d$q36,"'Ja, alla'=0;'Ja, de flesta'=1; 'Ja, några'=2; 'Nej, ingen'=3; 'Vet inte'=4; 'Umgås inte med kompis/ kompisar utanför internet/mobilen'=5; 'Annat'=6",as.factor=FALSE)#d$q36 <- labelled(d$q36, labels = c("Ja, alla" = 0, "Ja, de flesta" = 1, "Ja, några" = 2, "Nej, ingen" = 3,"Vet inte" = 4, "Umgås inte med kompis/ kompisar utanför internet/mobilen" = 5, "Annat" = 6 ))count(df, q36)
# A tibble: 8 × 2
q36 n
<chr> <int>
1 Ja, alla 672
2 Ja, de flesta 577
3 Ja, några 97
4 Nej, ingen 18
5 Umgås inte med kompisar/ kompisar utanför internet/mobilen 5
6 Umgås inte med kompisar/kompisar utanför internet/mobilen 1
7 Vet inte 15
8 <NA> 5
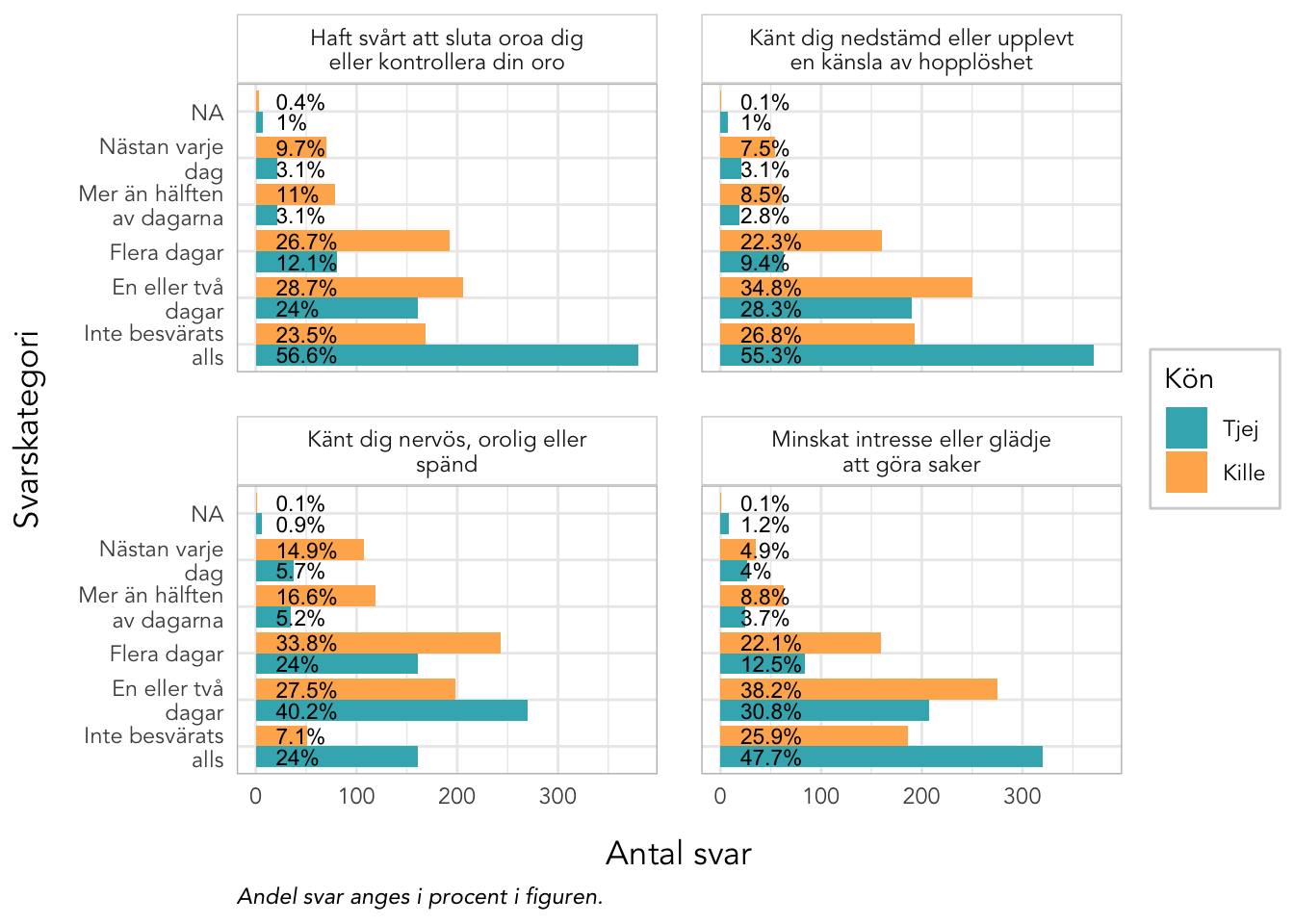
Sektionen i PDF/pappers-enkäten inleds med meningen: “NÅGRA FRÅGOR OM HUR DU MÅR”.
4.6 DF för välbefinnande
Code
