
| Övergripande indexbeskrivning | Itembeteckningar i datafil |
|---|---|
| Psykiska/psykosomatiska besvär | F88-F99 |
| Individfaktorer | f66a-u |
| Prosocialt index | F70, f86a c f |
| Skola | f54a-r, f56 |
| Närsamhälle | F100, f101a-l |
| Kamrater | f86b d e ghij |
| Föräldraskap | F82, f83a-h, F58 |
| Föräldrakontroll | F79-81 |
| ANDTS (droger och spel) | F14,FNY12020,F18,F34,F41,F47,F48,f53a,F73 |
| F16,F20,F37,F44,F51 | |
| F17,F21,f22a,F40,FNY22020 | |
| Brott och utsatthet | f75a-s, f78aa-ea |
OBS att sammanfattningen är under arbete och inte helt komplett ännu.
1.1 Introduktion
Målsättningen med de analyser som gjorts har varit att:
- Genomföra en psykometrisk analys av befintliga enkätdata i Stockholmsenkäten med fokus på framtagande av index i Stockholmsenkäten baserade på risk- och skyddsfaktorer. Dataunderlaget bygger primärt på insamlade data från 2006 till 2020, med data från varannat år.
- Fastställa mätegenskaper för att bedöma vilka items/frågor som tillsammans kan bilda ett adekvat index, hur god mätprecision indexet har för att urskilja skillnader över tid eller mellan grupper, och huruvida index är lämpliga för att göra jämförelser mellan olika grupper (t.ex. könsskillnader) och över tid.
Utifrån RISE kunskapssammanställning om risk- och skyddsfaktorer för barn och unga (Johansson 2021) har vi strävat efter att identifiera centrala faktorer utifrån kontexterna Individ, Familj, Skola, Kamrater och fritid, och Närsamhälle. Syftet är att ta fram index som kan redovisas på en intervallskala, för att möjliggöra mera finkorniga analyser och jämförelser än vad som är möjligt utifrån enstaka frågor, dikotomiserade data, eller index som endast består av 3-4 ordinalsummerade frågor. Det medför också att antalet index/faktorer som tas fram är lägre än vad som tidigare kan ha redovisats utifrån Stockholmsenkäten.
1.1.1 Items som ingått i analysen
1.1.2 Psykometriska kriterier
RISE har tagit fram fem grundläggande kriterier och en rapporteringsmall för vetenskapliga psykometri-artiklar som har varit utgångspunkt för analysarbetet. Artikeln finns fritt tillgänglig som preprint (Johansson et al. 2023) och innehåller både en enklare och mera fördjupad beskrivning av kriterierna.
Nedan finns en förenklad beskrivning av psykometriska kriterier som kommer från RISE rapport till MFoF om uppföljning av föräldraskapsstöd (Preuter, Johansson, and Bokström 2022):
När enkäter konstrueras och utvärderas bedöms dess psykometriska egenskaper, ofta kopplade till begreppen reliabilitet och validitet. Förenklat kan man säga att reliabilitet beskriver hur väl något mäts (vilken precision mätverktyget har), medan validitet beskriver hur väl innehållet i frågorna och svarskategorierna fångar det man avser att mäta. Dock råder i allmänhet oklara definitioner av begreppen och kriterier för huruvida dessa mätegenskaper uppfylls eller inte. Det medför att även enkäter som i forskningsartiklar beskrivs som “validerade” eller att de har “god reliabilitet” inte nödvändigtvis uppfyller vad som kan anses vara grundläggande kriterier. En mera omfattande beskrivning av de grundläggande psykometriska kriterierna återfinns i Bilaga 3 (separat dokument). Nedan listas kriterierna. Var och en av dem kräver psykometrisk analys av insamlade data för att bedöma.
Lista över grundläggande psykometriska kriterier:
- Svarskategorierna fungerar som avsett
- Frågorna fungerar likadant för olika grupper (kön, ålder, etc)
- Unidimensionalitet (utan för starkt korrelerade residualer)
- Frågornas svårighetsgrad passar målgruppens egenskaper/förmågor
- Reliabilitet/mätosäkerheter över skalans omfång är adekvat, sett till användningsområdet
- Omvandlingstabell till intervallskala
Kriterierna ovan är ställda för att säkerställa att det är lämpligt att använda summapoäng från en enkät/skala. Summapoängen bör i sin tur användas tillsammans med en omvandlingstabell till intervallskala innan några statistiska eller matematiska beräkningar görs. Tyvärr är det mycket vanligt att forskningsstudier enbart redovisar Cronbach’s alpha som ett mått på reliabilitet och/eller kvalitet på en enkät. Det är dessvärre gravt otillräckligt för att bedöma mätegenskaper hos ett mätverktyg, eftersom Cronbach’s alpha inte ger information om något av kriterierna ovan.
Mer om psykometri och mätegenskaper finns att läsa i bilaga 3 (separat dokument) och exempelvis i RISE publikation om mätning av mjuka värden (Johansson, Svensson, and Melin 2021).
1.1.3 Noteringar om analysprocessen
Inom varje område har samtliga frågor/items lagts in i en analys. Ambitionen har varit att först ta fram ett index med så goda mätegenskaper som möjligt, och att enbart eliminera items som varit tydligt problematiska utifrån de psykometriska kriterierna. Gällande Individfaktorer och Skola finns det ytterligare utrymme att minska antalet items och ändå ha acceptabel reliabilitet. I vissa fall har det gått att ur ett frågeområde ta fram mer än ett index med acceptabel reliabilitet.
Inom många områden finns sedan tidigare definierade index som använts i rapporteringen av Stockholmsenkäten, ofta bestående av tre frågor. Även dessa har analyserats kortfattat.
Samtliga index som redovisas i denna sammanfattning har uppfyllt alla kriterier beskrivna ovan. För att hålla en rimlig detaljnivå presenteras enbart figurer som visar reliabilitet och “targeting”, hur frågorna passar respondenterna, eftersom dessa hänger samman med användningen av frågorna, och även är relevanta för eventuella framtida reduktioner i items i Stockholmsenkäten.
Ett vanligt problem i analyserna har varit residualkorrelationer. Det innebär att par av items är för lika varandra och inte enskilt medför tillräckligt mycket unik information till indexet. I stället finns risk för att indexvärden skulle bli oproportionerligt påverkade om båda items behålls i indexet. I regel tas ett item bort, utifrån beaktande av varje items mätegenskaper i indexet.
Två index, “Kamrater och fritid” samt “Prosocialt index”, håller för dålig mätkvalitet för att kunna användas som indexvärde. Det kan eventuellt vara möjligt att skapa enklare nyckeltal utifrån items, som enbart återger nivåerna hög risk/låg risk. Detta kommer förhoppningsvis kunna belysas i en senare version av denna rapport.
För att vara konsekvent i analyserna har samtliga frågor och index orienterats så att en högre poäng medför högre risk, trots att vissa index och vissa frågor representerar skyddsfaktorer. Genomgående i samtliga index är frågorna bättre på att mäta högre nivåer av risk än lägre nivåer av risk.
Detta dokument sammanfattar resultatet av varje indexområdes analysprocess. Analysdokument för respektive indexområde finns tillgängligt i menyn till vänster på denna sida. Den kompletta källkoden som visar hur analyserna gjorts finns tillgänglig på denna webbsida, vilket möjliggör oberoende granskning givet tillgång till rådata.
1.2 Individfaktorer (utagerande)
21 items/frågor med etiketter f66a-f66u i datafilen, och motsvaras av fråga 67 i PDF-filen med frågor.
“Hur väl stämmer följande påståenden in på dig som person?” följs av de ingående frågorna, alla med samma fyra svarskategorier:
- ‘Stämmer mycket dåligt’
- ‘Stämmer ganska dåligt’
- ‘Stämmer ganska bra’
- ‘Stämmer mycket bra’
Svarskategorierna ersätts med siffror från 0 till 3, och för f66h, m, p och u är siffrorna omvända/reverserade, d.v.s. att “Stämmer mycket bra” kodas som “0” i stället för “3” till analysen. Det innebär att höga poäng genomgående innebär hög risk.
1.2.1 Lista på items
| itemnr | item |
|---|---|
| f66a | Jag gör tvärt emot vad människor säger åt mig att göra, bara för att göra dem arga. |
| f66b | Jag gillar att göra spännande och farliga saker, även om det är förbjudet. |
| f66c | Jag tål inte att bli provocerad, då kan jag slå till någon. |
| f66d | Jag ljuger för att få fördelar eller slippa göra jobbiga saker. |
| f66e | Om jag blir arg på någon drar jag mig inte för att skada honom/henne. |
| f66f | Jag är ofta ute på natten tillsammans med kamrater. |
| f66g | Jag struntar i regler som hindrar mig från att göra det jag vill göra. |
| f66h | Jag tycker det är roligt att lösa svåra problem och uppgifter. |
| f66i | Jag ser mig själv som en ganska impulsiv person. |
| f66j | Jag vill gärna vara där det händer spännande saker. |
| f66k | Jag kan få andra att tro på nästan vad som helst. |
| f66l | Jag blir ofta osäker när jag ställs inför nya uppgifter. |
| f66m | Jag tänker oftast efter innan jag talar eller gör saker. |
| f66n | Jag gör dumma saker även om de är lite farliga. |
| f66o | Jag vill gärna se hur långt jag kan gå innan folk får nog. |
| f66p | Det är fel att fuska i skolan. |
| f66q | Jag tycker att det är OK att ta något utan att fråga, om man inte blir upptäckt. |
| f66r | Det händer att jag gör saker utan att tänka mig för. |
| f66s | Om jag ställs inför en svår uppgift så väljer jag att göra något annat. |
| f66t | Den som gör mig arg ger jag mig på, även om han/hon inte slagit mig först. |
| f66u | Det är viktigt att vara ärlig mot föräldrarna, även om de blir arga. |
I listan ovan är items som utgör det nya indexet markerade med färg.
Svarskategorierna fungerar acceptabelt för samtliga items i det nya indexet.
Grönmarkerade items utgör index “Utagerande”. Den explorativa analysen visar att även en “positiv” individfaktor är möjlig att sätta samman, dock gör innehållet i frågorna att det är oklart vilket index frågorna skulle utgöra tillsammans.
Analyser av hittills använda delskalor i sammanställningar av Stockholmsenkäten finns under se Sektion 2.19.
1.2.2 Mätegenskaper
| itemnr | item |
|---|---|
| f66c | Jag tål inte att bli provocerad, då kan jag slå till någon. |
| f66d | Jag ljuger för att få fördelar eller slippa göra jobbiga saker. |
| f66g | Jag struntar i regler som hindrar mig från att göra det jag vill göra. |
| f66j | Jag vill gärna vara där det händer spännande saker. |
| f66k | Jag kan få andra att tro på nästan vad som helst. |
| f66n | Jag gör dumma saker även om de är lite farliga. |
| f66o | Jag vill gärna se hur långt jag kan gå innan folk får nog. |
| f66q | Jag tycker att det är OK att ta något utan att fråga, om man inte blir upptäckt. |
| f66r | Det händer att jag gör saker utan att tänka mig för. |

Reliabilitetskurvan visar hur indexets frågor tillsammans ger olika mycket information om respondenterna längs indexets spann. Där kurvan är som högst har indexet bäst mätprecision och kan bäst urskilja olika nivåer av mätvärden.
De streckade linjerna i figuren motsvarar reliabilitet på 0.7 (nedre linjen) och 0.8, på en skala från 0 till 1. Att dessa värden indikeras i figuren beror på att konventionen är att 0.7 är den lägsta nivån som anses acceptabel. Helst bör så många respondenter som möjligt finnas inom det område där indexet/enkätfrågorna sammantaget uppnår reliabilitet på 0.7 eller högre. Figurtexten ger viktig information om hur indexets reliabilitet förhåller sig till respondenternas egenskaper.
Det är viktigt att visa reliabilitet som en kurva snarare en ett enskilt värde (som t.ex. Cronbach’s alpha), eftersom reliabiliteten aldrig är samma över hela skalan.