# Skapa dataframe för välbefinnande utan NA:sd_v<-d%>%select(Kön, Årskurs, Bostad, any_of(välbefinnande))%>%na.omit()# Skapa DIF dfd_dif_v<-d_v%>%select(Kön, Årskurs, Bostad)%>%mutate(across(everything(), ~factor(.x)))# remove non-itemsd_v<-d_v%>%select(!c(Kön,Årskurs,Bostad))
4.7 DF för PSF
Code
# Skapa dataframe för alla PSF utan NA:sd_psf<-d%>%select(Kön, Årskurs, Bostad, any_of(psf))%>%na.omit()# Skapa DIF dfd_dif__psf<-d_psf%>%select(Kön, Årskurs, Bostad)%>%mutate(across(everything(), ~factor(.x)))# remove non-itemsd_psf<-d_psf%>%select(!c(Kön,Årskurs,Bostad))# Skapa dataframe för depressitionsitems utan NA:sd_psf_d<-d%>%select(Kön, Årskurs, Bostad, any_of(c("q22", "q23", "q24", "q27", "q28")))%>%na.omit()# Skapa DIF dfd_dif__psf_d<-d_psf_d%>%select(Kön, Årskurs, Bostad)%>%mutate(across(everything(), ~factor(.x)))# remove non-itemsd_psf_d<-d_psf_d%>%select(!c(Kön,Årskurs,Bostad))# Skapa dataframe för ångestitems utan NA:sd_psf_å<-d%>%select(Kön, Årskurs, Bostad, any_of(c("q21", "q25", "q26")))%>%na.omit()# Skapa DIF