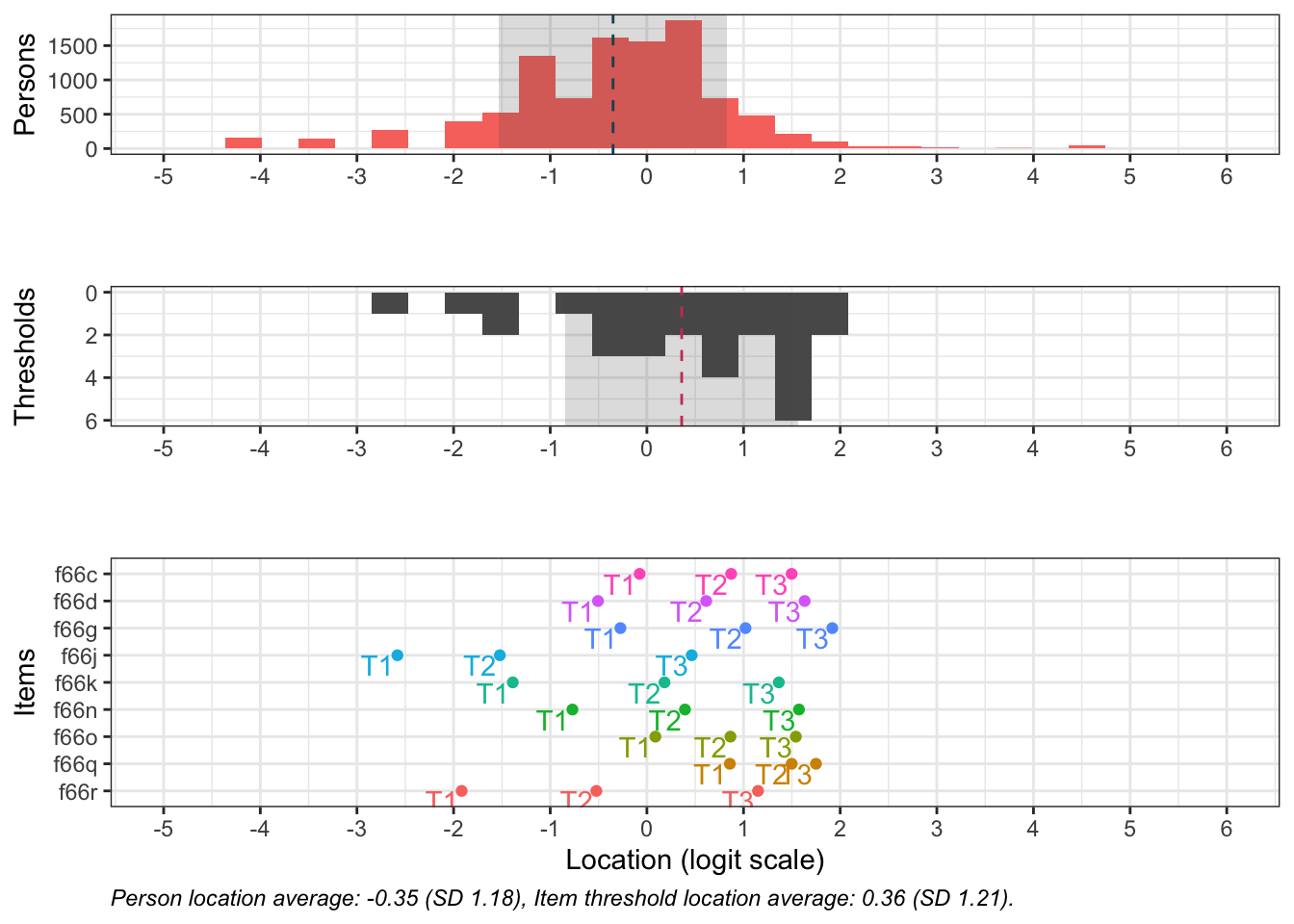
Denna figur visar hur väl items passar respondenterna (de som besvarat enkätfrågorna). Överst syns respondenternas indexvärden, där högre värden motsvarar högre risk.
Nederst finns frågornas tröskelvärden, som beskriver punkten på skalan där en högre svarskategori blir mer sannolik än den lägre. I mitten finns antalet tröskelvärden sammanräknade i staplar.
De två översta delarna visar även medelvärde för respondenter och item-trösklar med en streckad vertikal linje. I idealfallet ligger dessa medelvärden nära varandra, och de rosa och mörkgrå staplarna matchar varandra spegelvänt. Skulle de i stället ligga långt från varandra passar frågorna inte respondenterna.