dfd_dif__psf_å<-d_psf_å%>%select(Kön, Årskurs, Bostad)%>%mutate(across(everything(), ~factor(.x)))# remove non-itemsd_psf_å<-d_psf_å%>%select(!c(Kön,Årskurs,Bostad))
4.8 DF för Föräldrar
Code
# Skapa dataframe för välbefinnande utan NA:sd_f<-d%>%select(Kön, Årskurs, Bostad, any_of(föräldrar))%>%na.omit()# Skapa DIF dfd_dif_f<-d_f%>%select(Kön, Årskurs, Bostad)%>%mutate(across(everything(), ~factor(.x)))# remove non-itemsd_f<-d_f%>%select(!c(Kön,Årskurs,Bostad))
labels_p_25_28<-c("Inte besvärats alls"=0,"En eller två dagar"=1,"Flera dagar"=2,"Mer än hälften av dagarna"=3, "Nästan varje dag"=4)names(labels_p_25_28)
[1] "Inte besvärats alls" "En eller två dagar"
[3] "Flera dagar" "Mer än hälften av dagarna"
[5] "Nästan varje dag"
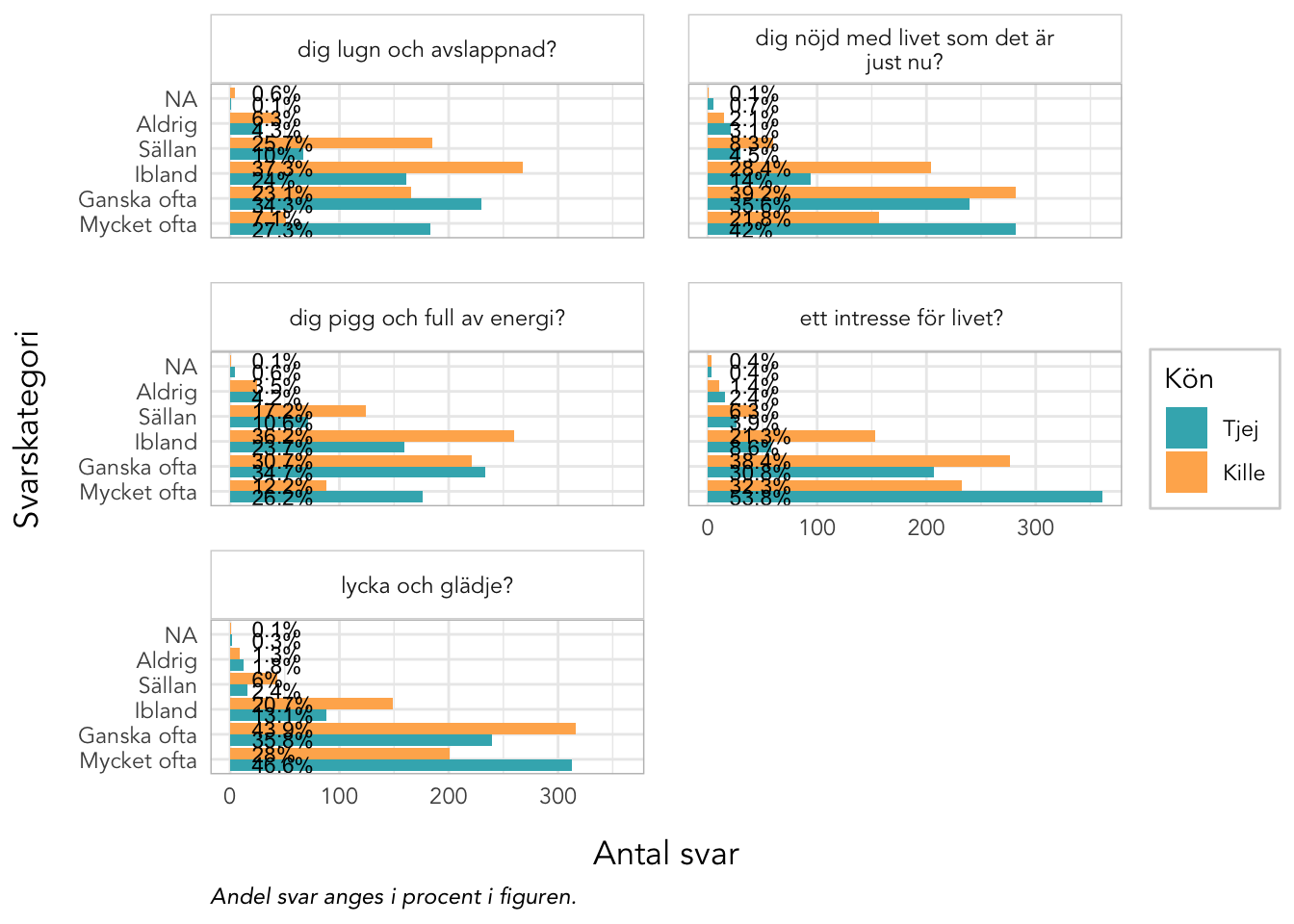
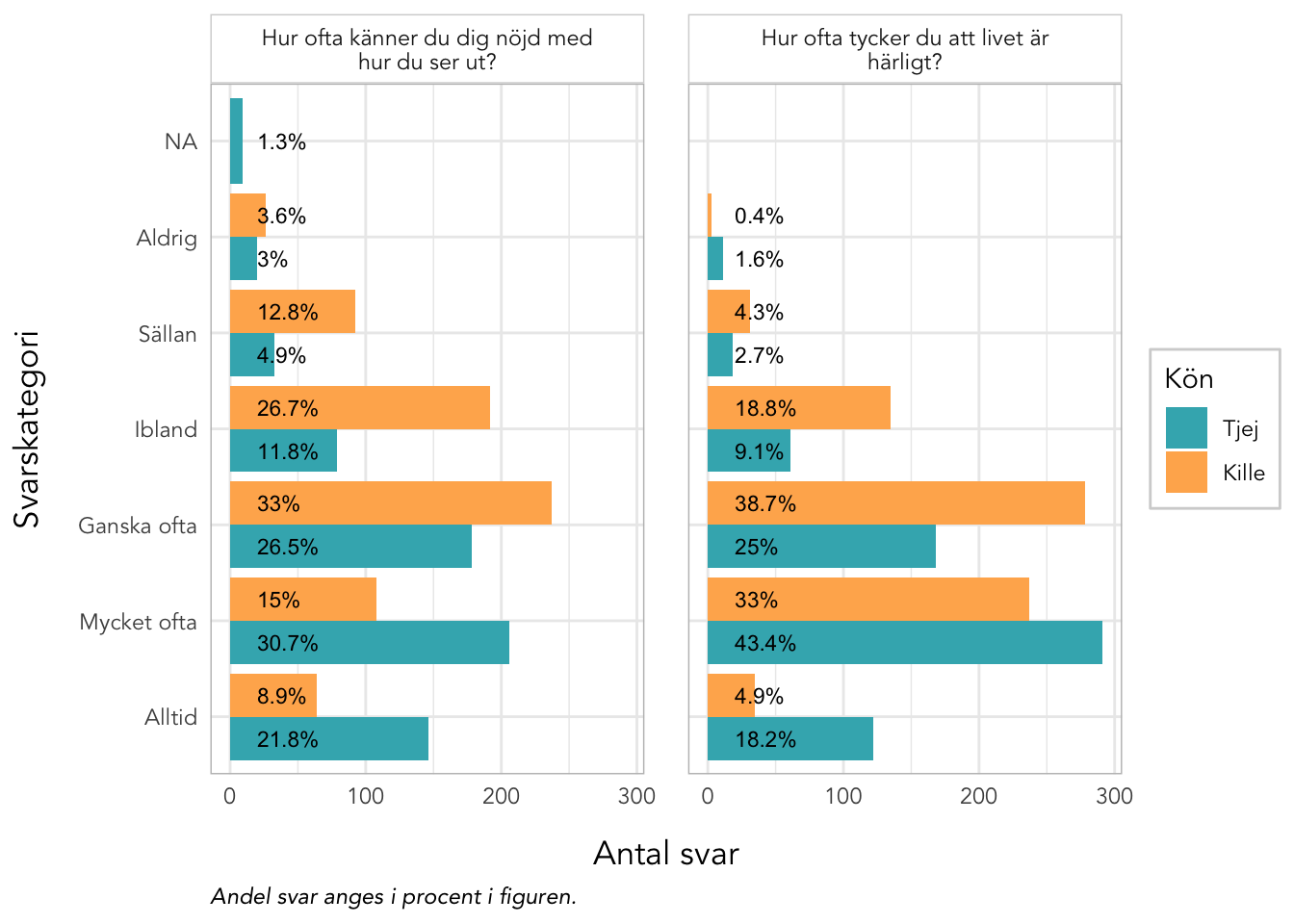
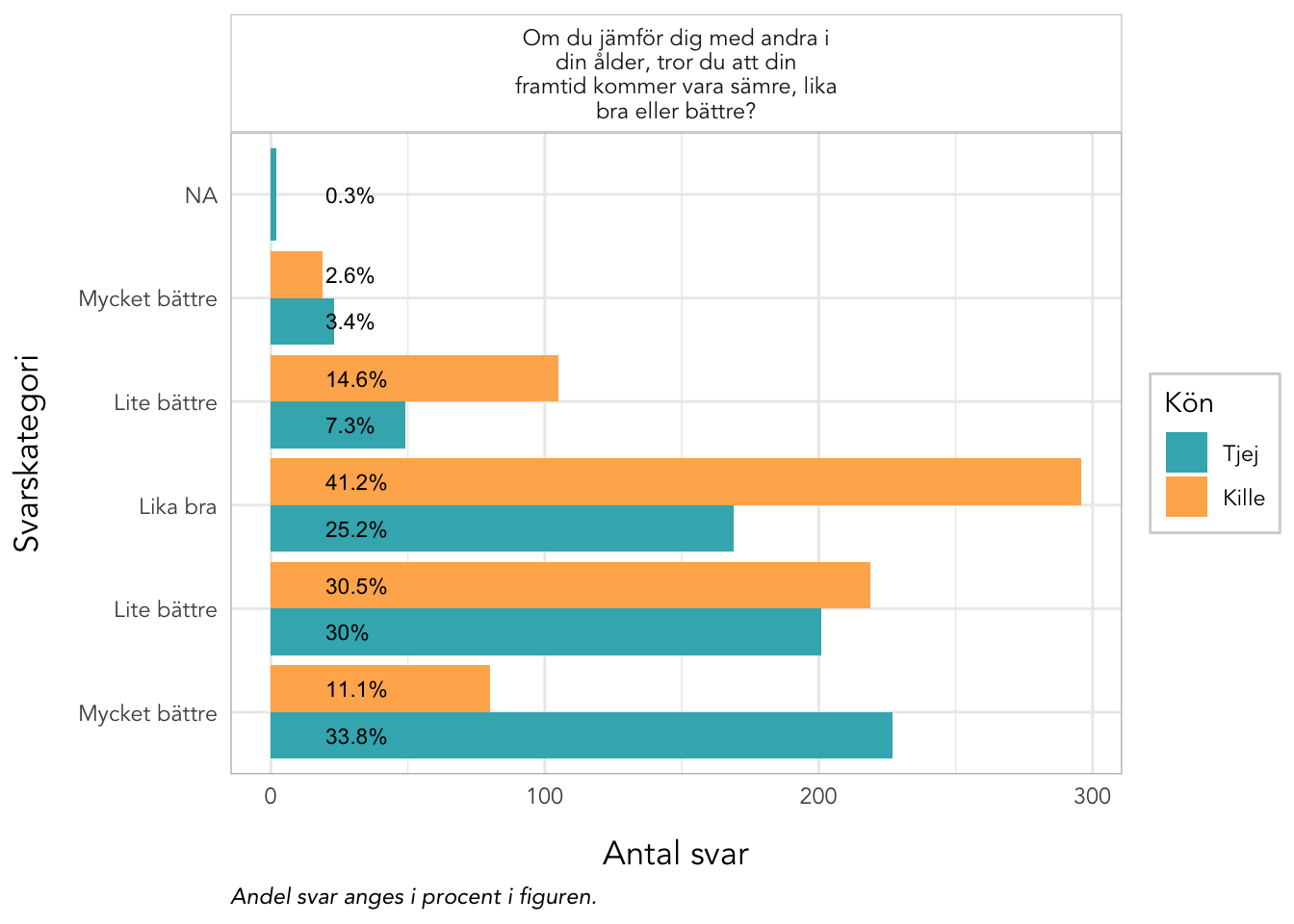
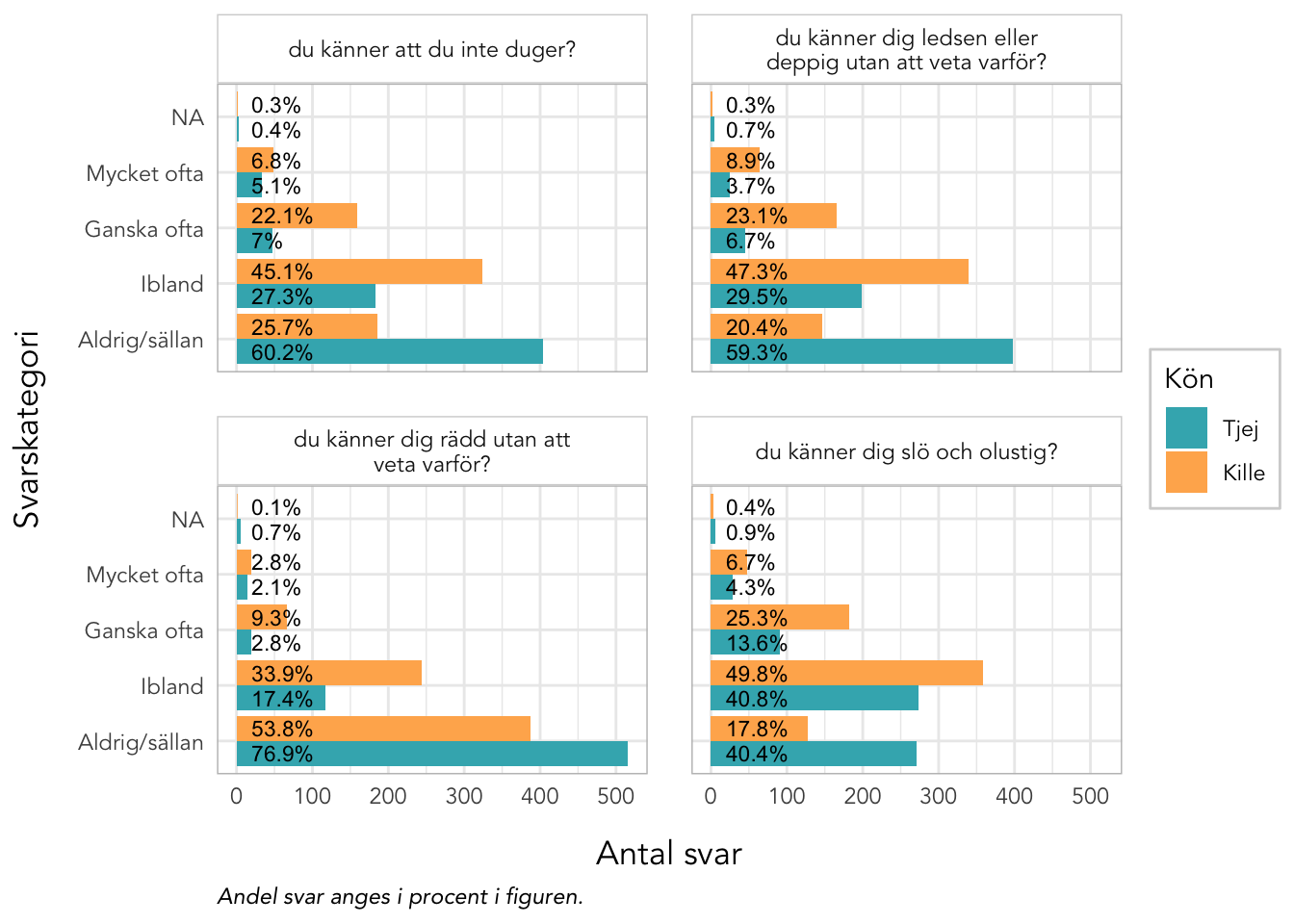
4.10 Deskriptiva data Välbefinnande
4.11 Formatering figur