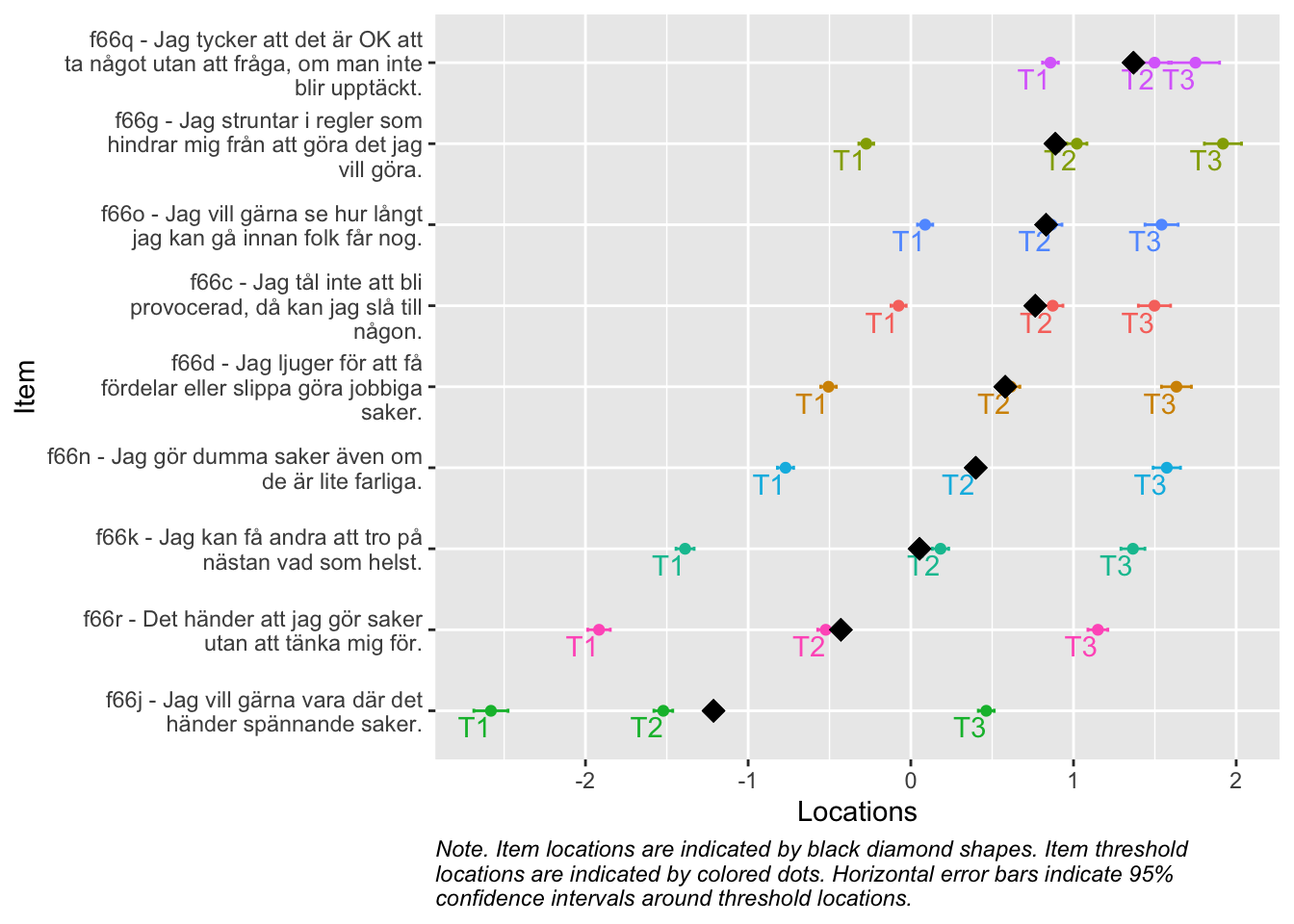
Denna figur rangordnar items för att tydliggöra vilka frågor som, utifrån svarsdata, ger information om olika nivåer av indexvärdet. Items som ligger högre upp mäter högre nivåer av indexet bättre, och omvänt.
1.3 Skola
Item/frågor har etiketter f54a-f54r i datafilen, och motsvaras av fråga 55 i PDF-filen med frågor.
“Hur väl stämmer följande påståenden in på dig din skolsituation?” följs av de ingående frågorna, alla med samma svarskategorier:
- ‘Stämmer mycket dåligt’
- ‘Stämmer ganska dåligt’
- ‘Stämmer ganska bra’
- ‘Stämmer mycket bra’
Items F65a b c gäller senaste betyg (Streck eller A-F) för svenska, engelska och matematik. Vi antar att frågorna om betyg inte lämpar sig att utgöra index tillsammans med andra frågor, eftersom de är av skild karaktär, så de utelämnas i denna analys.
F55, 56 och 59 angår hur ofta något hänt under senaste läsåret. Det visade sig dock att F55, 56 och 59 korrelerade alltför mycket med varandra, och uppvisade omfattande problem med svarskategorierna, så de har exkluderats ur analysen nedan.
Analyser av hittills använda delskalor i sammanställningar av Stockholmsenkäten finns under se Sektion 3.20.
1.3.1 Lista på items
| itemnr | item |
|---|---|
| f54a | Jag vet vilka regler som gäller på den här skolan. |
| f54b | Jag trivs bra i skolan. |
| f54c | Vi elever är med och planerar vad vi skall göra i undervisningen. |
| f54d | Lärarna berömmer elever som gör något bra i skolan. |
| f54e | Det är hög ljudnivå och stökigt på lektionerna. |
| f54f | Skolarbetet känns meningslöst. |
| f54g | Vi elever får vara med och bestämma över saker som är viktiga för oss. |
| f54h | Lärarna förklarar vad vi får och vad vi inte får göra. |
| f54i | I början av lektionerna tar det minst fem minuter innan arbetet kan börja |
| f54j | Skolan berättar för mina föräldrar om jag gjort något bra. |
| f54k | Elevernas åsikter tas inte på allvar i den här skolan. |
| f54l | Vuxna ingriper om någon blir trakasserad eller mobbad. |
| f54m | Mina lärare ger mig inget beröm om jag jobbar hårt. |
| f54n | Jag ser fram emot att gå till lektionerna. |
| f54o | Jag är orolig för att utsättas för brott i skolan. (t.ex. stöld, misshandel etc) |
| f54p | De flesta av mina lärare har intressant undervisning. |
| f54q | Skolarbetet gör mig förvirrad. |
| f54r | Om man inte förstår får man direkt hjälp av läraren. |
| F55 | Har du varit borta från skolan det här läsåret därför att du var sjuk eller mådde dåligt? |
| F56 | Har du skolkat en hel dag från skolan det här läsåret? |
| F59 | Har du fuskat på läxförhör eller prov i skolan det här läsåret? |
| F65a | Vad hade du för betyg förra terminen (senast) i svenska? |
| F65b | Vad hade du för betyg förra terminen (senast) i engelska? |
| F65c | Vad hade du för betyg förra terminen (senast) i matematik? |
| F61 | Hur ofta har du blivit mobbad eller trakasserad i skolan det här läsåret? |
| F61 | Hur ofta har du blivit mobbad eller trakasserad i skolan det här läsåret? |
Skolfrågorna fungerar bäst som två separata index.
Grönmarkerade items i tabellen ovan bildar indexet “Positiv skolanknytning”, medan de rödmarkerade bildar “Vantrivsel i skolan”.