Code
plot_gender<-function(data, items, kolumner=2, labelwrap=24, text_ypos=28, text_size=3){data%>%pivot_longer(all_of(items), names_to ="itemnr")%>%group_by(itemnr,Kön)%>%count(value)%>%mutate(percent =n*100/sum(n))%>%ungroup()%>%mutate(Kön =factor(Kön, labels =c("Tjej","Kille")), value =factor(value, ordered =T))%>%left_join(itemlabels, by ="itemnr")%>%ggplot(aes(x =value, y =n, fill =Kön))+geom_col(position ="dodge")+geom_text(aes(label =paste0(round(percent,1),"%"), y =text_ypos), position =position_dodge(width =0.9), angle =0, color ="black", size =text_size, hjust ="left")+facet_wrap(~item, ncol =kolumner, labeller =labeller(item =label_wrap_gen(labelwrap)))+scale_fill_gender()+theme_rise(fontfamily ="Avenir")+labs(x ="Svarskategori", y ="Antal svar", caption ="Andel svar anges i procent i figuren.")+coord_flip()}
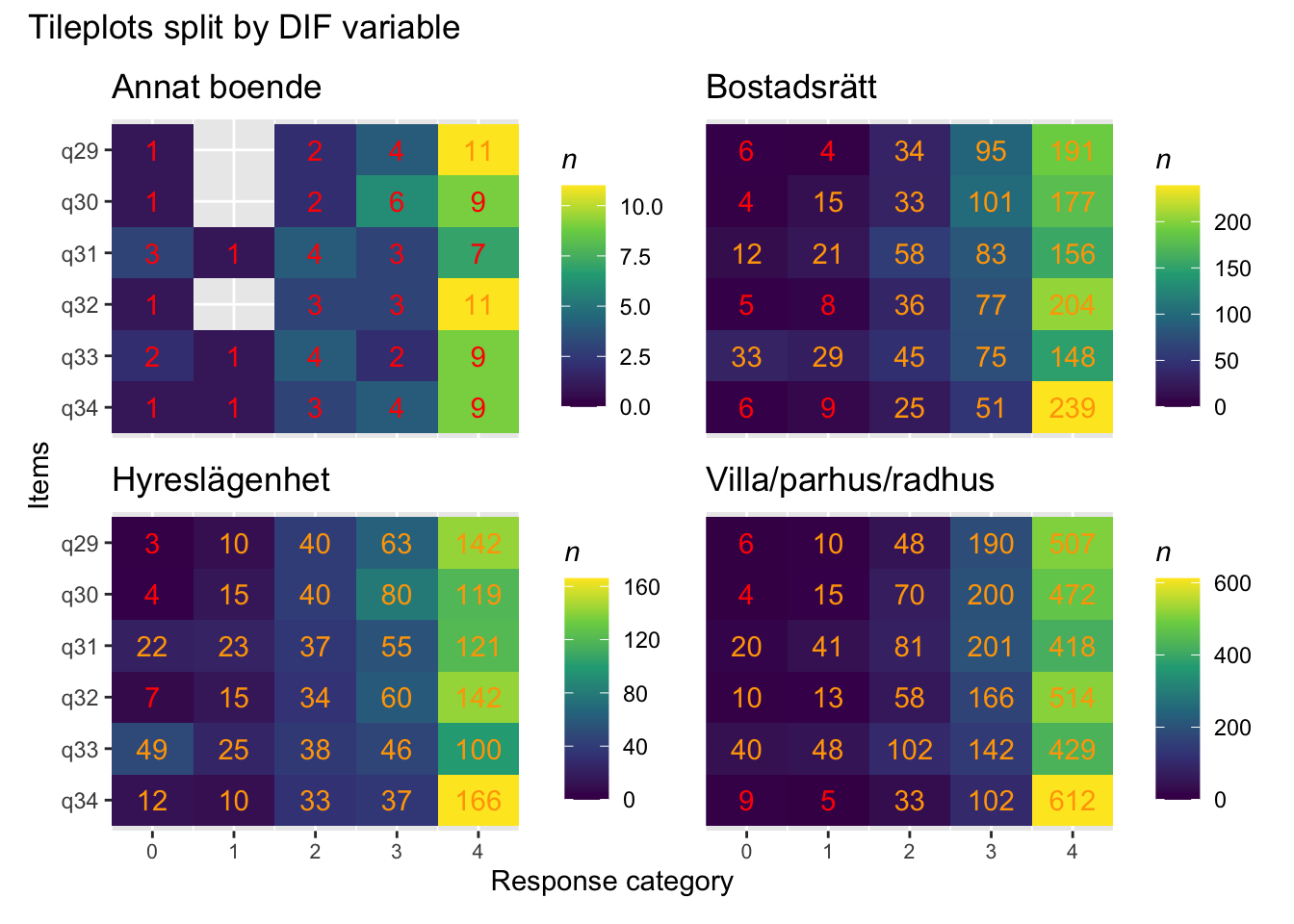
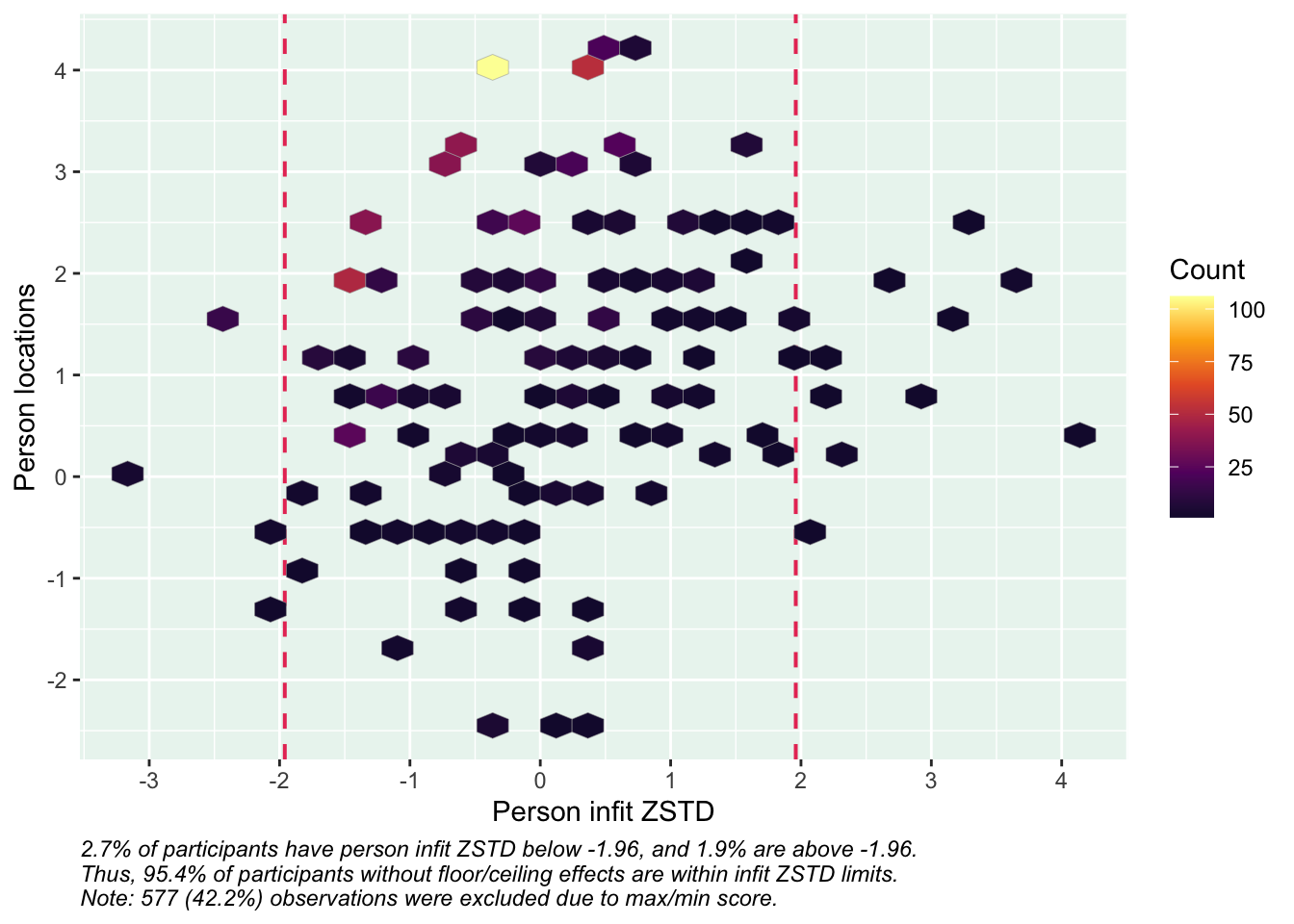