1.3.2 Svarskategorier som åtgärdats:
- f54a och b - vi slår ihop de två högsta kategorierna (2 och 3)
- f54o - vi slår ihop mittenkategorierna (1 och 2)
1.3.3 Mätegenskaper Positiv skolanknytning
| itemnr | item |
|---|---|
| f54a | Jag vet vilka regler som gäller på den här skolan. |
| f54b | Jag trivs bra i skolan. |
| f54d | Lärarna berömmer elever som gör något bra i skolan. |
| f54g | Vi elever får vara med och bestämma över saker som är viktiga för oss. |
| f54h | Lärarna förklarar vad vi får och vad vi inte får göra. |
| f54j | Skolan berättar för mina föräldrar om jag gjort något bra. |
| f54l | Vuxna ingriper om någon blir trakasserad eller mobbad. |
| f54n | Jag ser fram emot att gå till lektionerna. |
| f54r | Om man inte förstår får man direkt hjälp av läraren. |
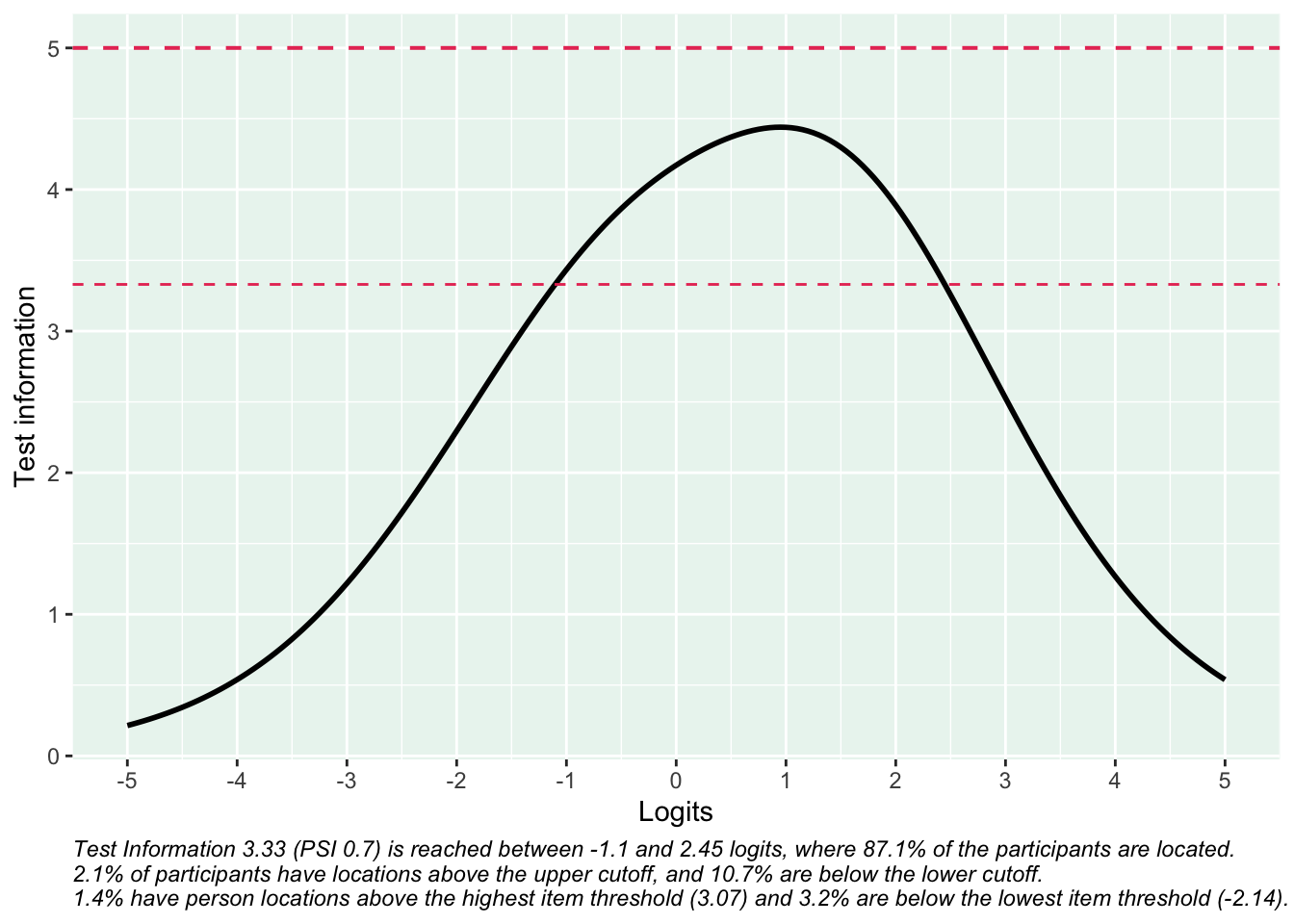
Reliabilitetskurvan visar hur indexets frågor tillsammans ger olika mycket information om respondenterna längs indexets spann. Där kurvan är som högst har indexet bäst mätprecision och kan bäst urskilja olika nivåer av mätvärden.
De streckade linjerna i figuren motsvarar reliabilitet på 0.7 (nedre linjen) och 0.8, på en skala från 0 till 1. Att dessa värden indikeras i figuren beror på att konventionen är att 0.7 är den lägsta nivån som anses acceptabel. Helst bör så många respondenter som möjligt finnas inom det område där indexet/enkätfrågorna sammantaget uppnår reliabilitet på 0.7 eller högre. Figurtexten ger viktig information om hur indexets reliabilitet förhåller sig till respondenternas egenskaper.
Det är viktigt att visa reliabilitet som en kurva snarare en ett enskilt värde (som t.ex. Cronbach’s alpha), eftersom reliabiliteten aldrig är samma över hela skalan.

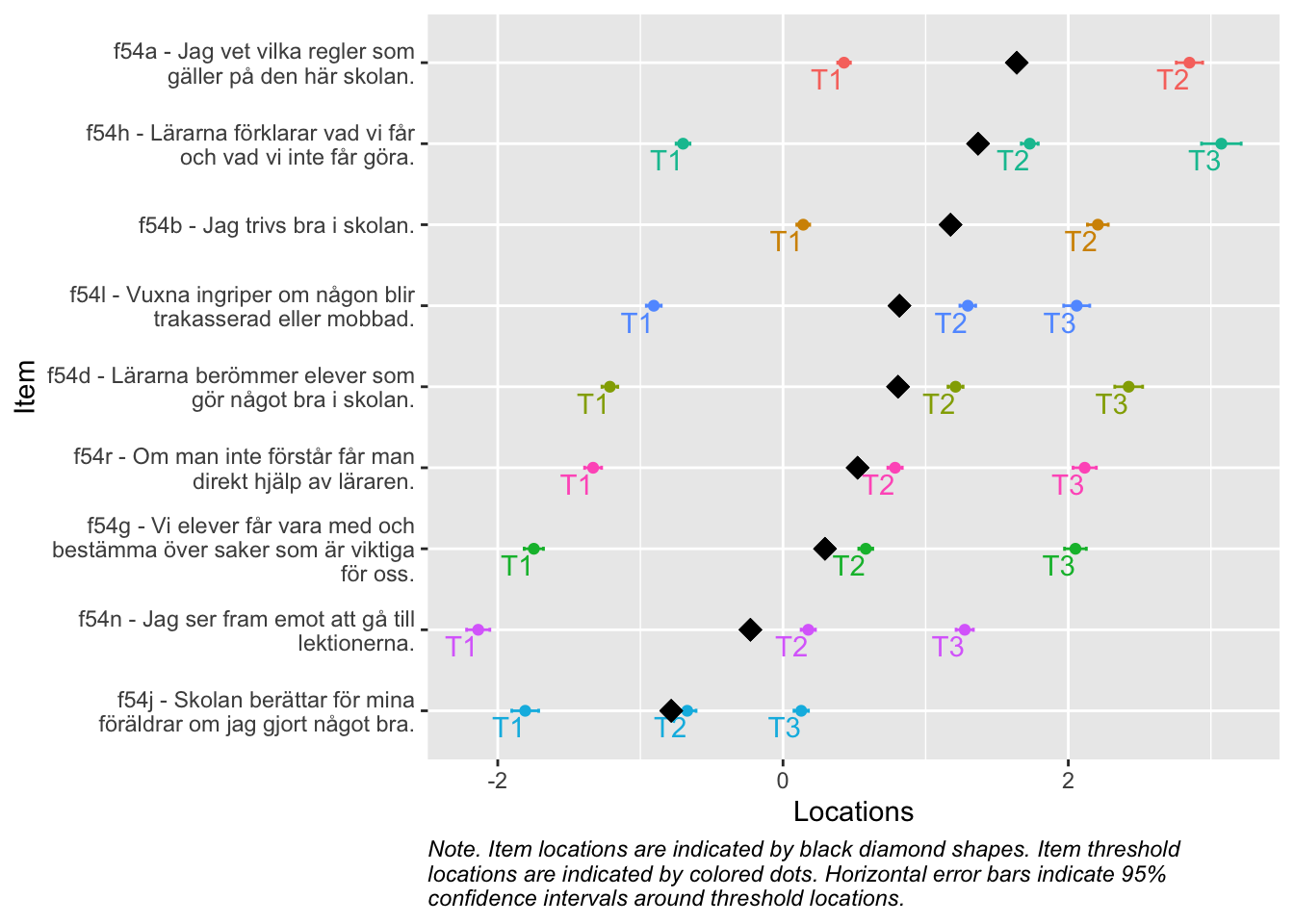
Denna figur visar hur väl items passar respondenterna (de som besvarat enkätfrågorna). Överst syns respondenternas indexvärden, där högre värden motsvarar högre risk.
Nederst finns frågornas tröskelvärden, som beskriver punkten på skalan där en högre svarskategori blir mer sannolik än den lägre. I mitten finns antalet tröskelvärden sammanräknade i staplar.
De två översta delarna visar även medelvärde för respondenter och item-trösklar med en streckad vertikal linje. I idealfallet ligger dessa medelvärden nära varandra, och de rosa och mörkgrå staplarna matchar varandra spegelvänt. Skulle de i stället ligga långt från varandra passar frågorna inte respondenterna.
Denna figur rangordnar items för att tydliggöra vilka frågor som, utifrån svarsdata, ger information om olika nivåer av indexvärdet. Items som ligger högre upp mäter högre nivåer av indexet bättre, och omvänt.
1.3.4 Mätegenskaper Vantrivsel i skolan
| itemnr | item |
|---|---|
| f54e | Det är hög ljudnivå och stökigt på lektionerna. |
| f54f | Skolarbetet känns meningslöst. |
| f54i | I början av lektionerna tar det minst fem minuter innan arbetet kan börja |
| f54k | Elevernas åsikter tas inte på allvar i den här skolan. |
| f54m | Mina lärare ger mig inget beröm om jag jobbar hårt. |