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
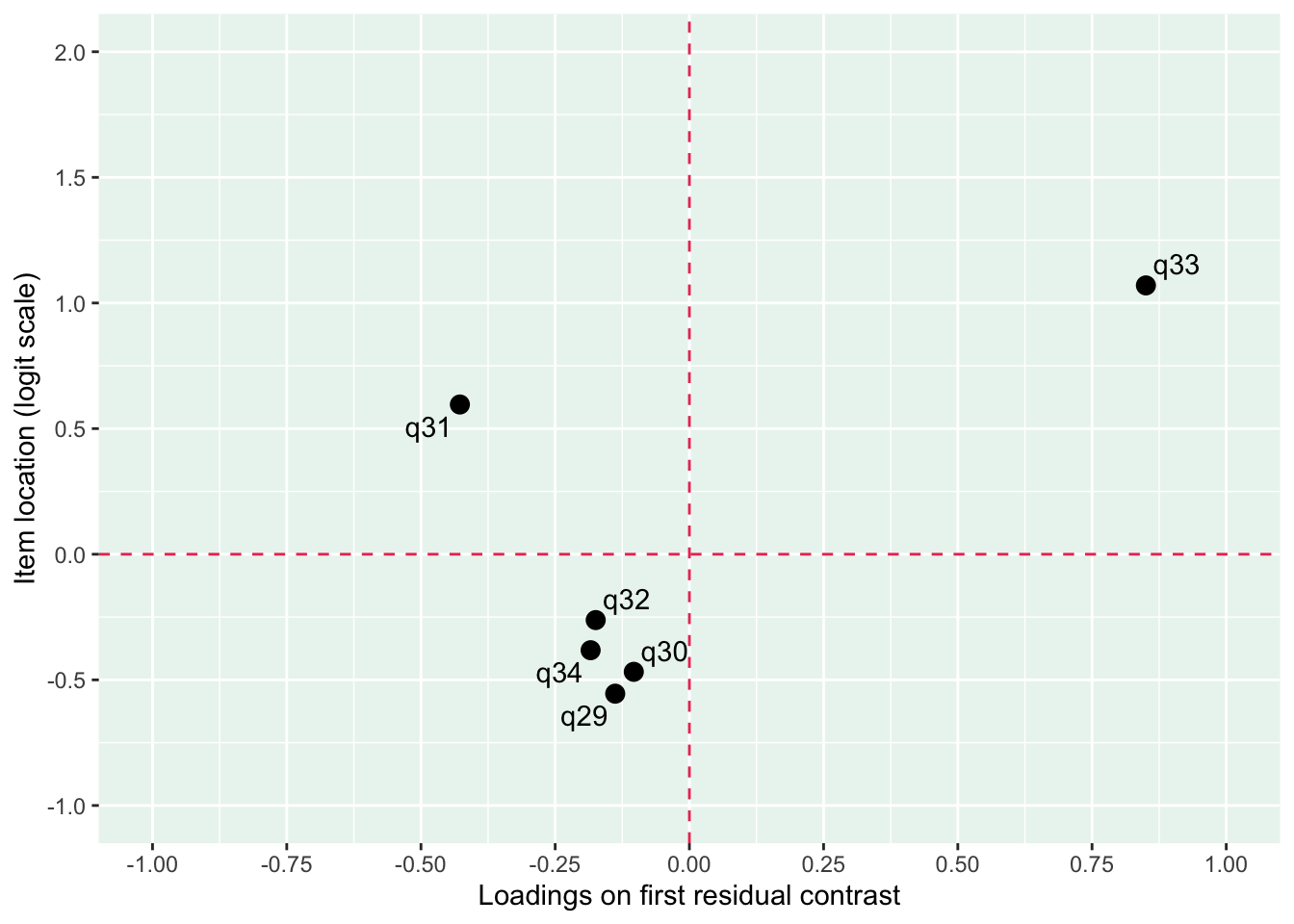
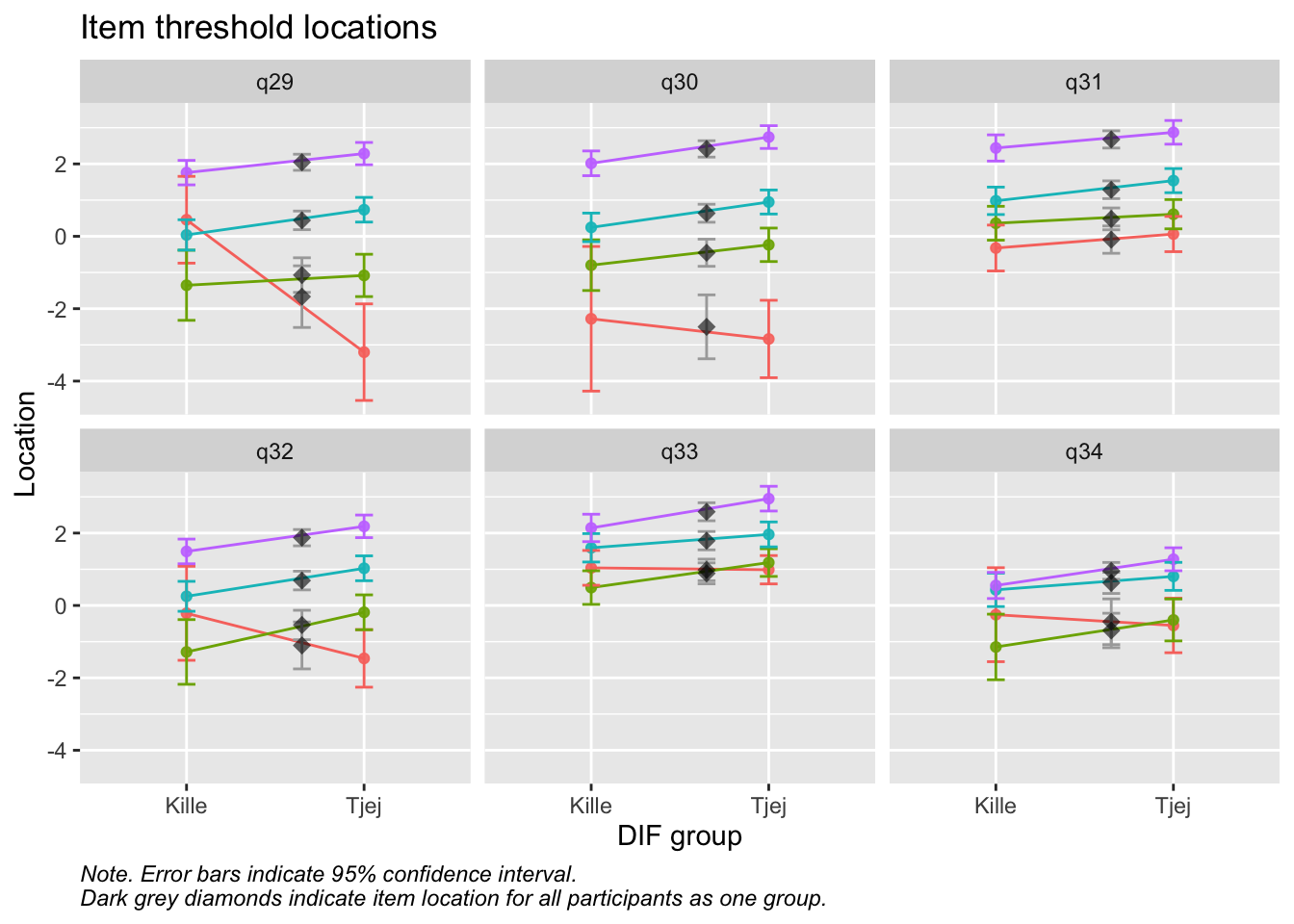
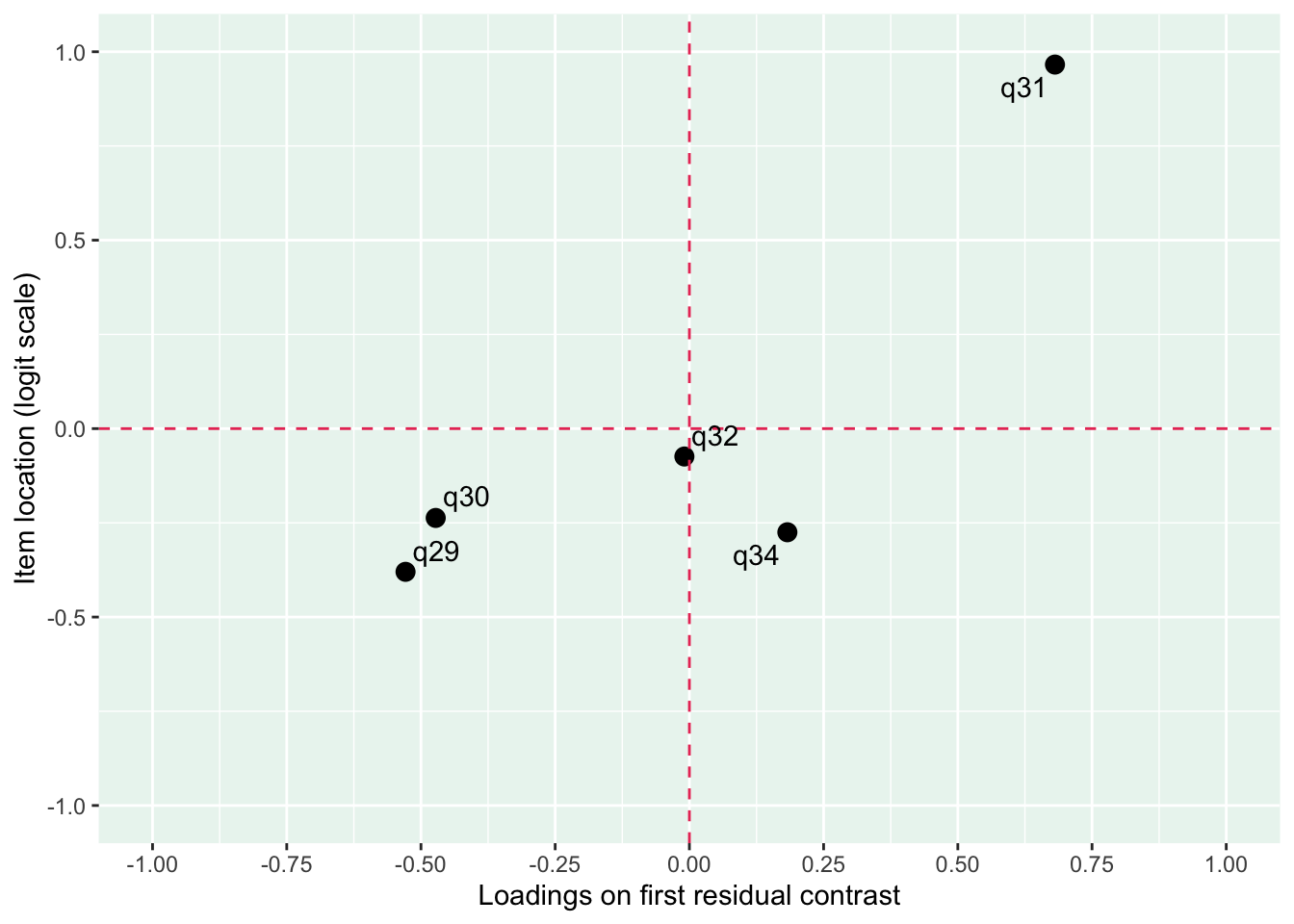
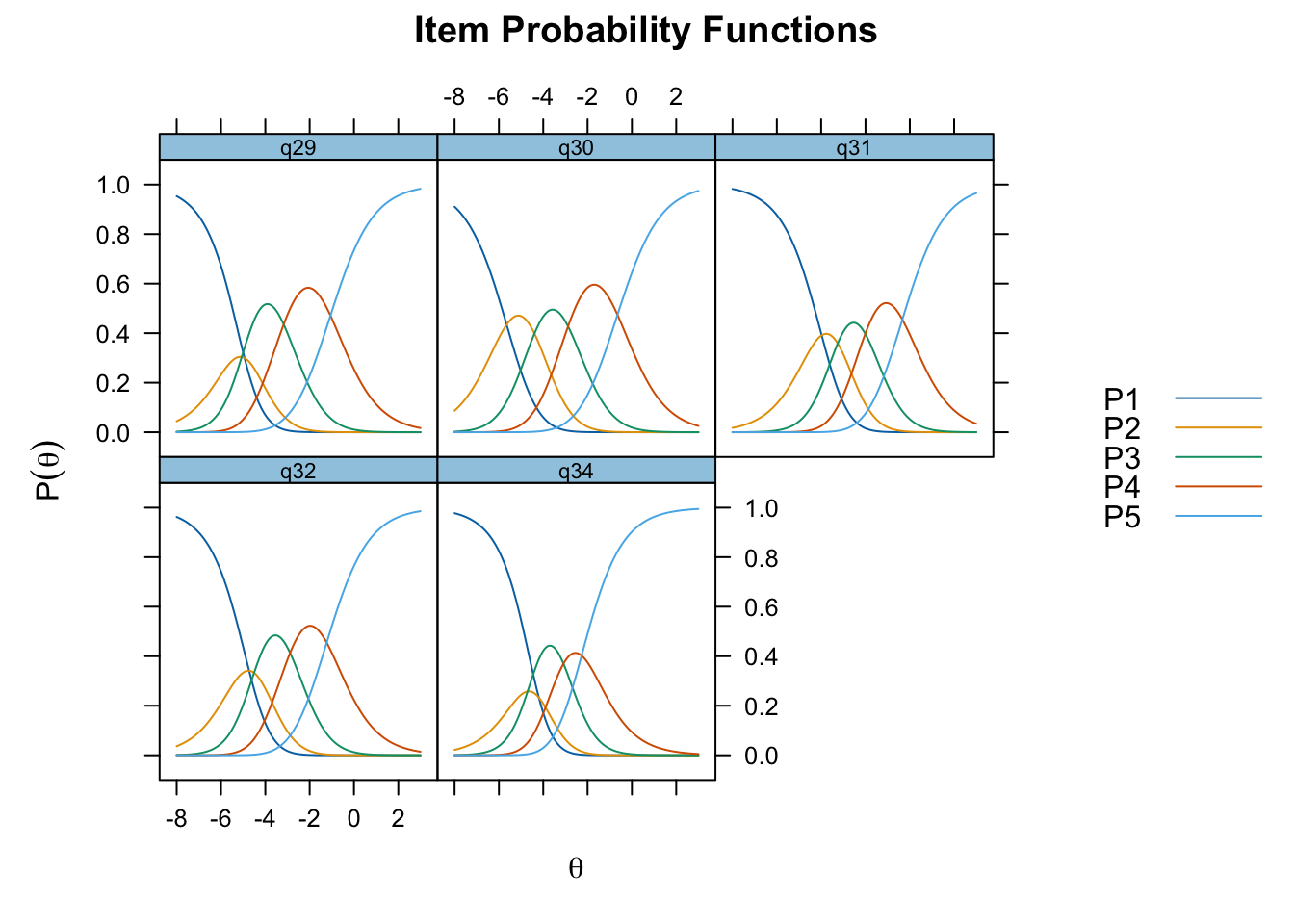
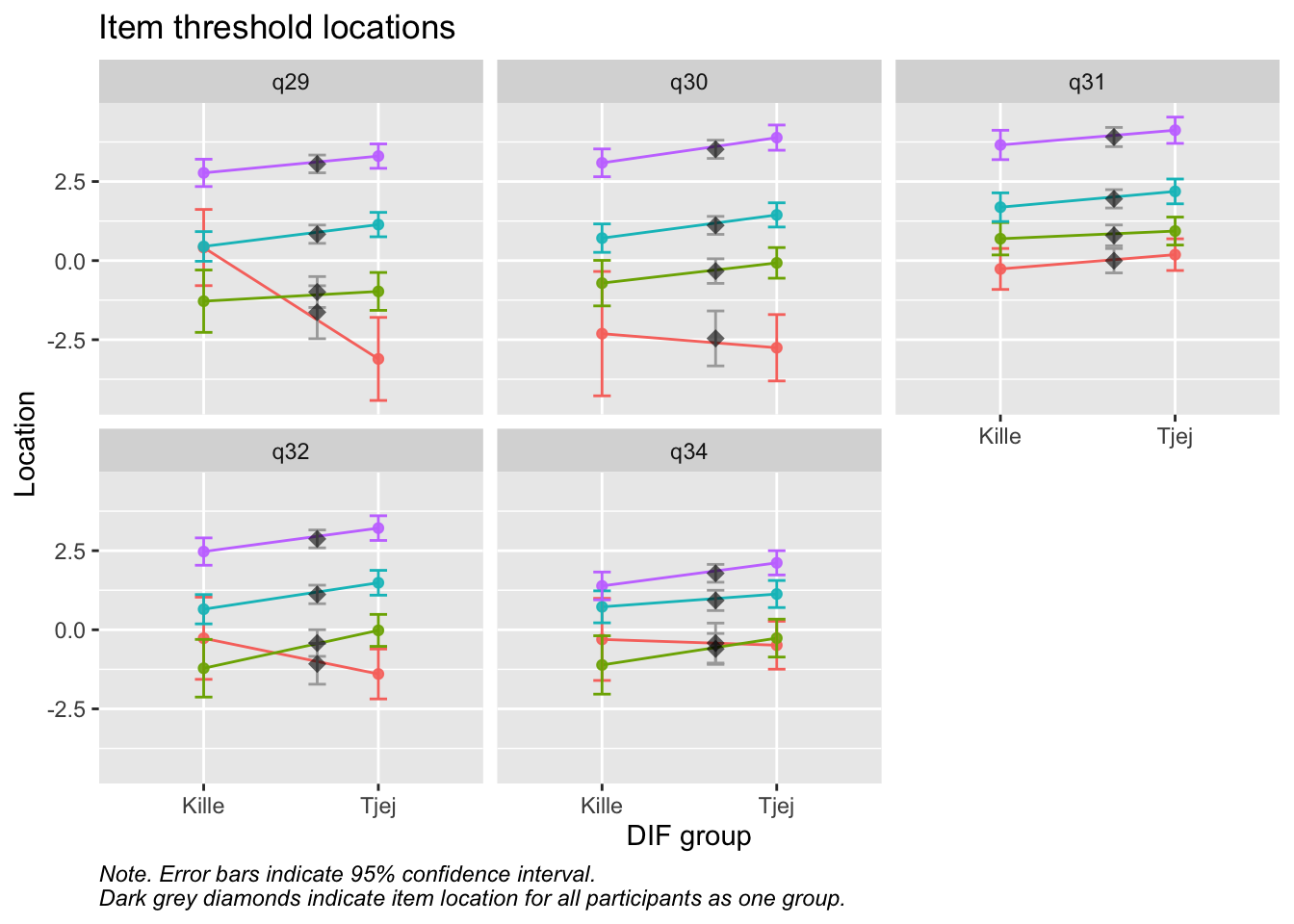
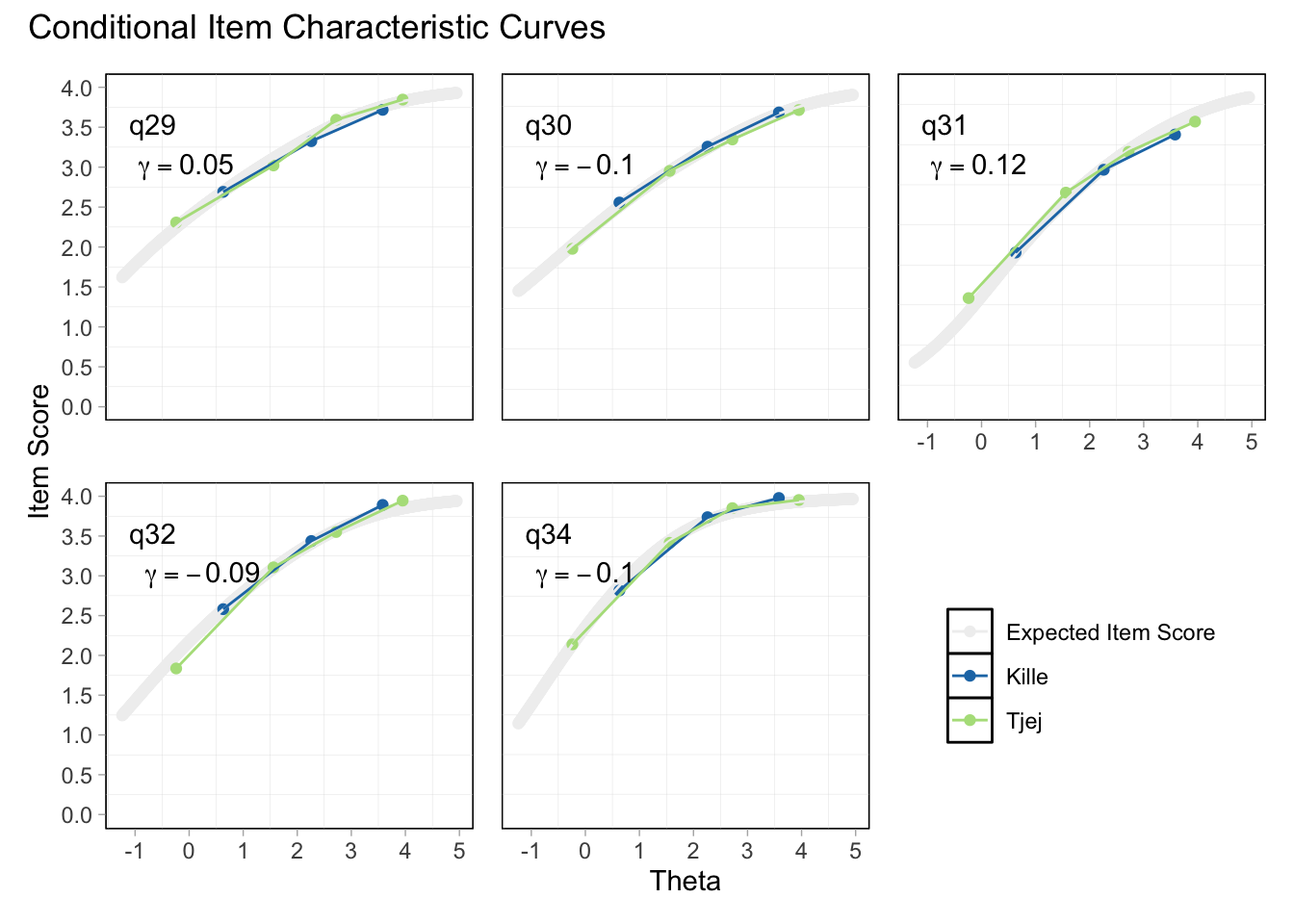
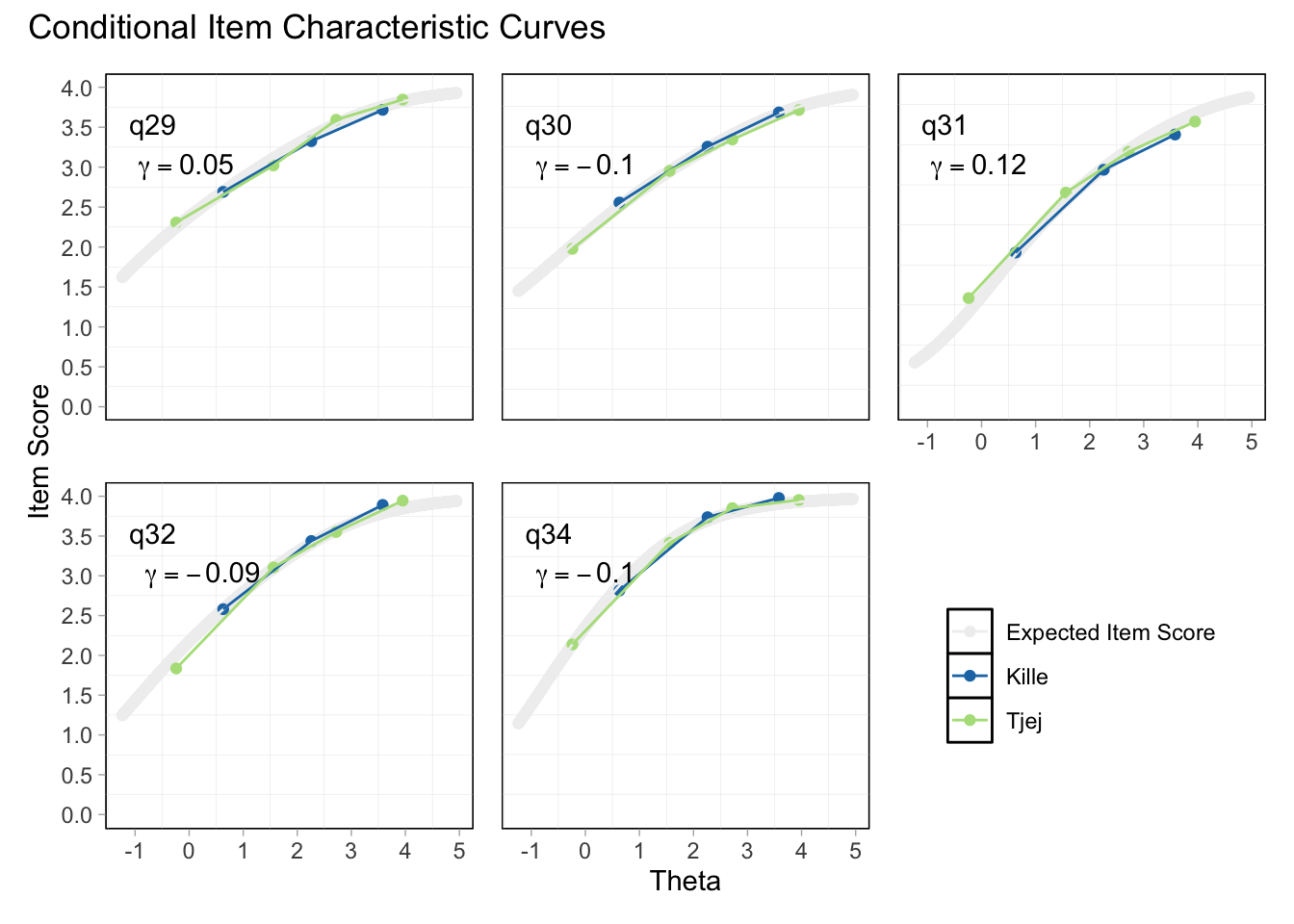
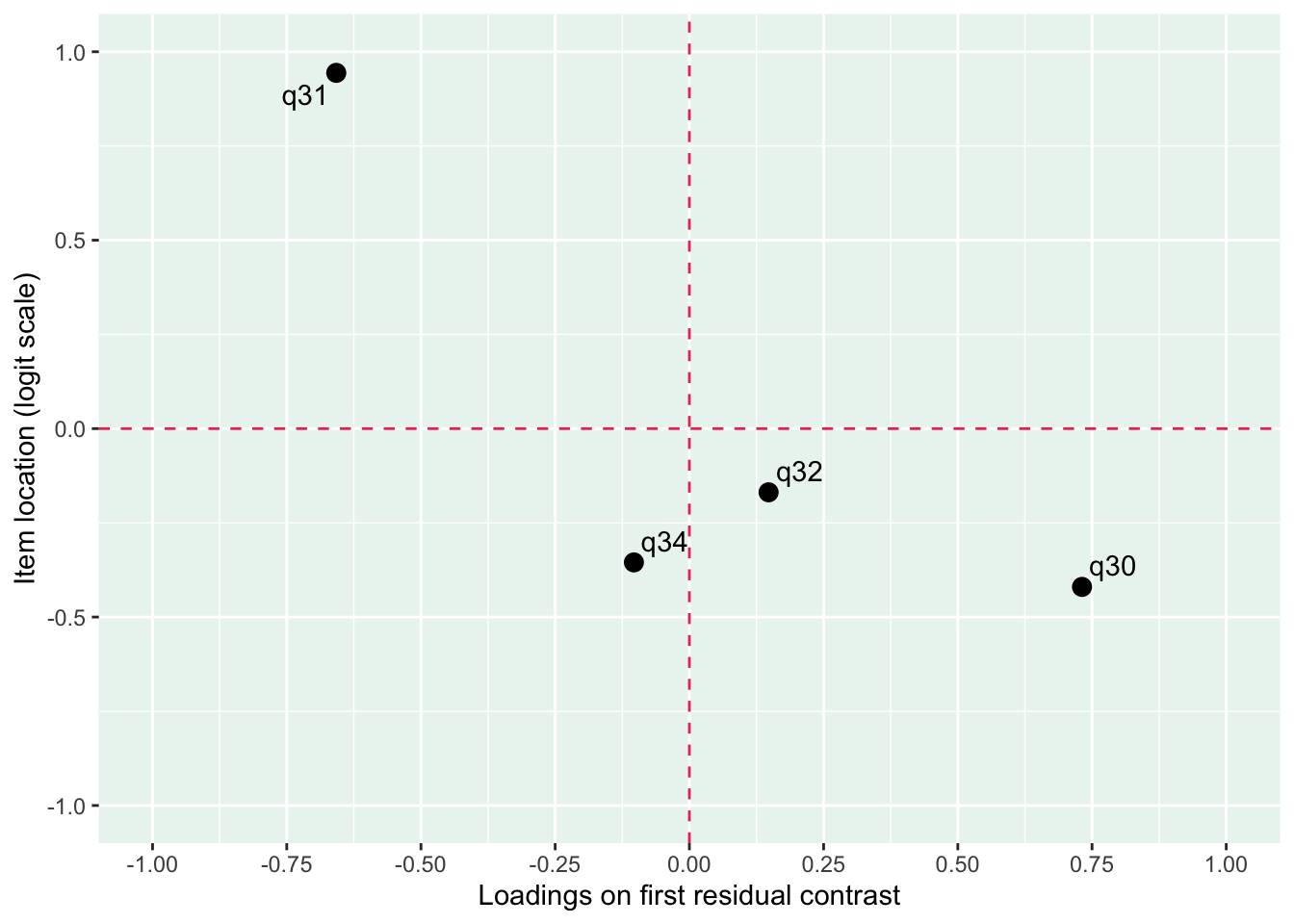
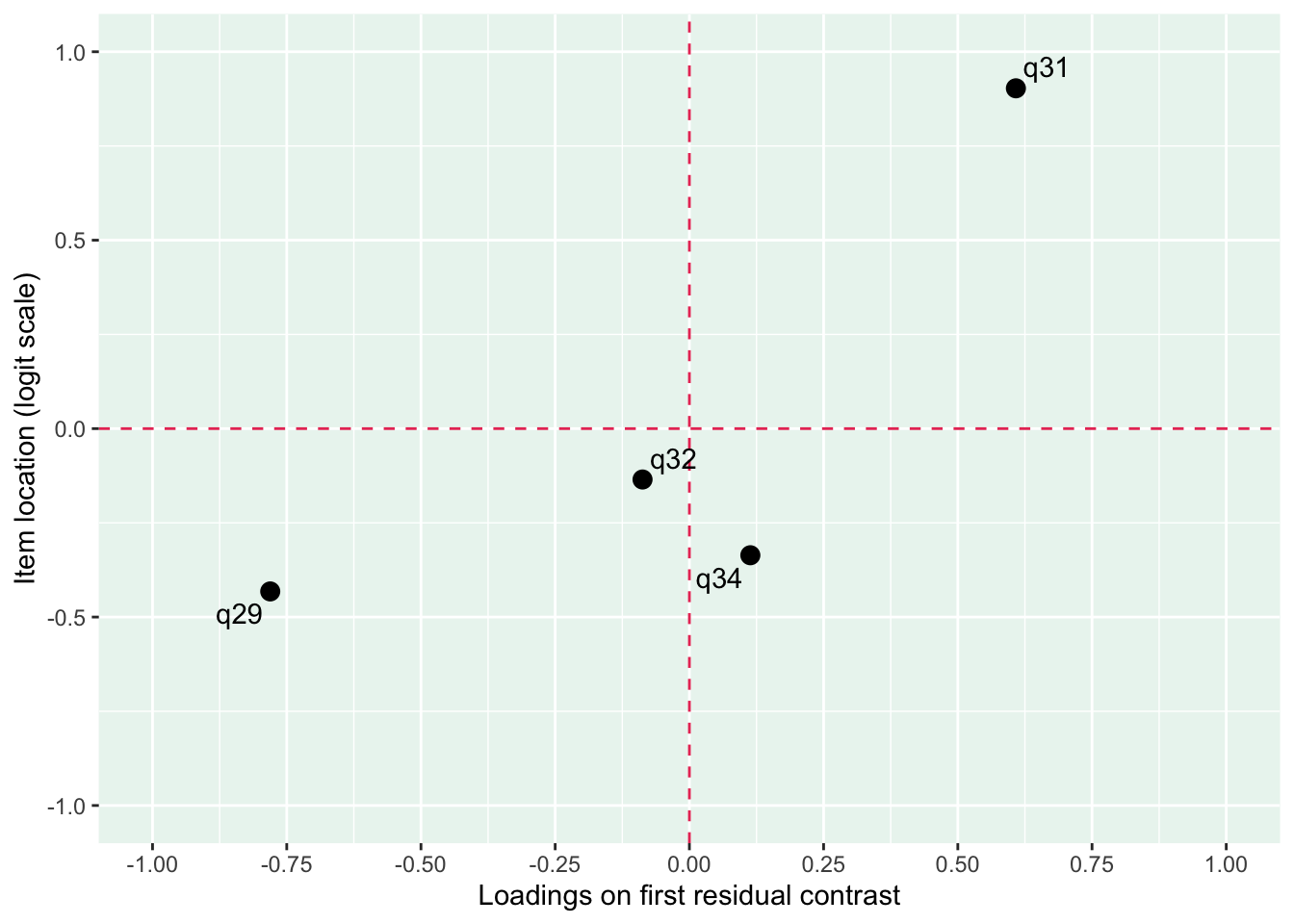
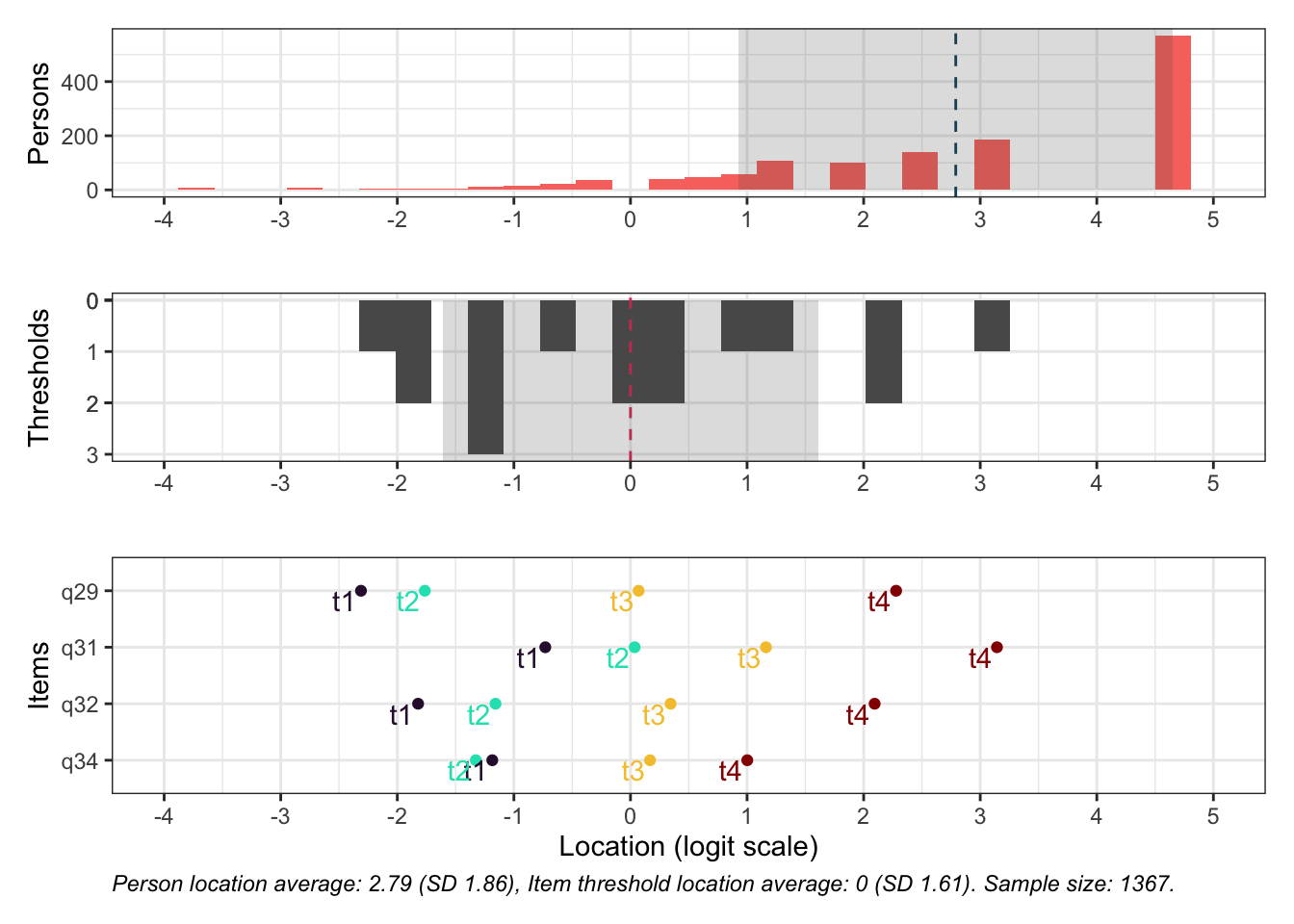
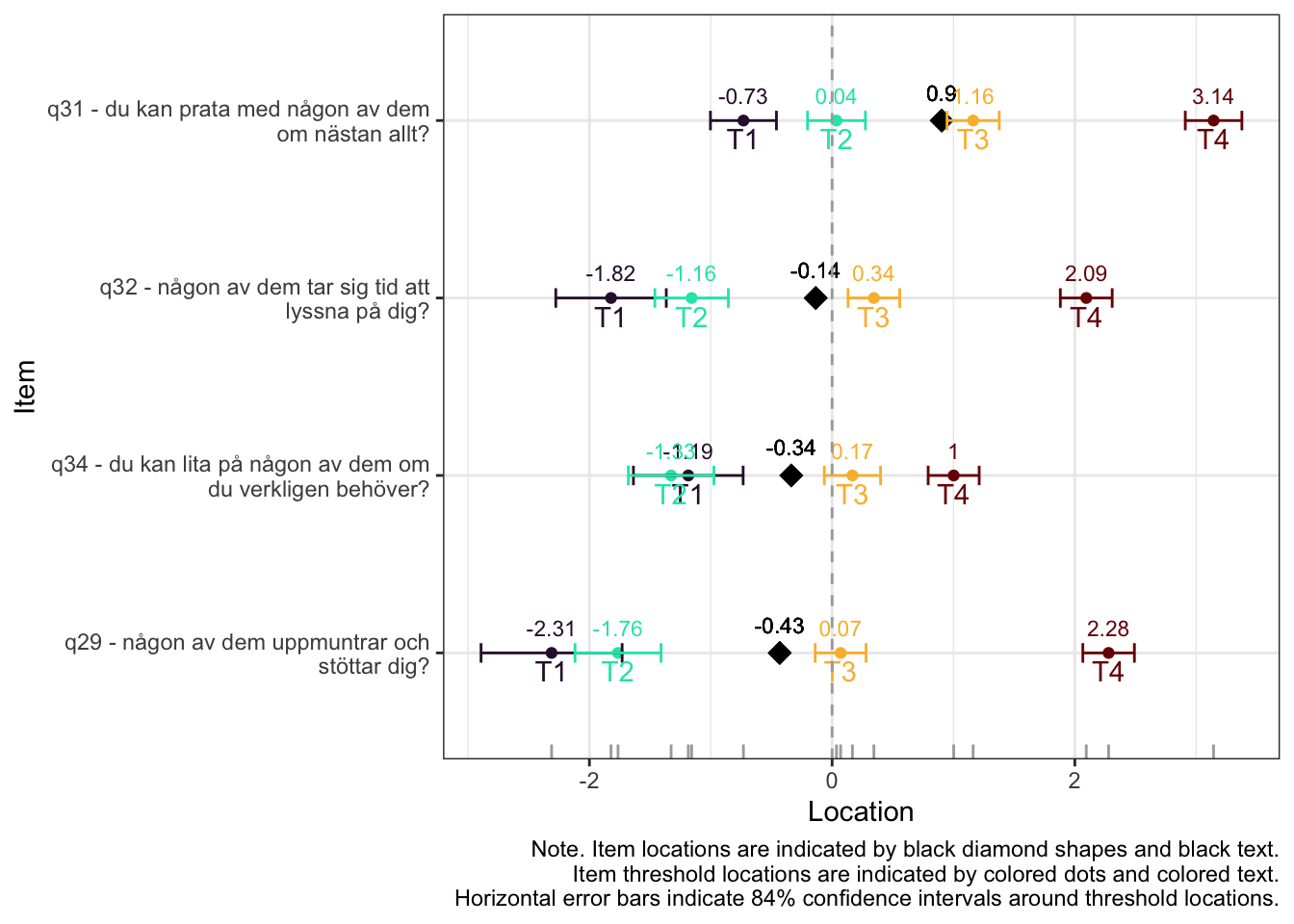
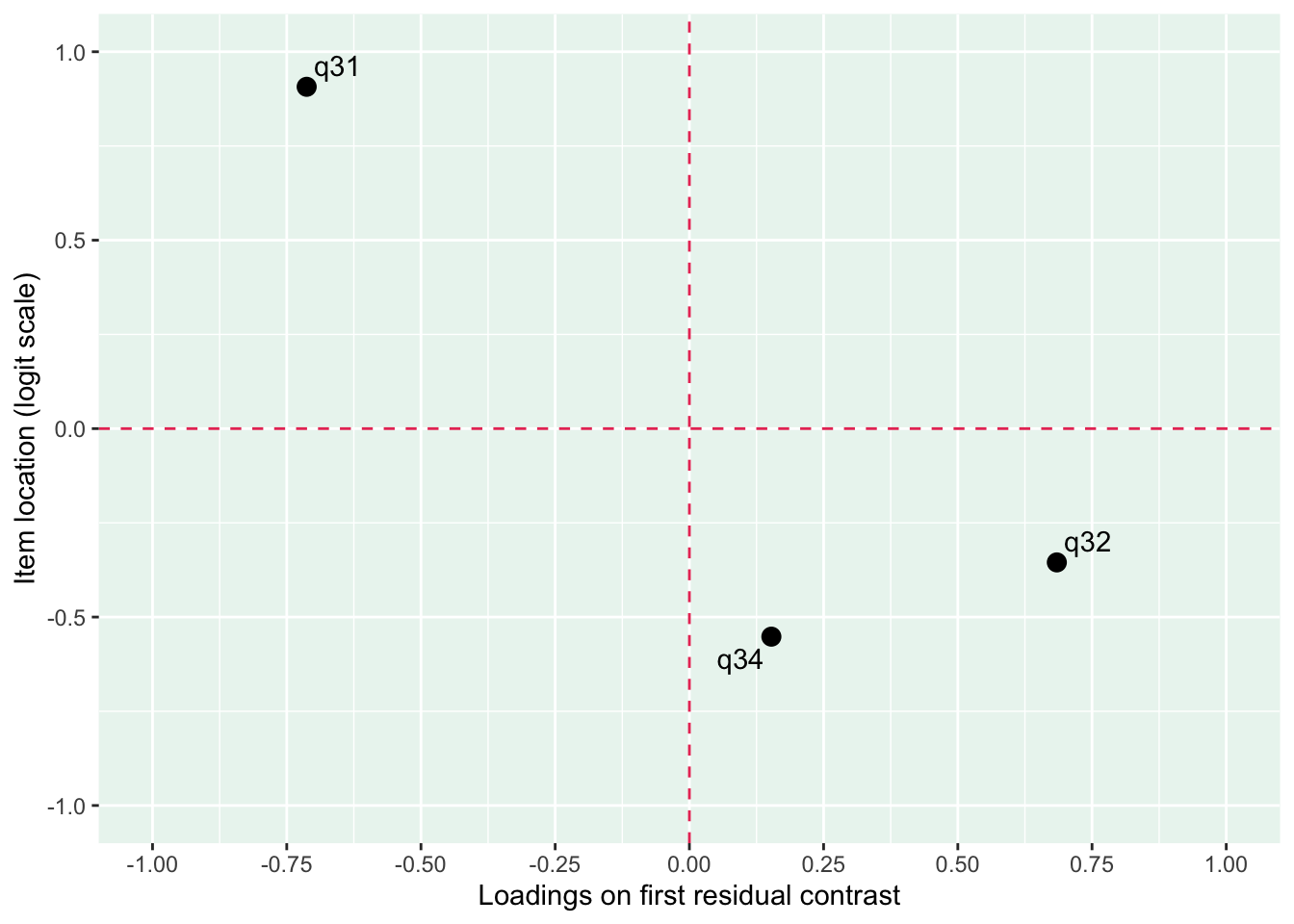
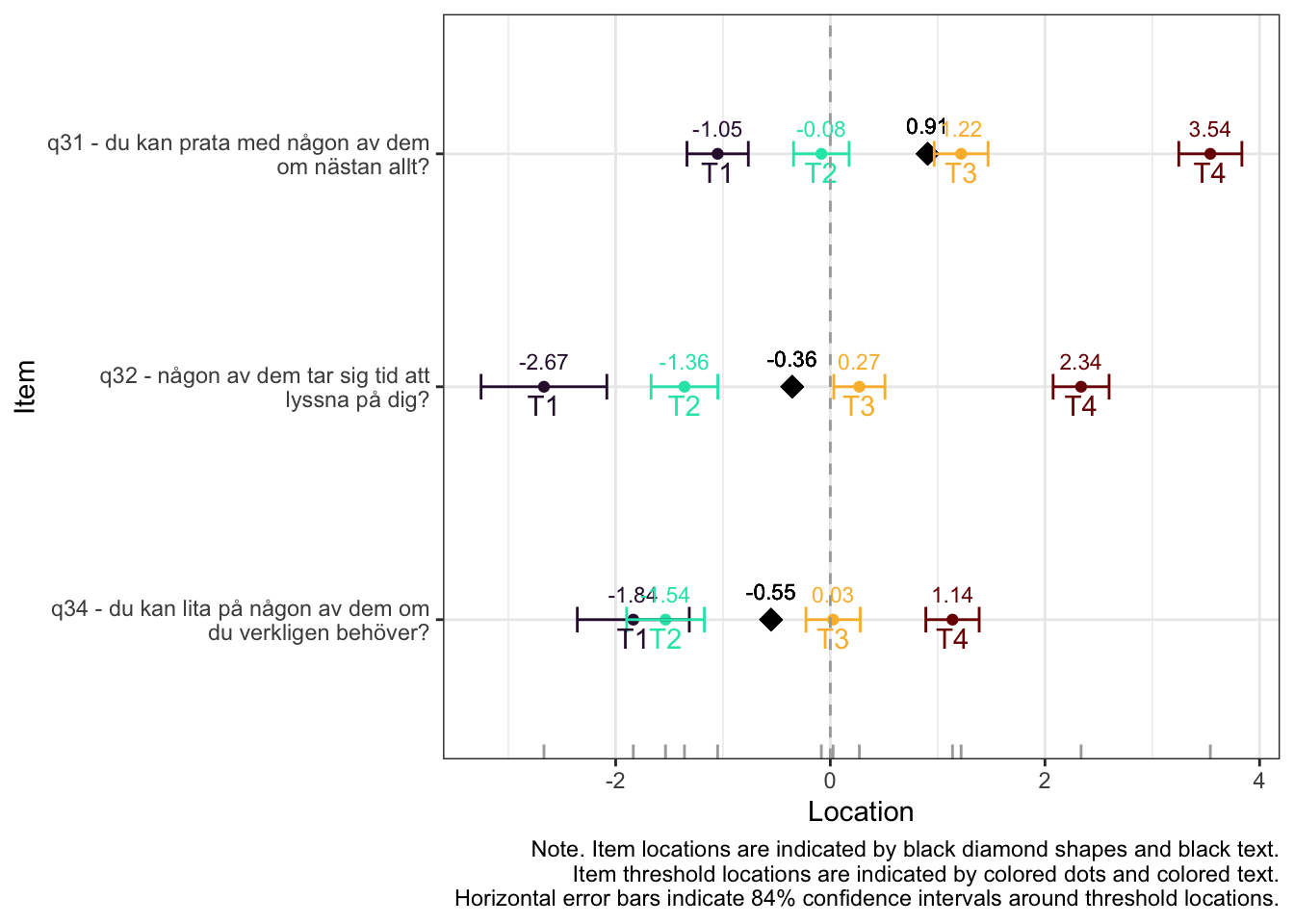
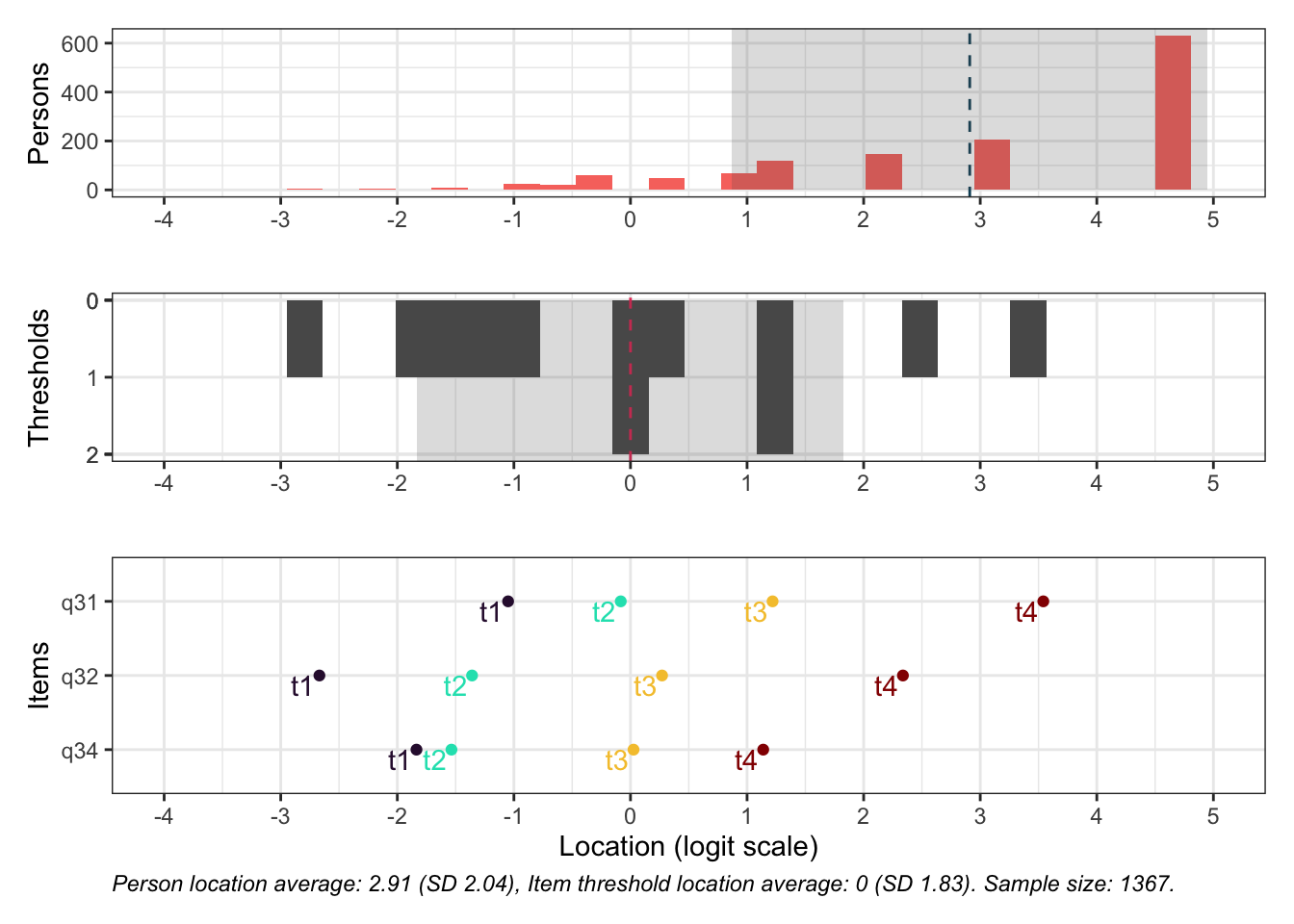
Residualkorrelation främst mellan q30 “ägnar tid” och q29 “uppmuntrar och stöttar”, men även q31 “kan prata med” och q34 “kan lita på” (övriga ligger mycket nära gränsvärdet).
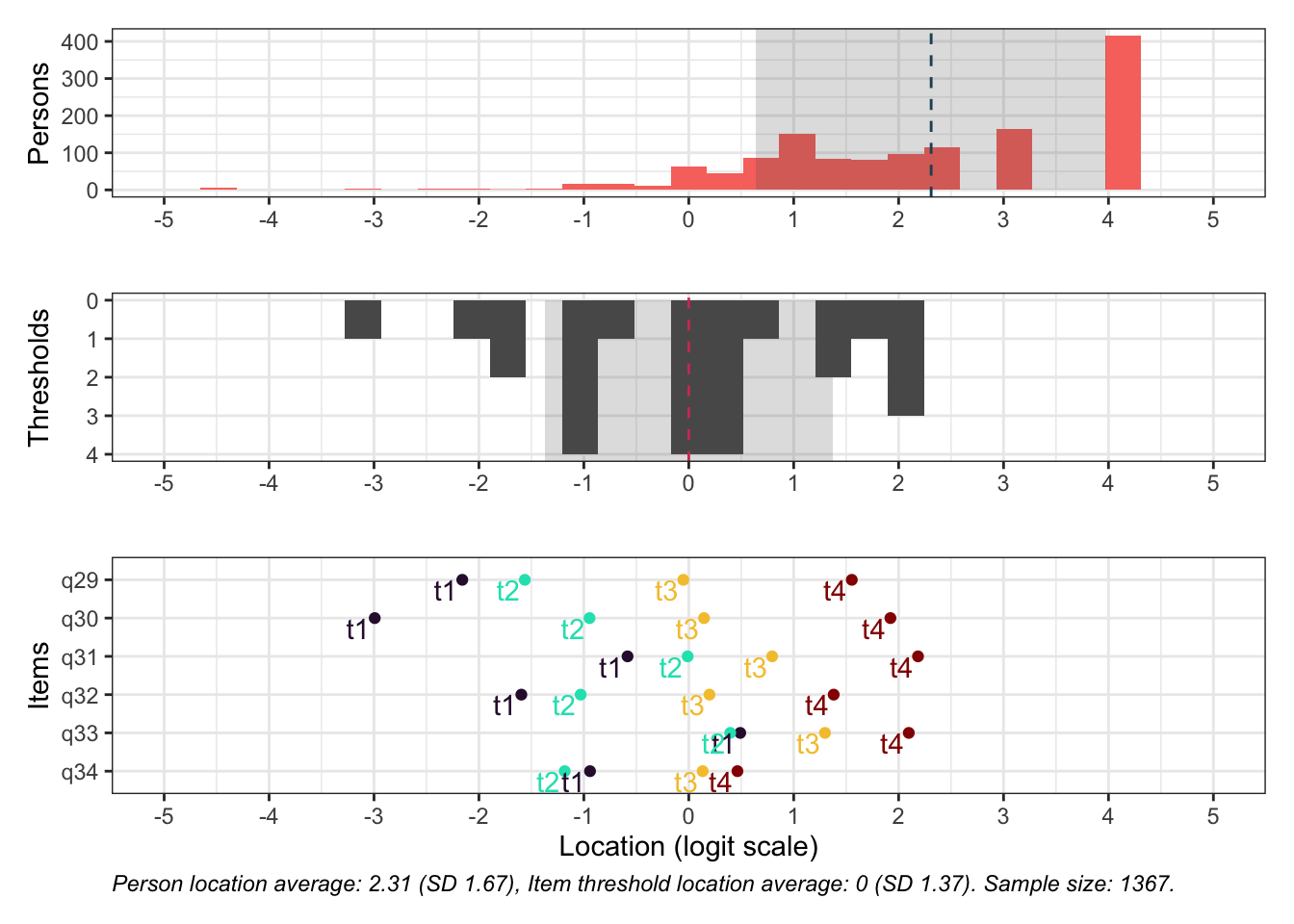
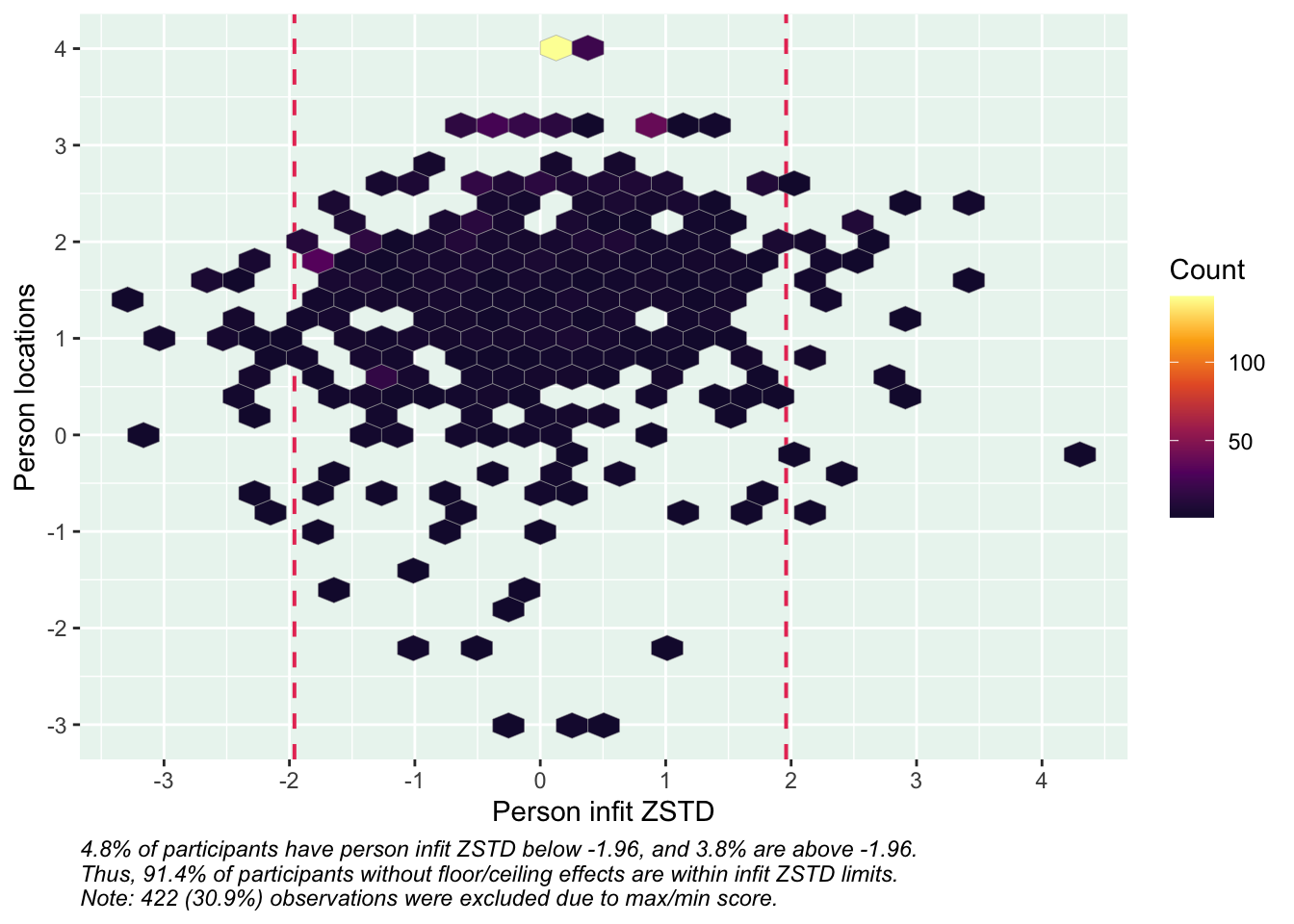
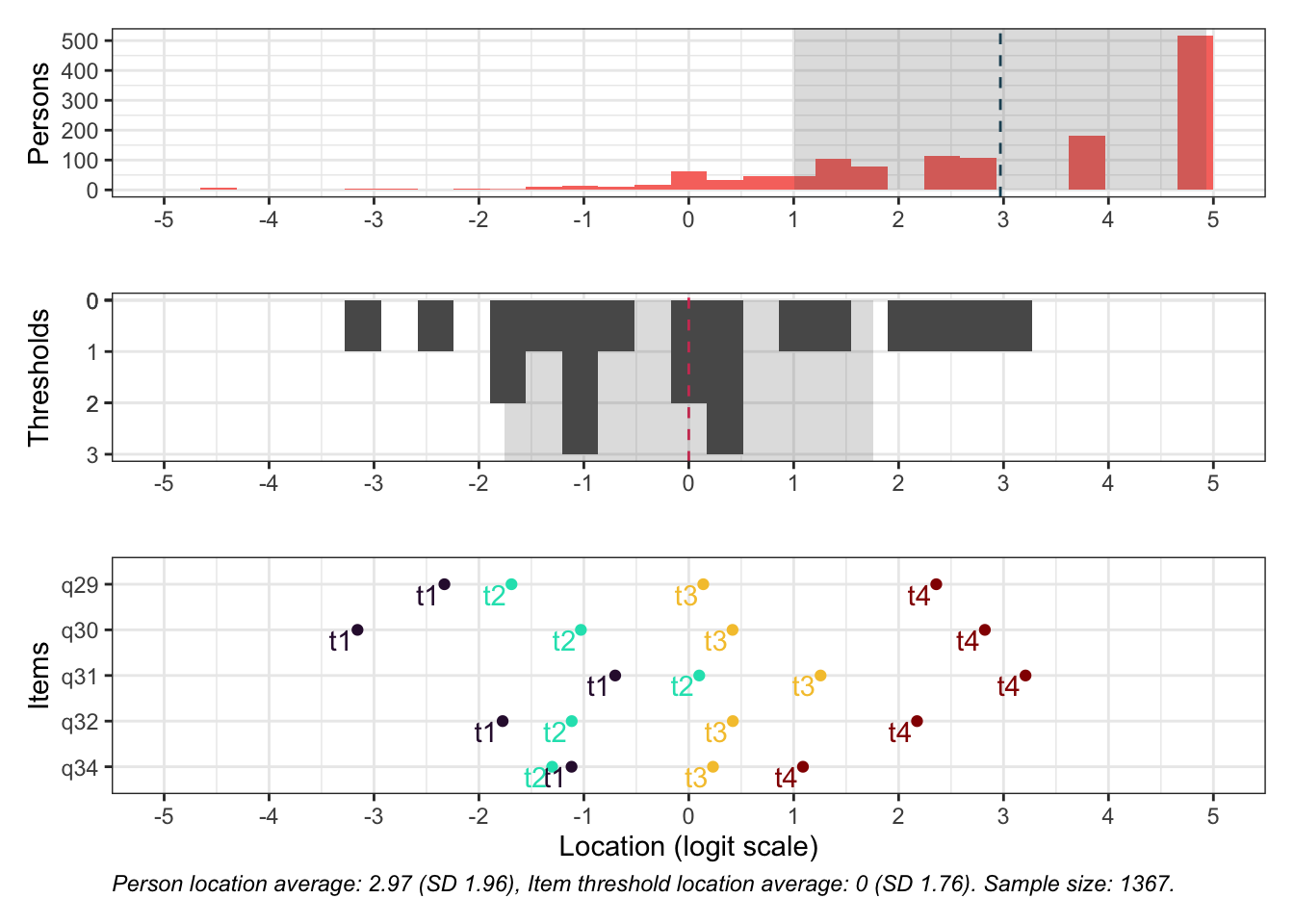