| f54o | Jag är orolig för att utsättas för brott i skolan. (t.ex. stöld, misshandel etc) |
| f54q | Skolarbetet gör mig förvirrad. |
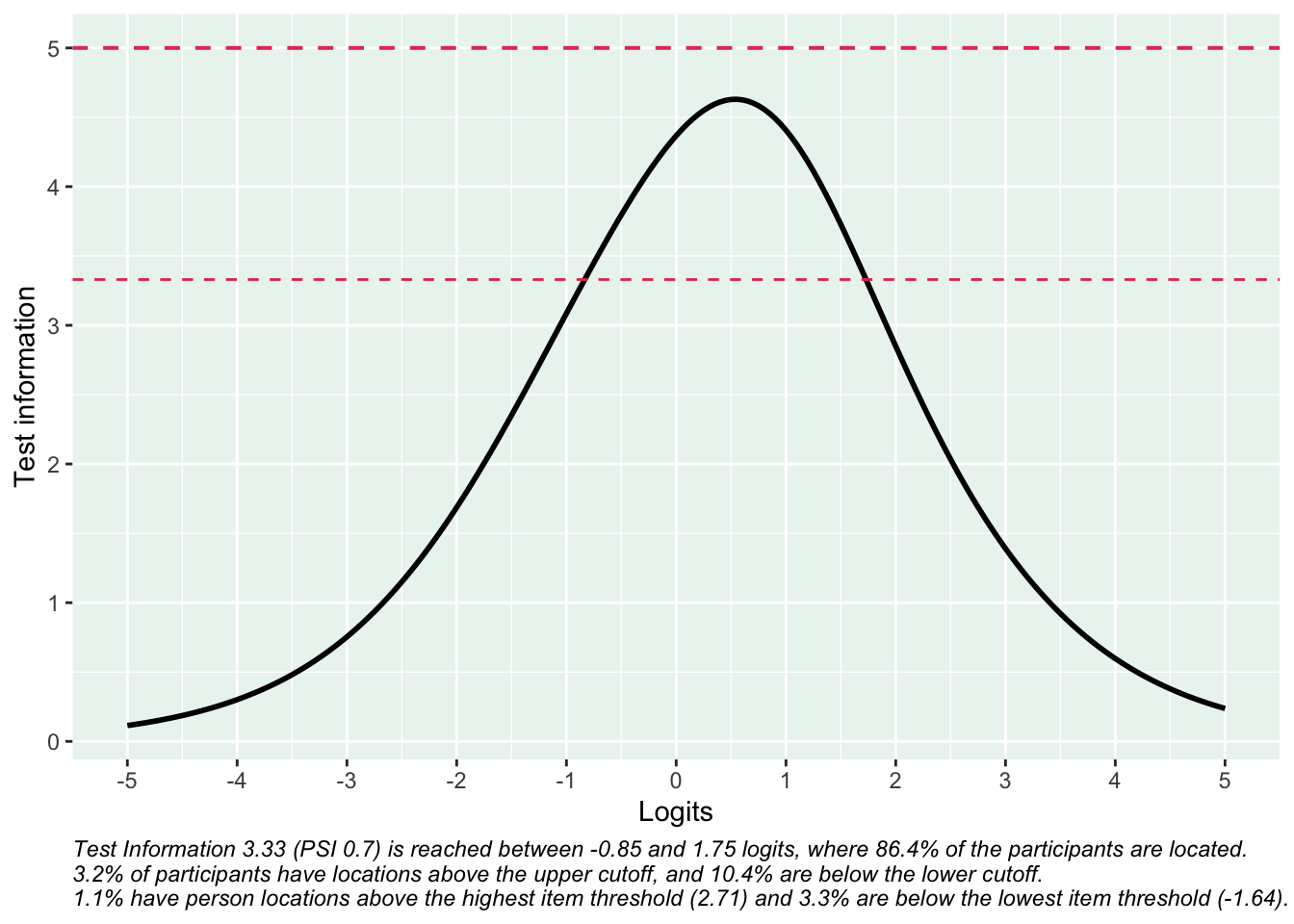
Reliabilitetskurvan visar hur indexets frågor tillsammans ger olika mycket information om respondenterna längs indexets spann. Där kurvan är som högst har indexet bäst mätprecision och kan bäst urskilja olika nivåer av mätvärden.
De streckade linjerna i figuren motsvarar reliabilitet på 0.7 (nedre linjen) och 0.8, på en skala från 0 till 1. Att dessa värden indikeras i figuren beror på att konventionen är att 0.7 är den lägsta nivån som anses acceptabel. Helst bör så många respondenter som möjligt finnas inom det område där indexet/enkätfrågorna sammantaget uppnår reliabilitet på 0.7 eller högre. Figurtexten ger viktig information om hur indexets reliabilitet förhåller sig till respondenternas egenskaper.
Det är viktigt att visa reliabilitet som en kurva snarare en ett enskilt värde (som t.ex. Cronbach’s alpha), eftersom reliabiliteten aldrig är samma över hela skalan.
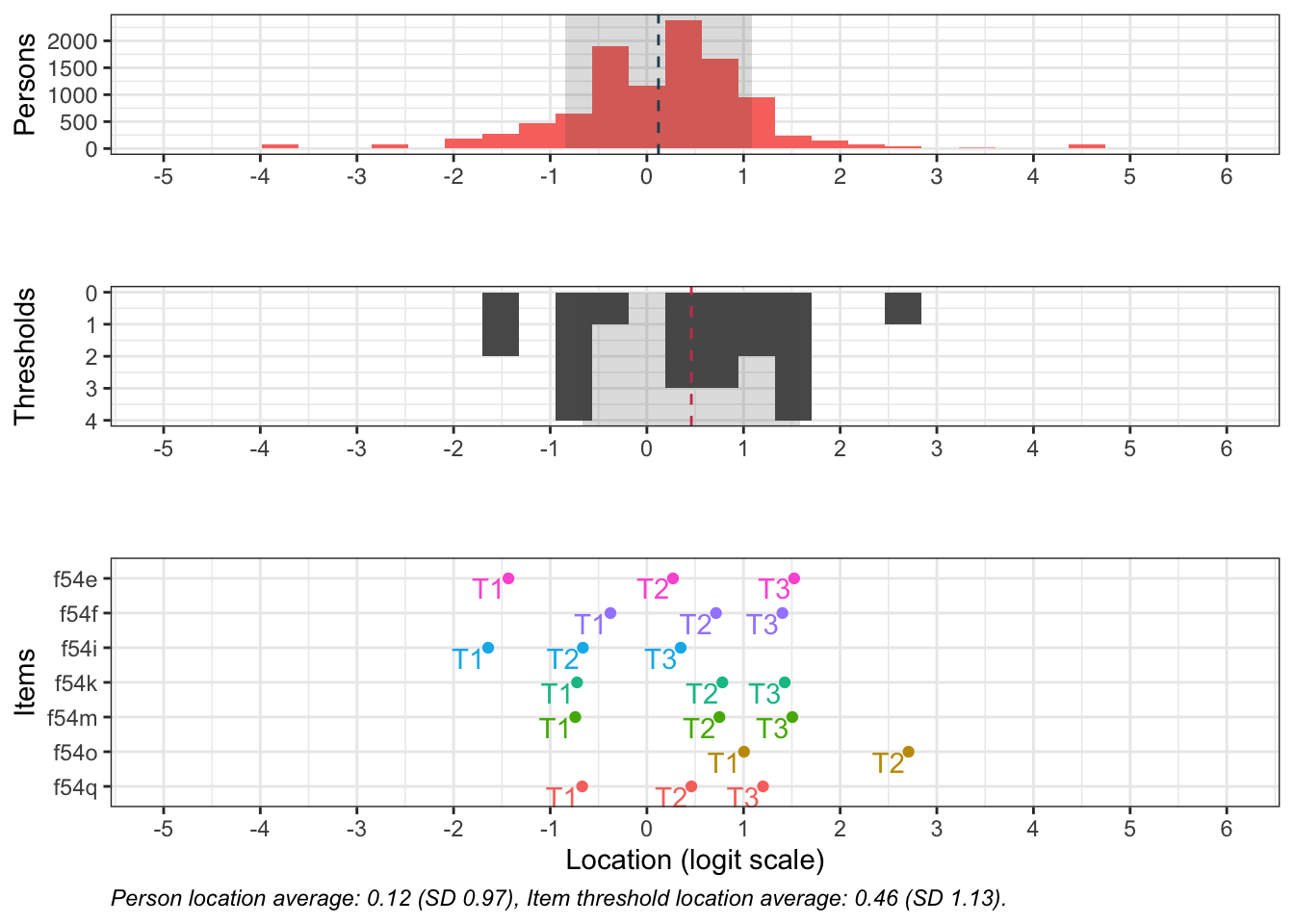
Denna figur visar hur väl items passar respondenterna (de som besvarat enkätfrågorna). Överst syns respondenternas indexvärden, där högre värden motsvarar högre risk.