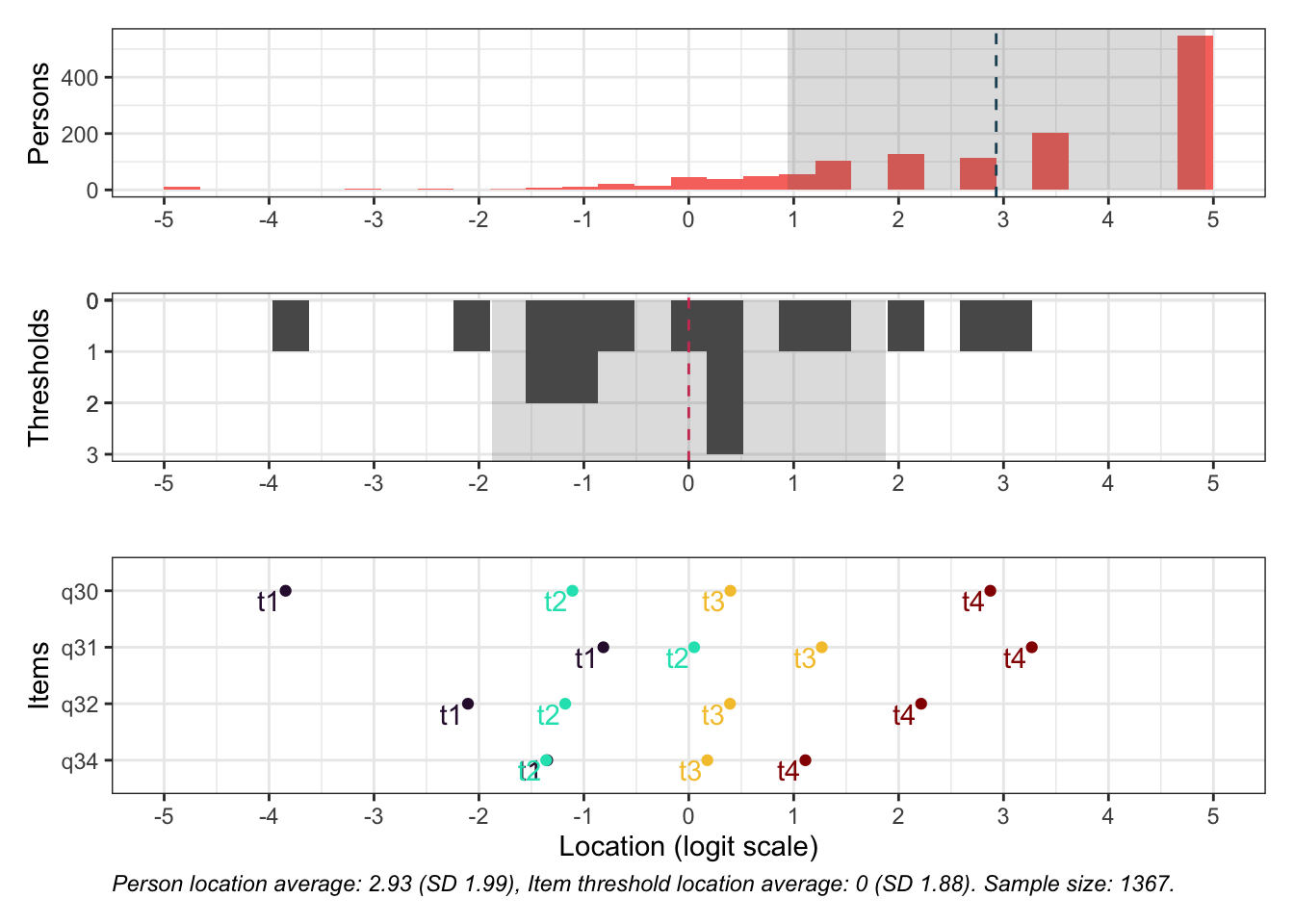
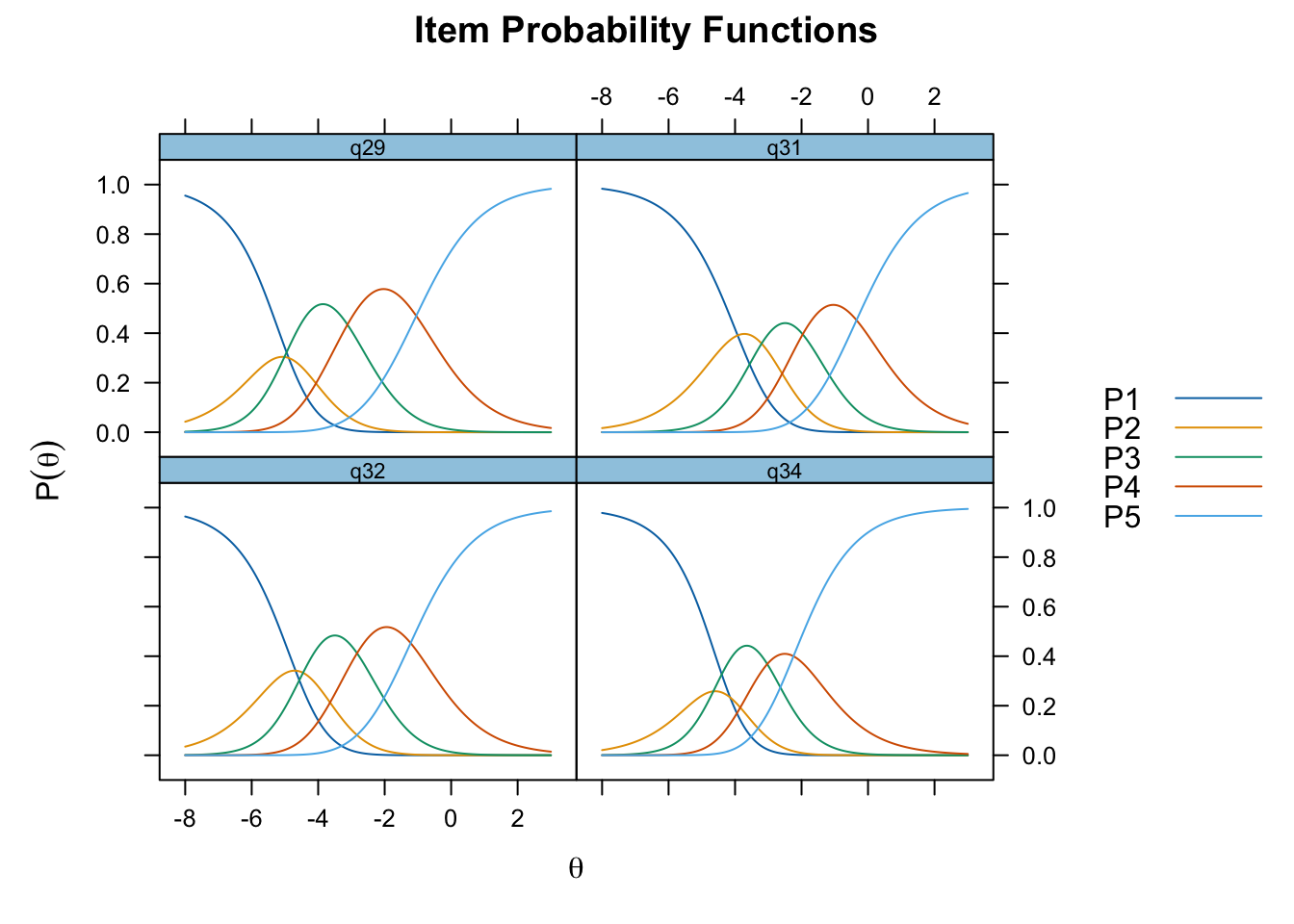
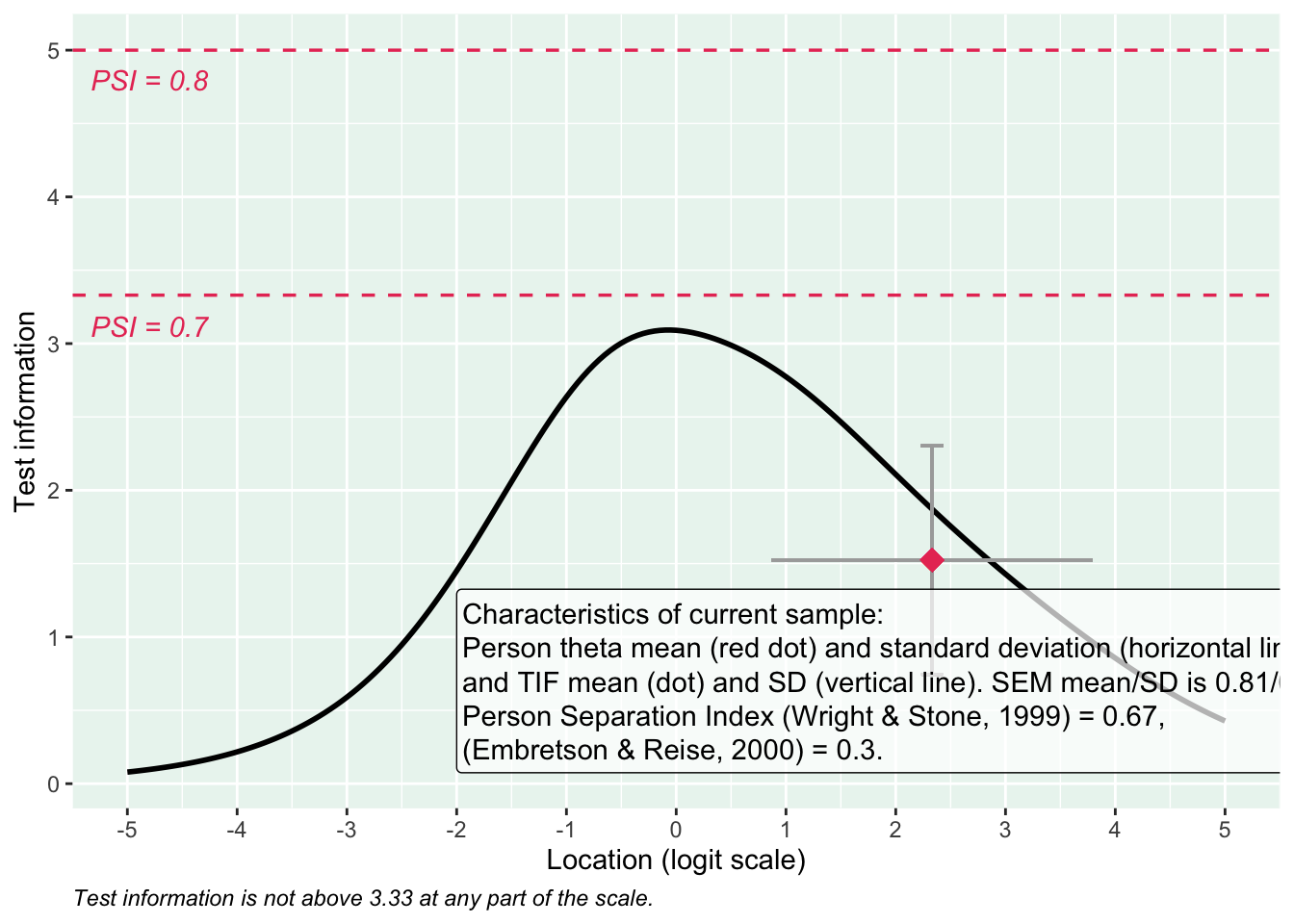
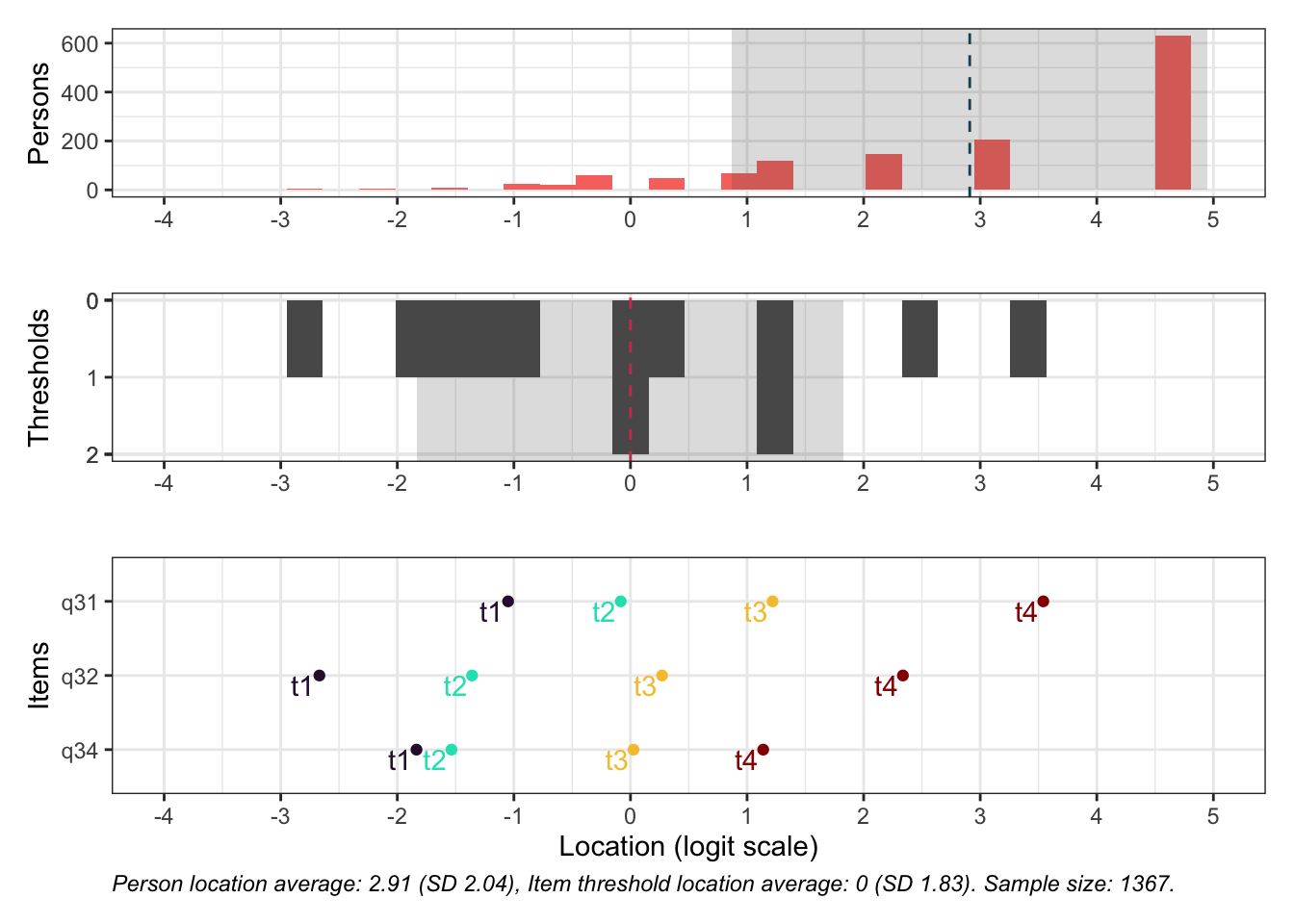
Targeting visar stark takeffekt = svårt att mäta högre nivåer av föräldrarelation
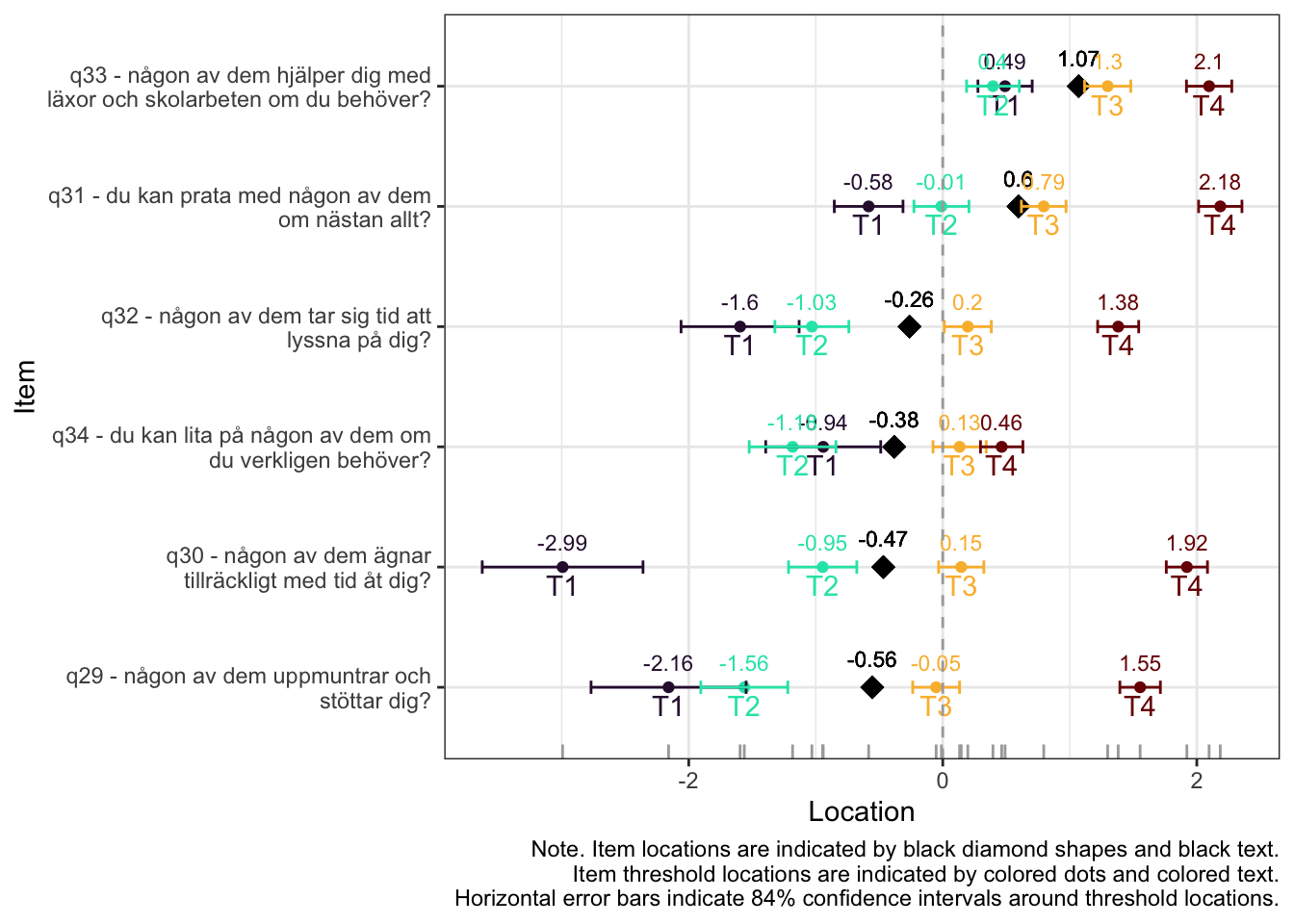
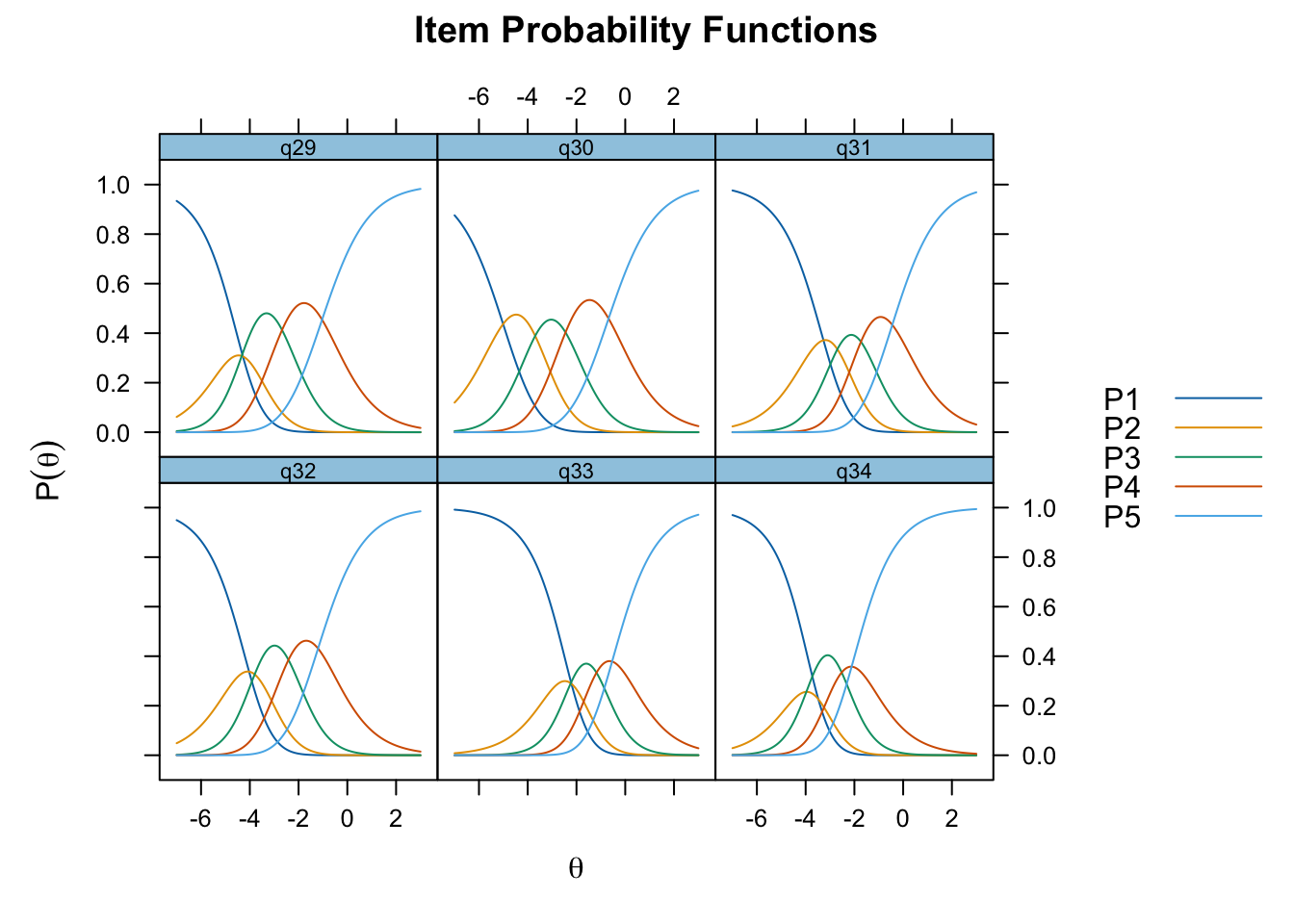
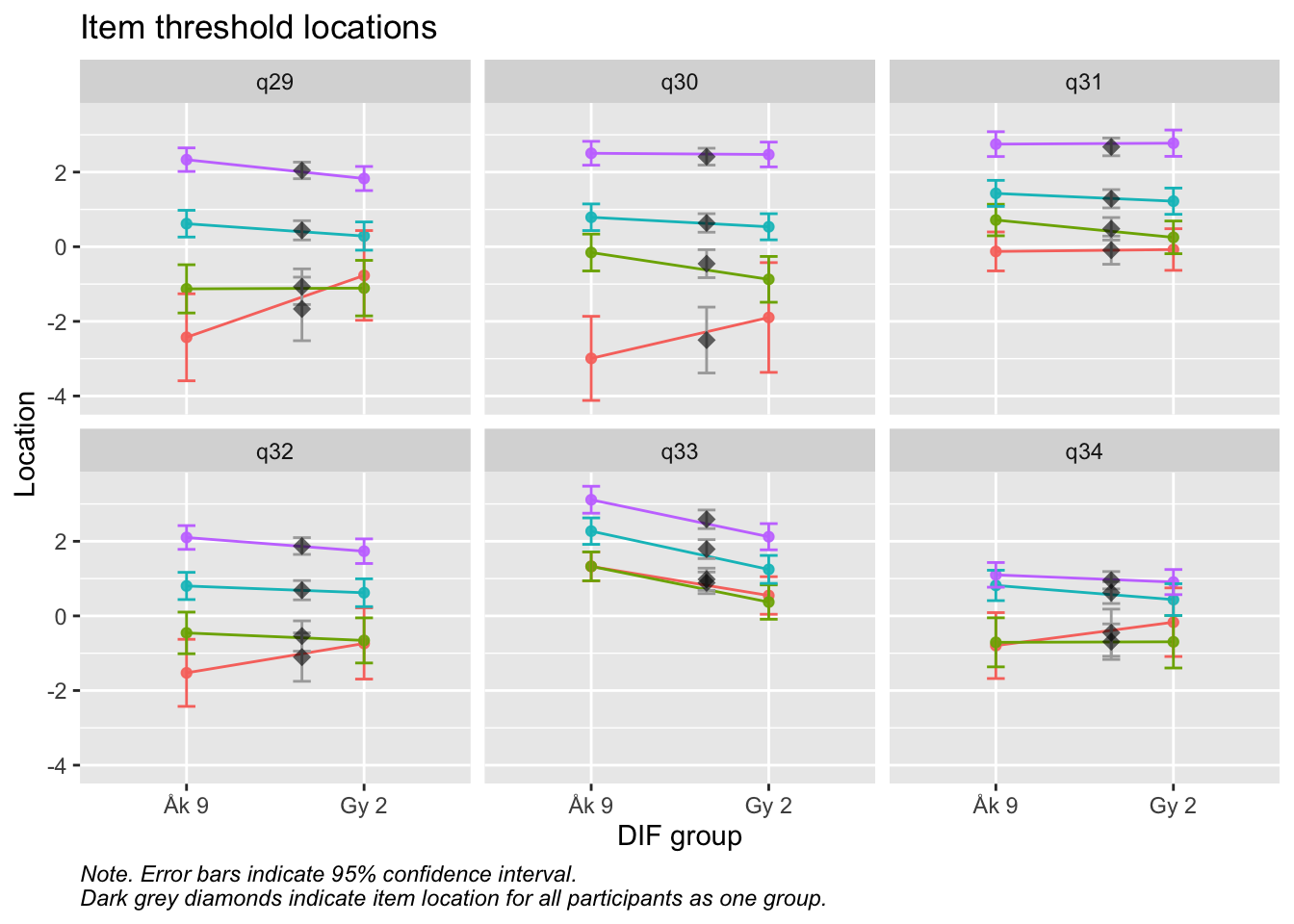
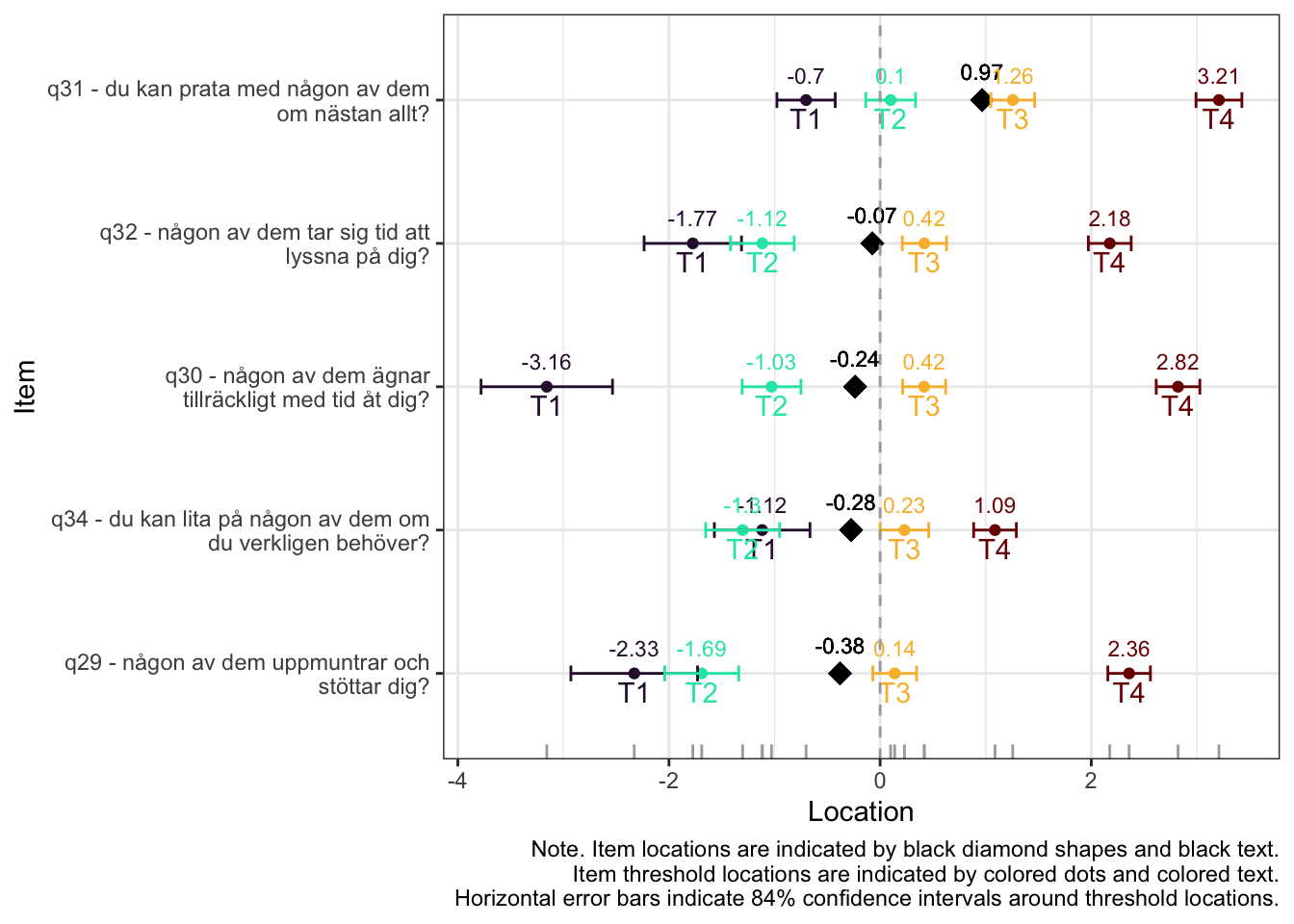
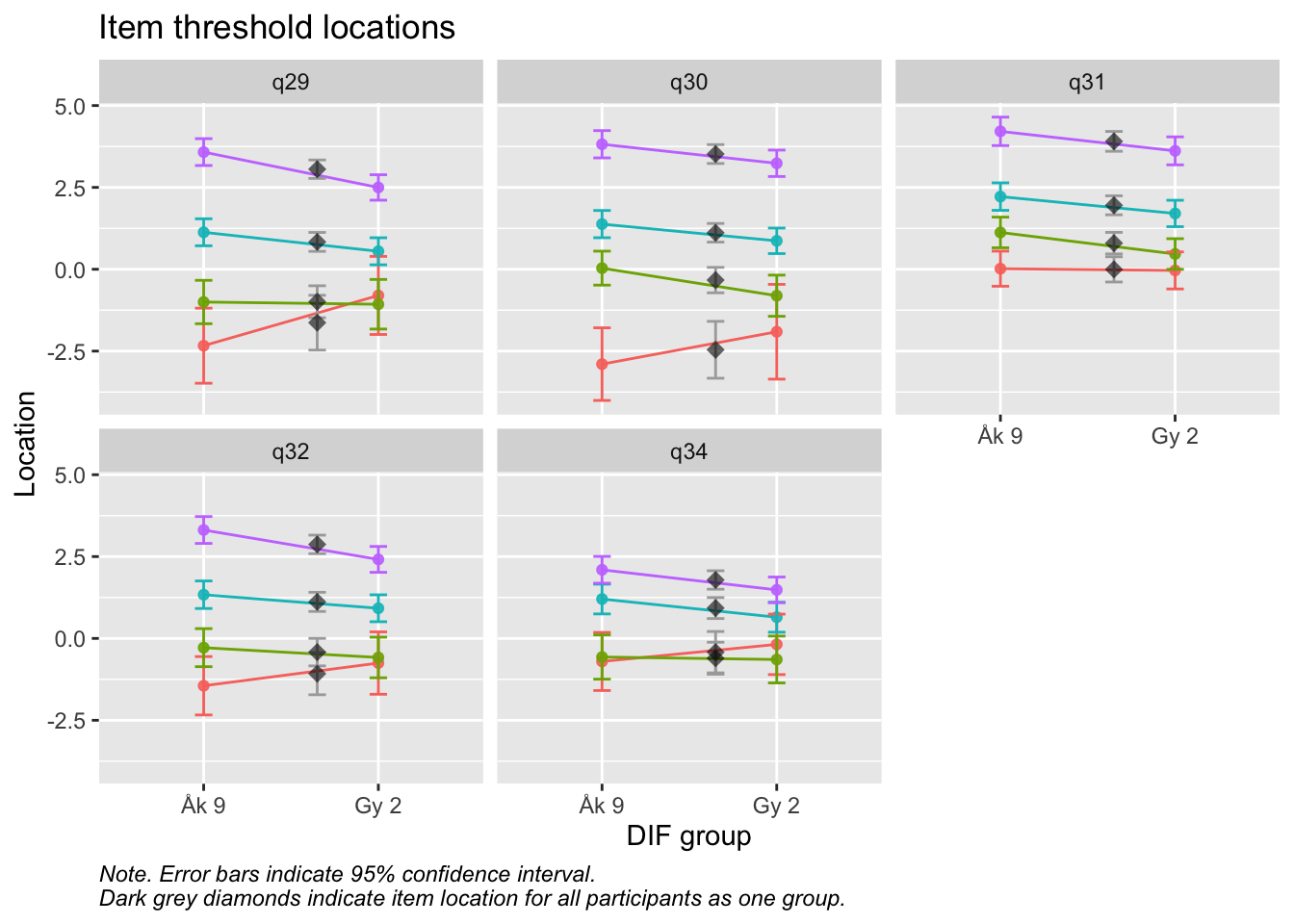
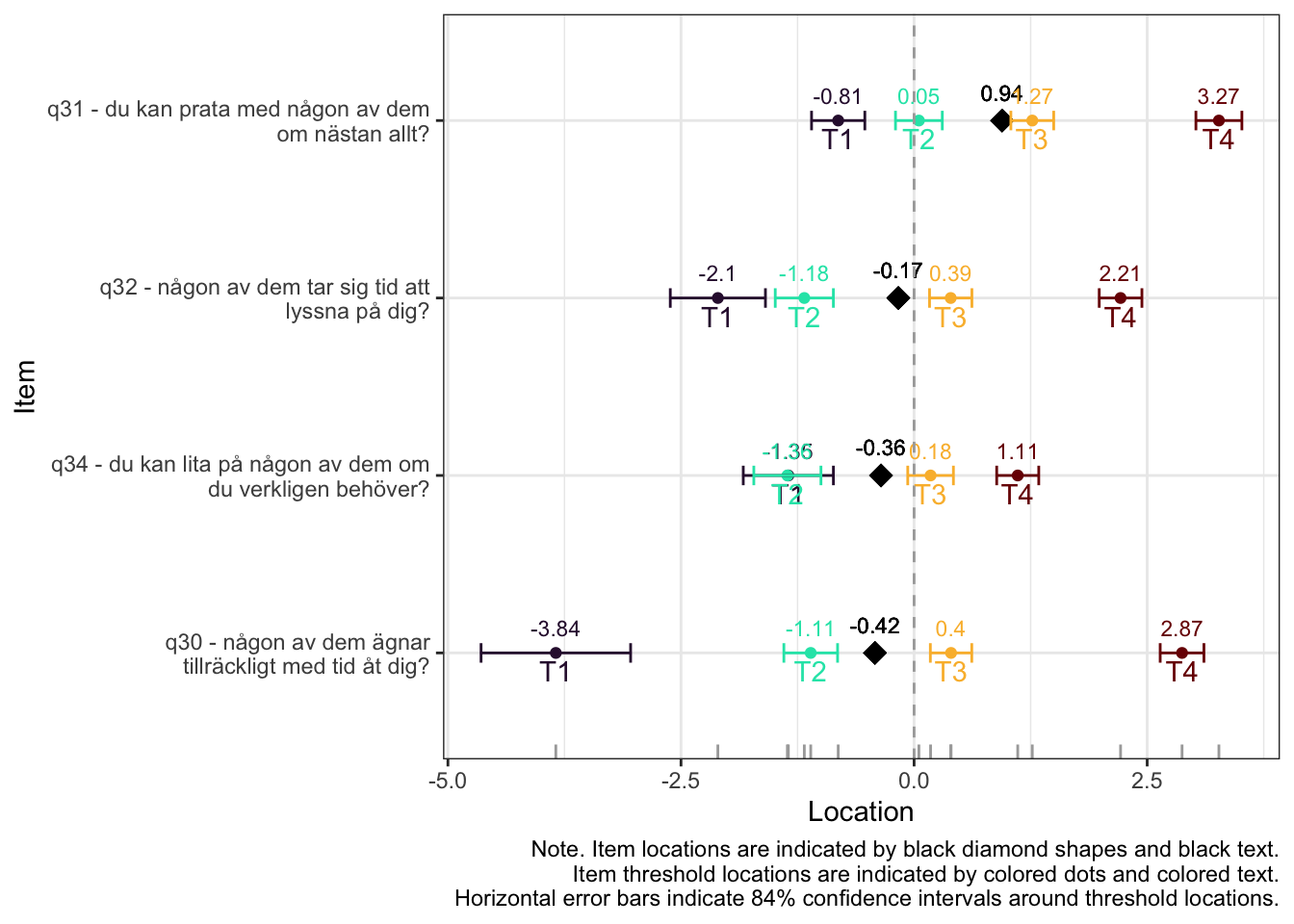
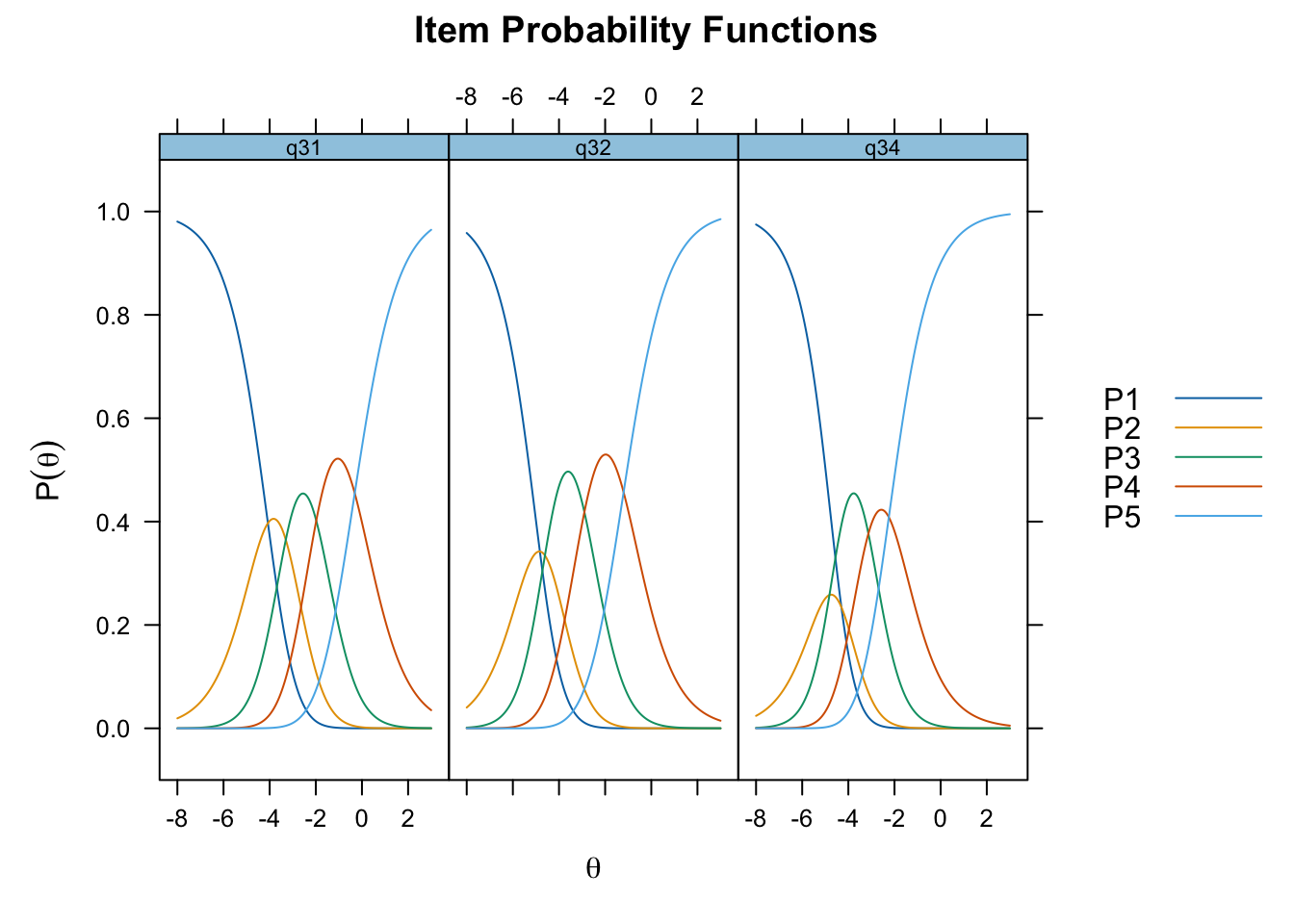
Ordnade svarskategorier på q34 och q33
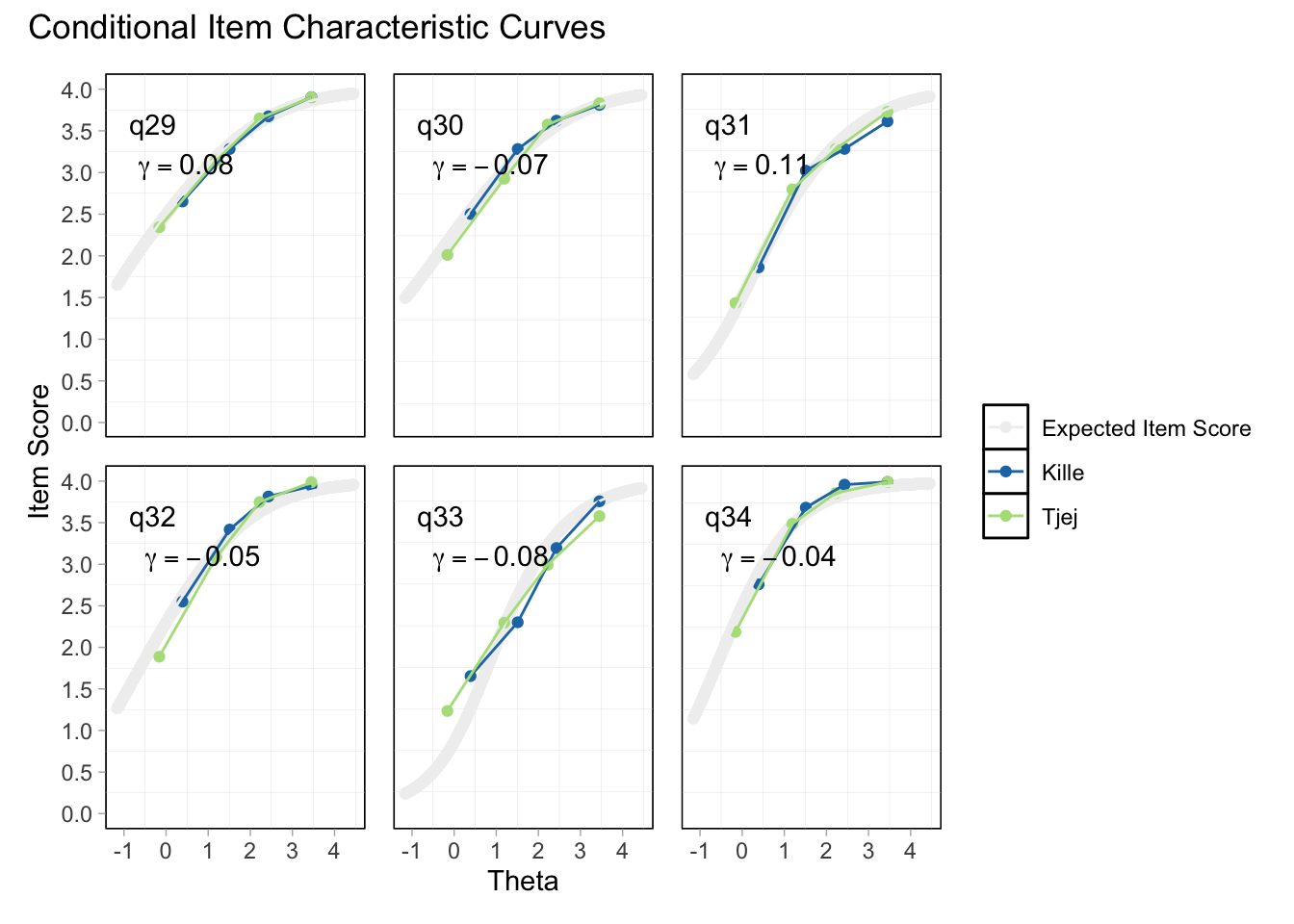
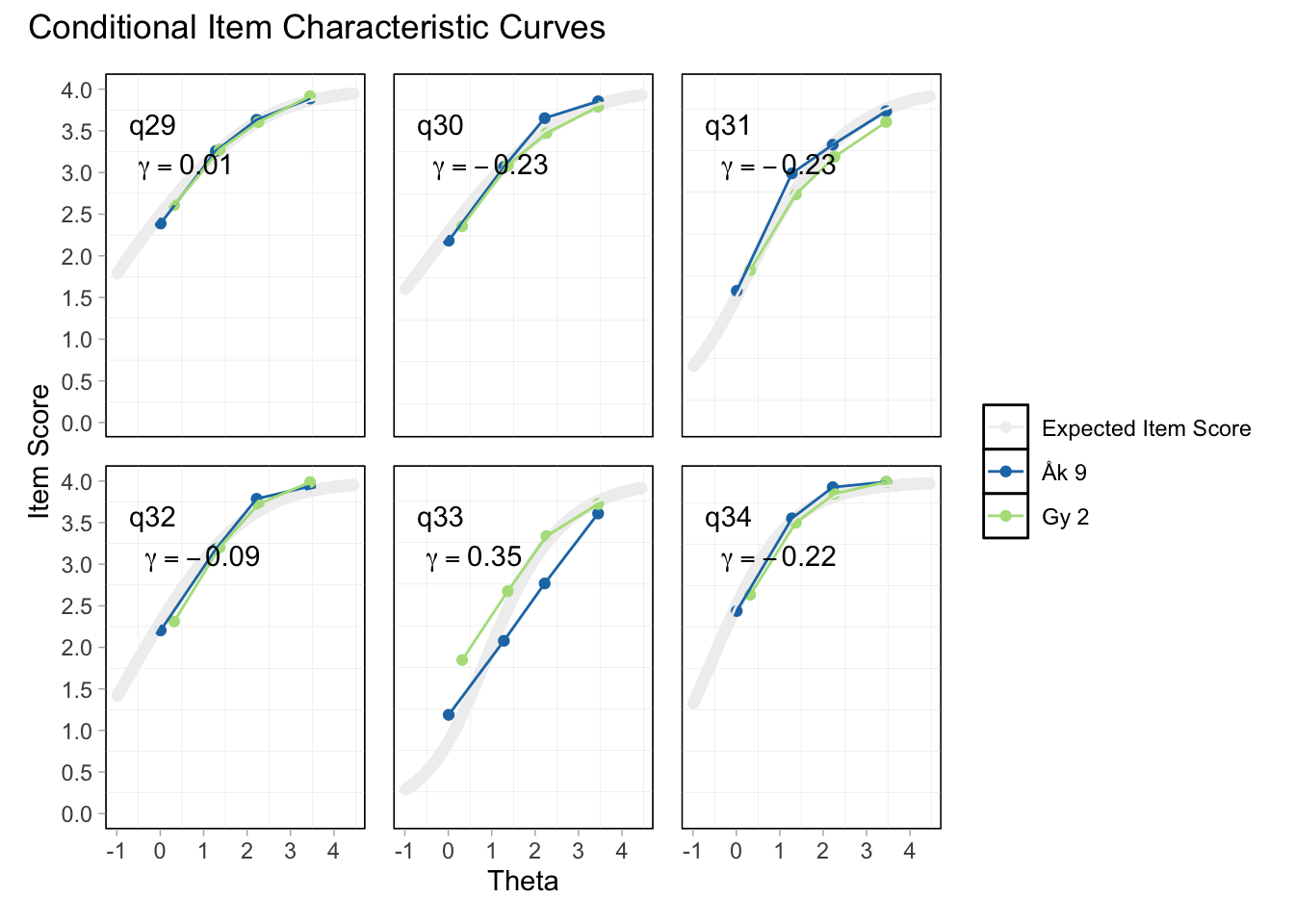
DIF kön q32 och q33 och till viss del q30 (oordnade trösklar)
DIF årskurs q33
Tar bort q33 som helt klart tillhör en annan dimension. De högsta svarskategorierna kodas ihop i q34
Även q29 (oordnade svarströsklar) eller q30 bör ev. tas bort pga residualkorrelation, men vi börjar med q33.
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
Values highlighted in red are above the chosen cutoff 0.5 logits. Background color brown and blue indicate the lowest and highest values among the DIF groups.
Vad händer med residualkorrelationen mellan 29 och 30 om vi tar bort 31 eller 32?
Code
simcor31<-RIgetResidCor(d_f[,-3], iterations =500, cpu =8)simcor32<-RIgetResidCor(d_f[,-4], iterations =500, cpu =8)RIresidcorr(d_f[,-3], simcor31$p999)
q29
q30
q32
q34
q29
q30
-0.09
q32
-0.31
-0.23
q34
-0.4
-0.4
-0.15
Note:
Relative cut-off value is -0.15, which is 0.112 above the average correlation (-0.262). Correlations above the cut-off are highlighted in red text.
Code
RIresidcorr(d_f[,-4], simcor32$p999)
q29
q30
q31
q34
q29
q30
0.08
q31
-0.5
-0.47
q34
-0.34
-0.33
-0.1
Note:
Relative cut-off value is -0.135, which is 0.141 above the average correlation (-0.276). Correlations above the cut-off are highlighted in red text.
Residualkorrelationen mellan 29 och 30 förändras inte märkbart.
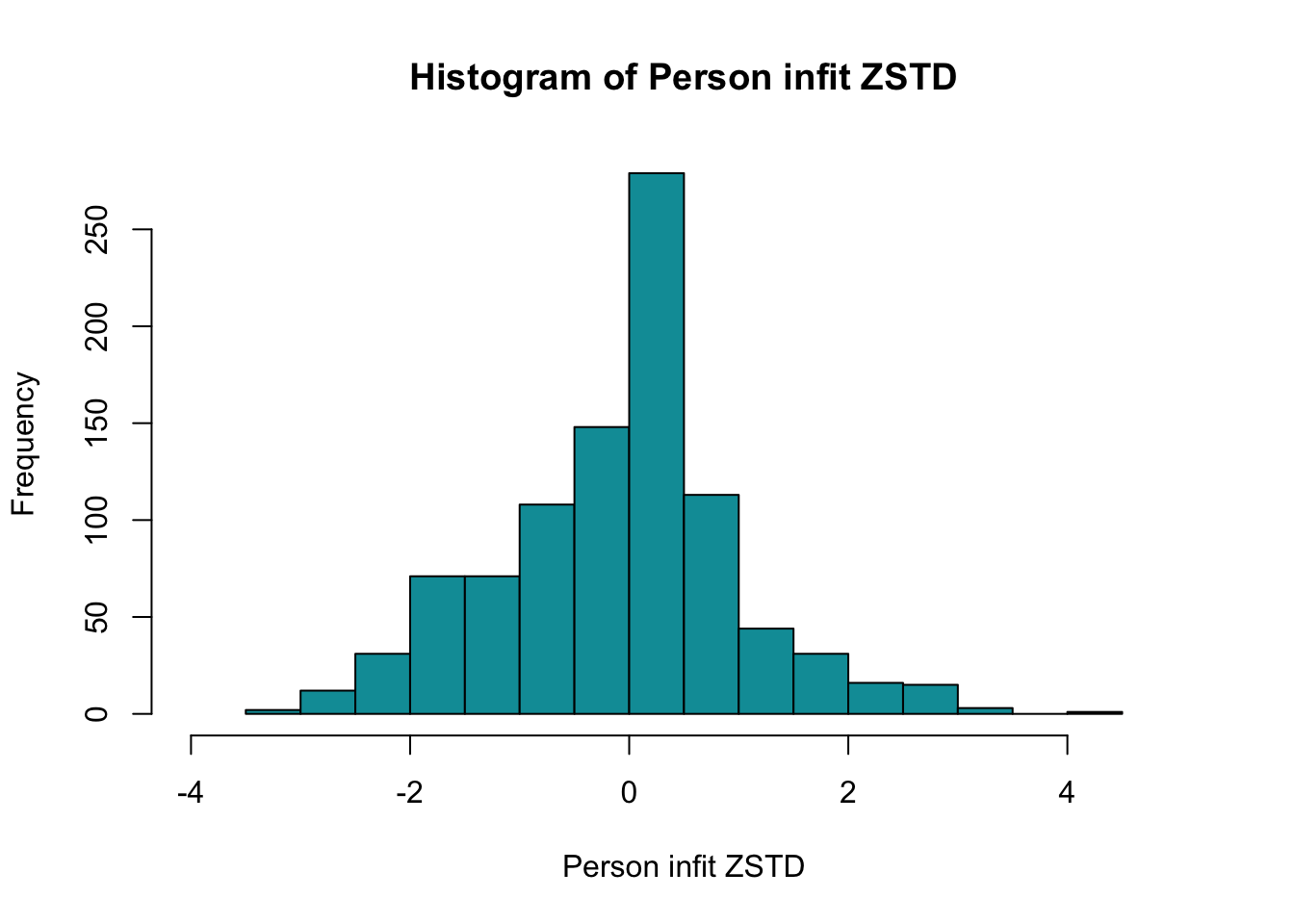
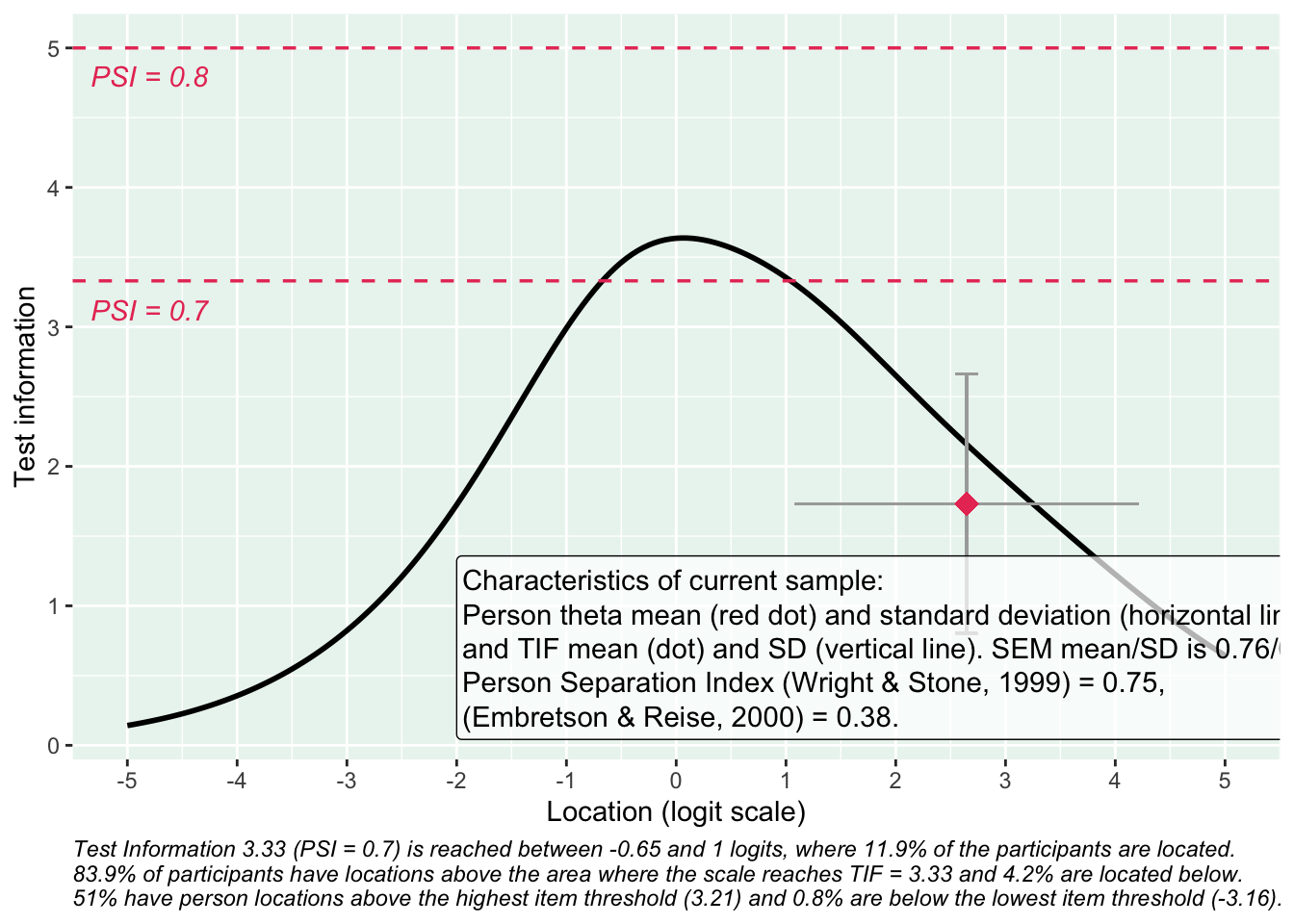
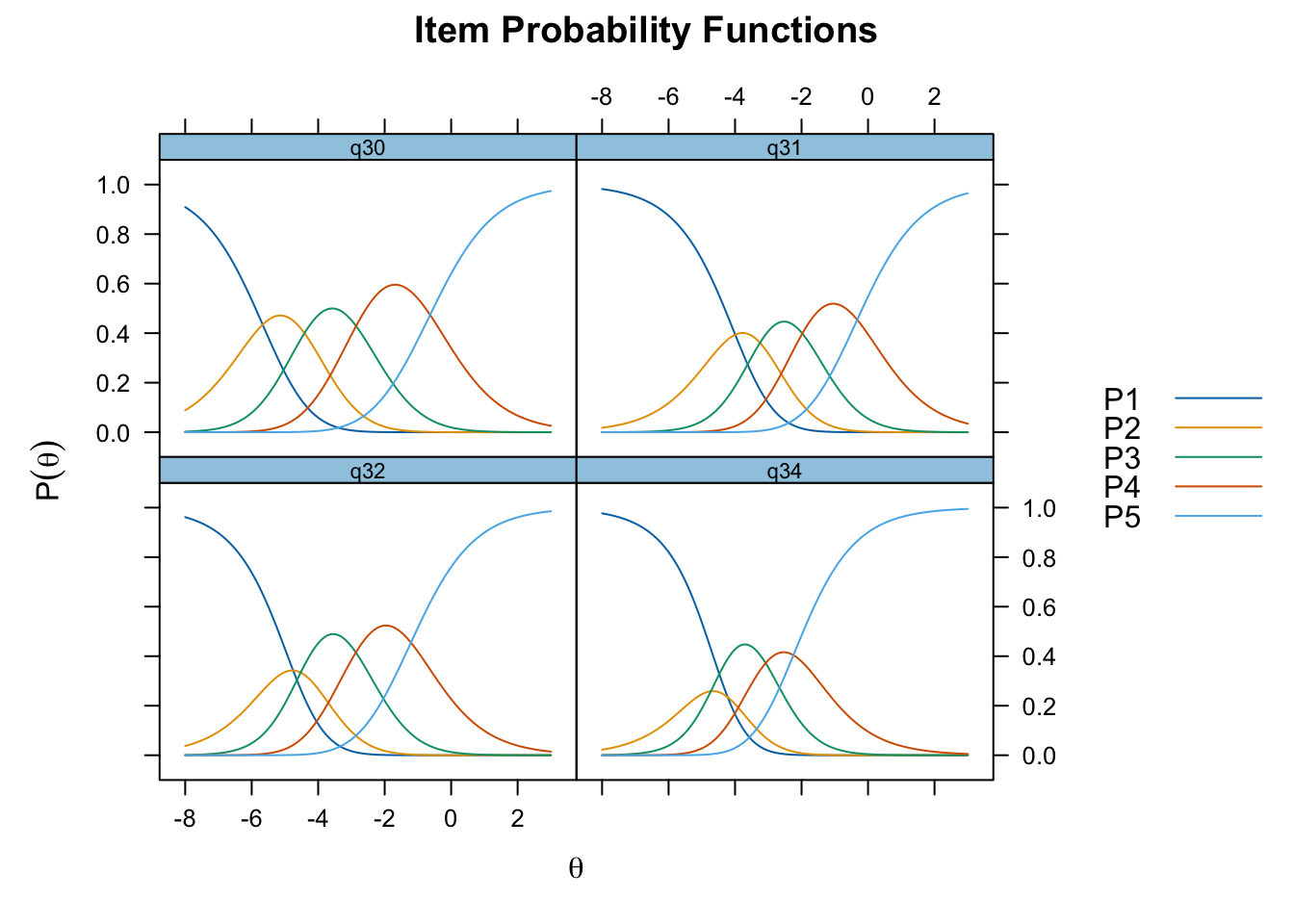
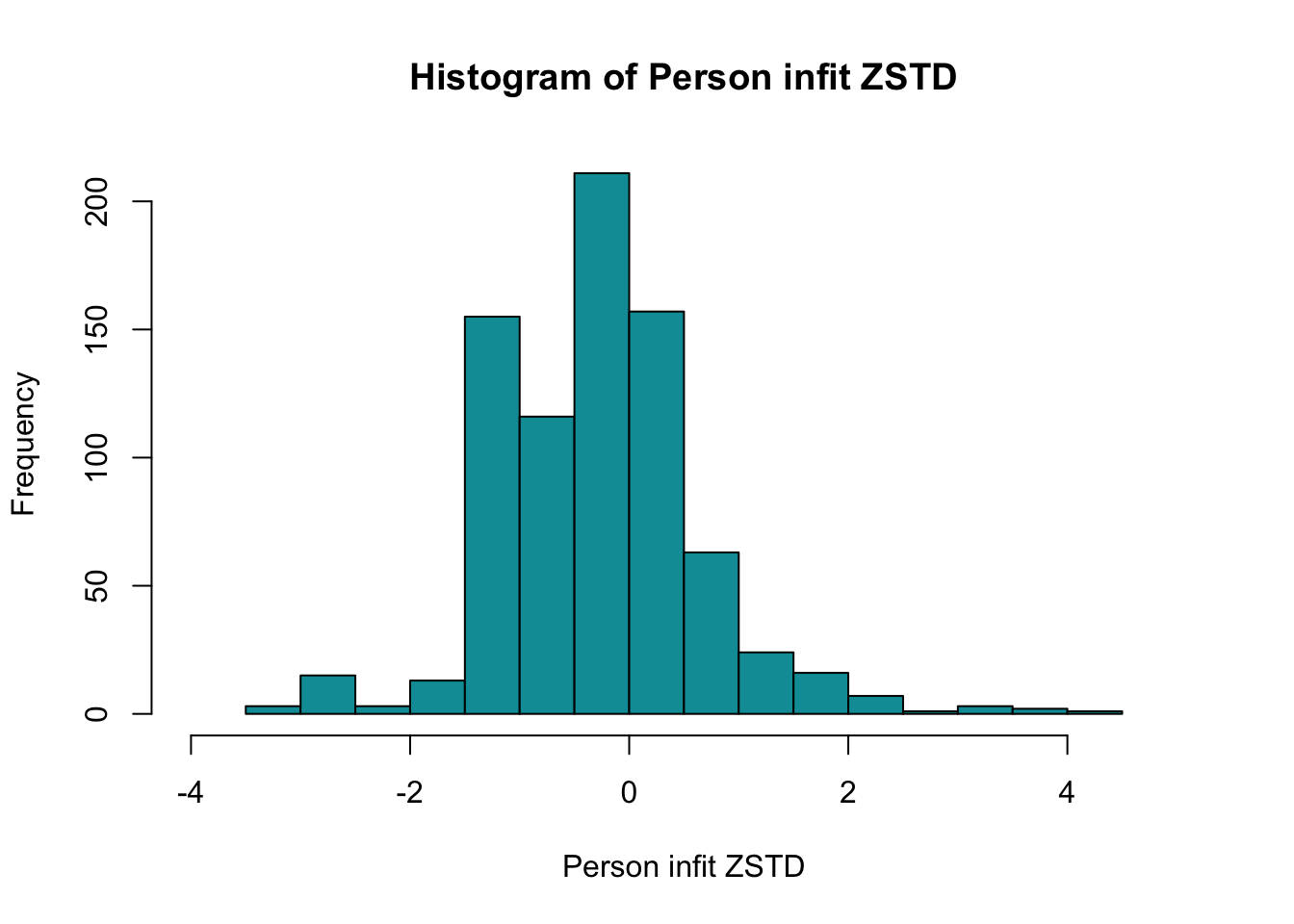
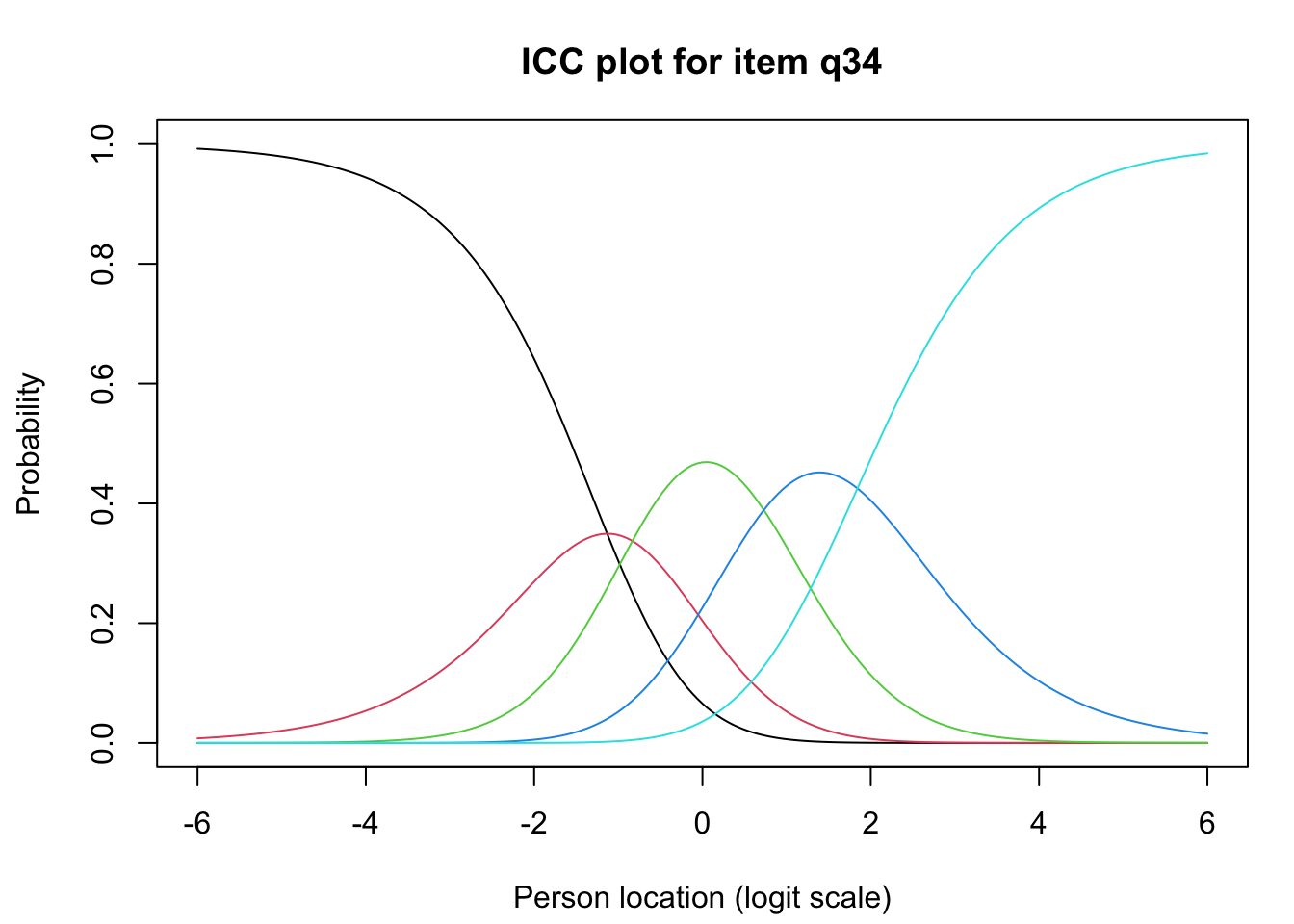
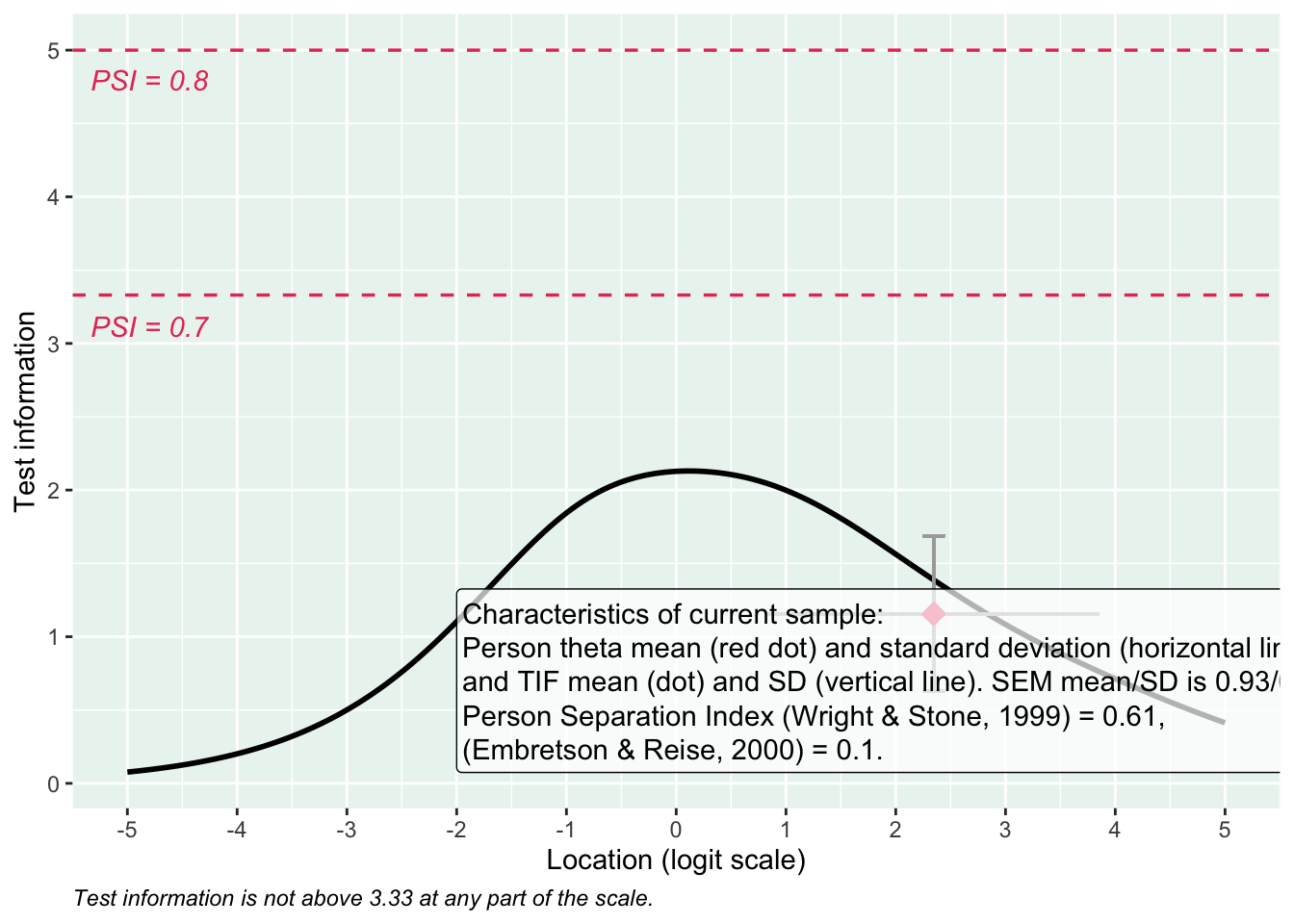
Ingen item misfit. PCA är 1.68, under simuleringsgränsvärdet 1.7. CLRT ser också bra ut. Inga residualkorrelationer. Svarskategorierna för item 34 ser ok ut när eRm estimerar tröskelvärden, men ser oordnade ut längst ner när mirt estimerar. Eftersom vi generellt använder eRm och conditional maximum likelihood som primär metod, går vi på det resultatet.
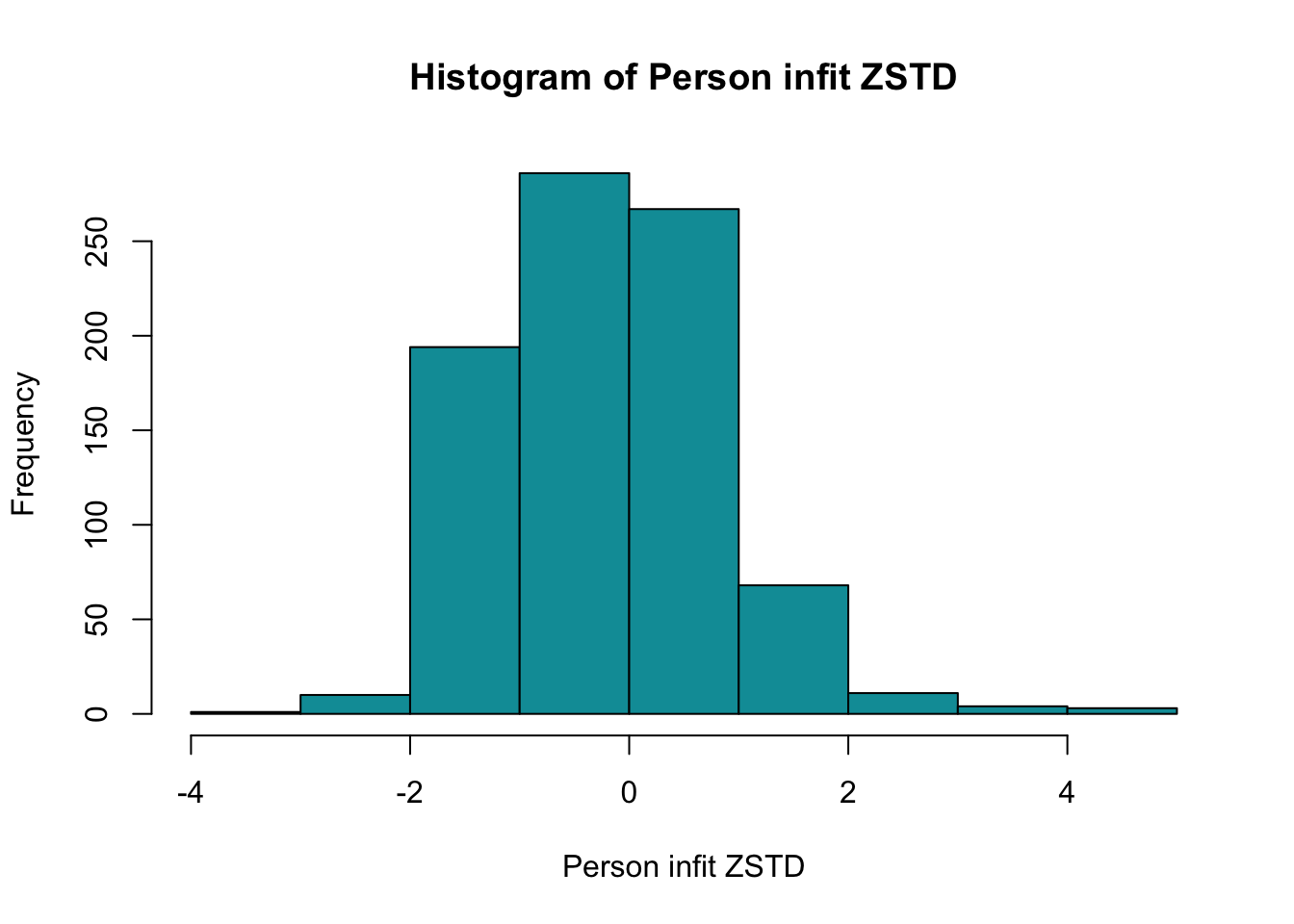
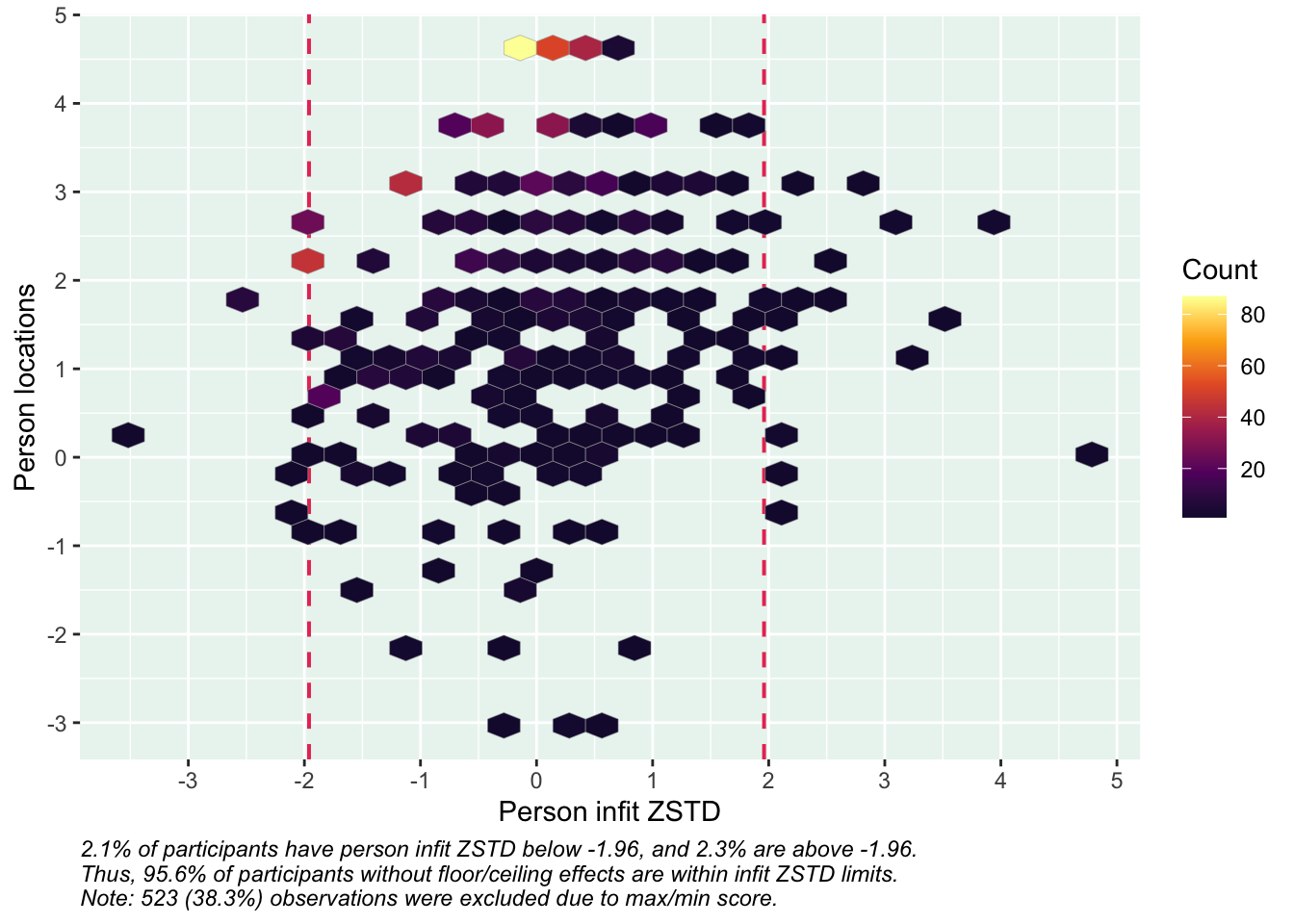
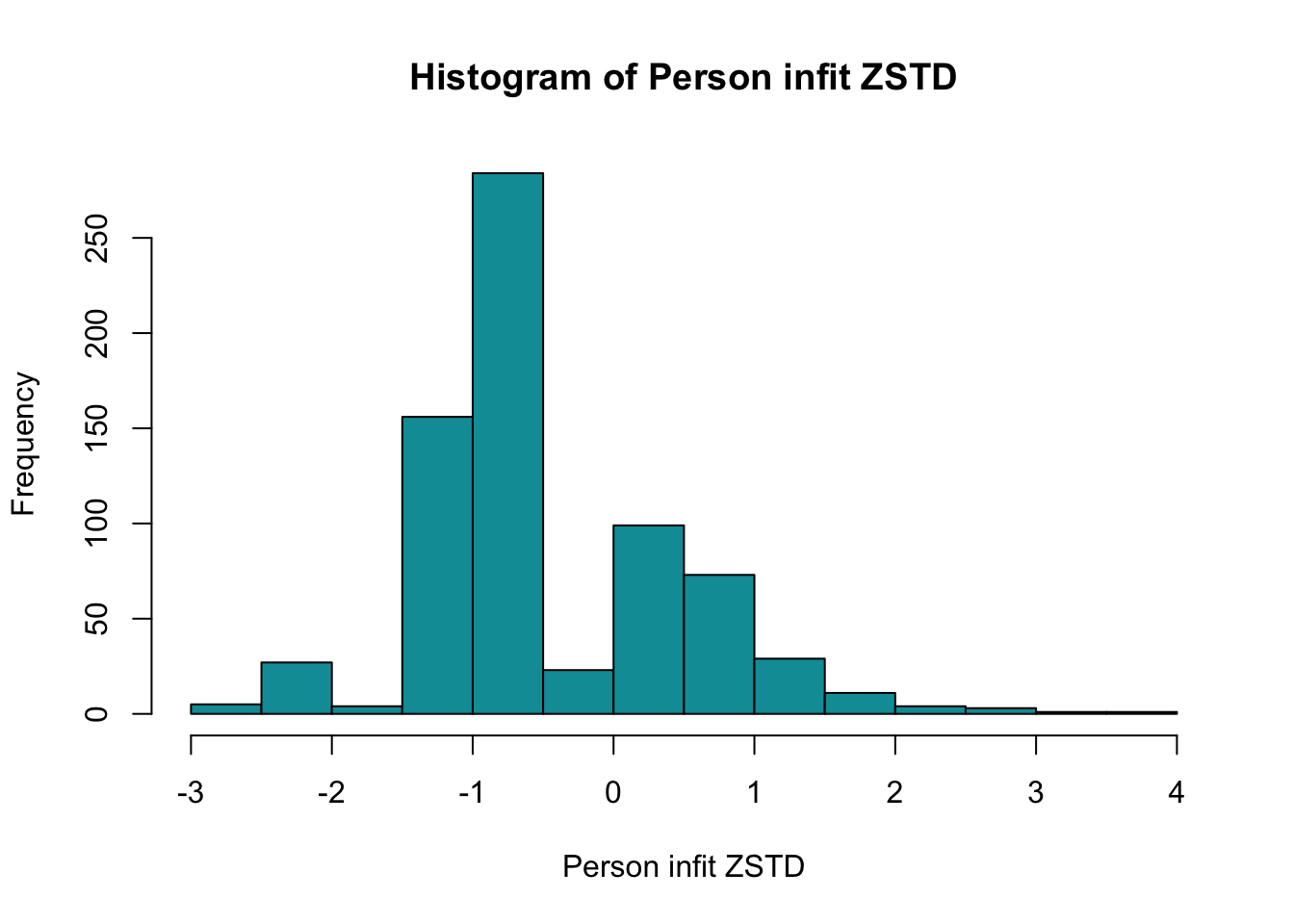
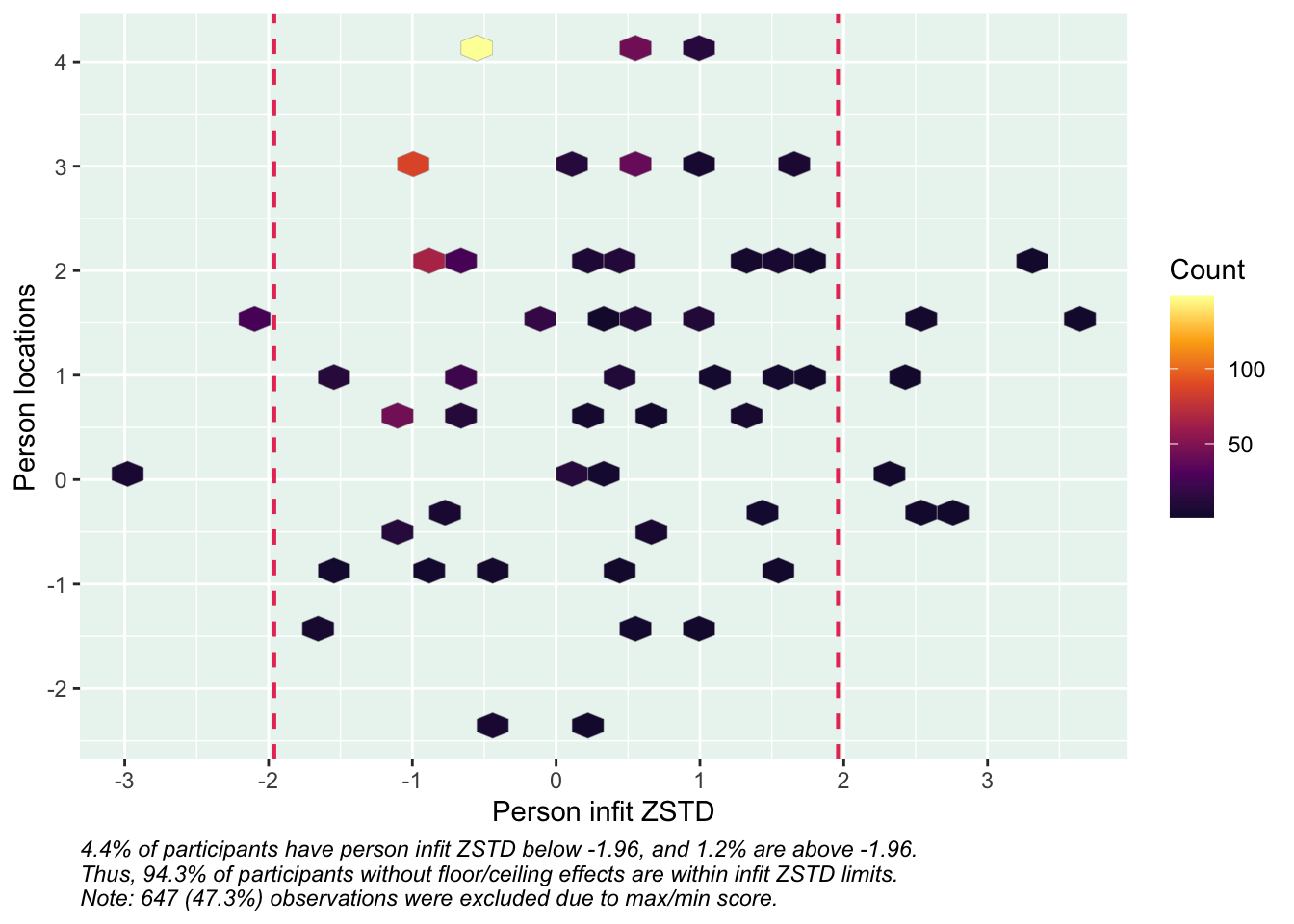
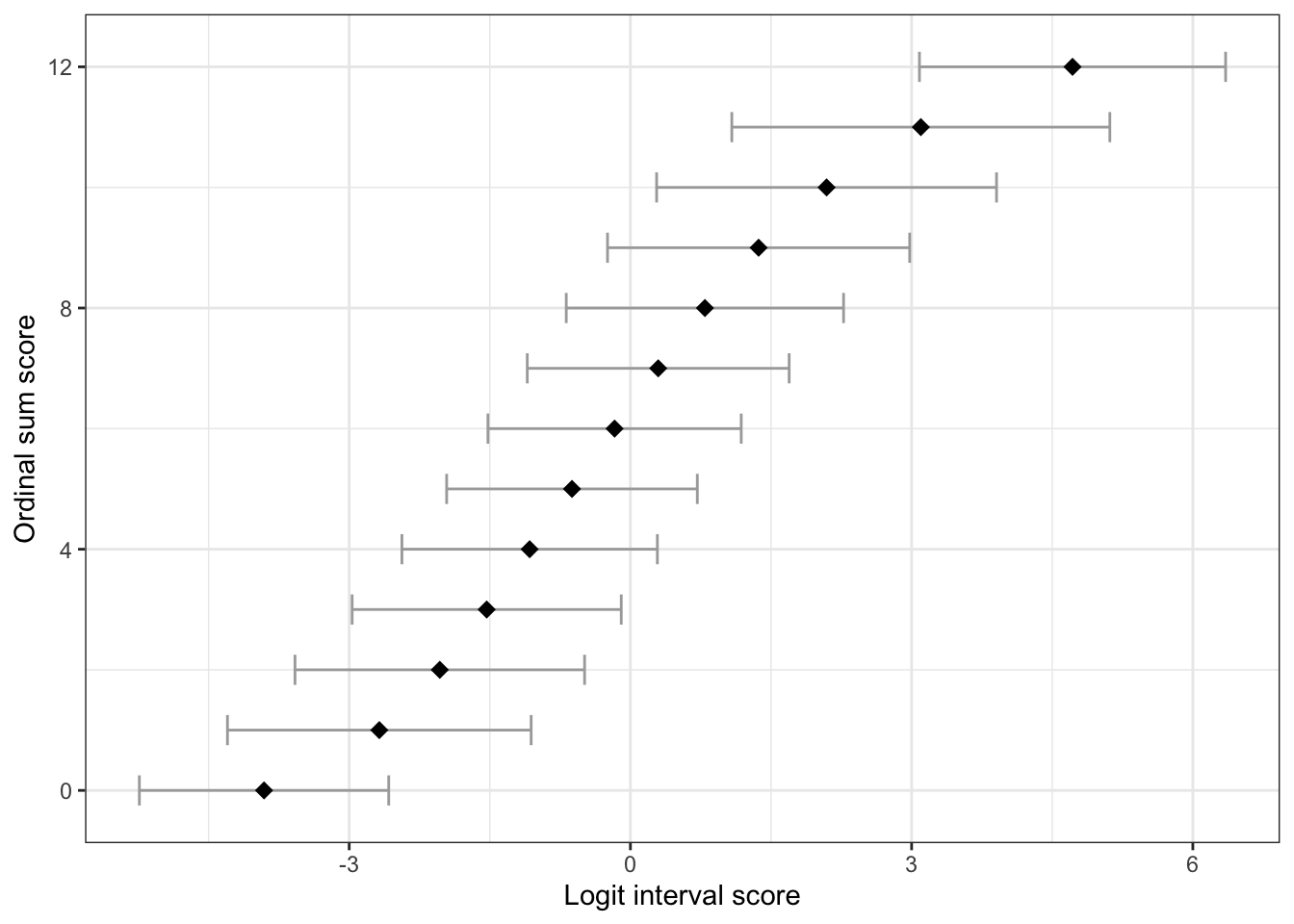
Ca 6.2% har en score under 6, och 10.7% är under 7.
Ett tänkbart scenario är att klassificera 6 som gräns för riskgrupp, och 7 som möjlig risk, med en röd respektive gul färgsättning motsvarande det som använts i Data i Dialog hittills.