Nederst finns frågornas tröskelvärden, som beskriver punkten på skalan där en högre svarskategori blir mer sannolik än den lägre. I mitten finns antalet tröskelvärden sammanräknade i staplar.
De två översta delarna visar även medelvärde för respondenter och item-trösklar med en streckad vertikal linje. I idealfallet ligger dessa medelvärden nära varandra, och de rosa och mörkgrå staplarna matchar varandra spegelvänt. Skulle de i stället ligga långt från varandra passar frågorna inte respondenterna.
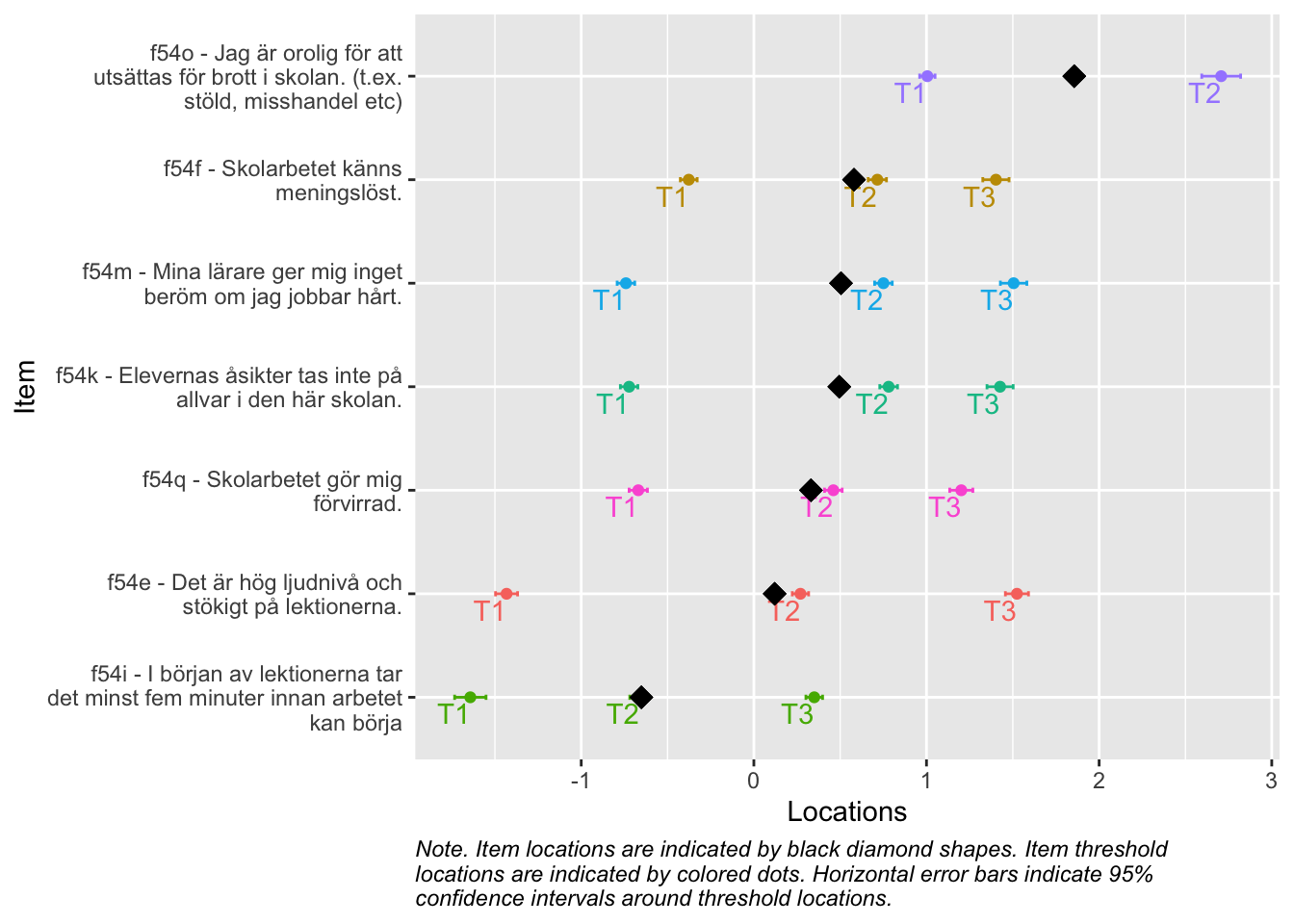
Denna figur rangordnar items för att tydliggöra vilka frågor som, utifrån svarsdata, ger information om olika nivåer av indexvärdet. Items som ligger högre upp mäter högre nivåer av indexet bättre, och omvänt.
1.4 Psykiska/psykosomatiska besvär
Item/frågor har etiketter F88-F99 i datafilen, och motsvaras av fråga 90-101 i PDF-filen med frågor.
Samtliga frågor har fem svarskategorier, vilka varierar mellan frågorna. Fem frågor har svarskategorier från “Aldrig” till “Flera gånger i veckan”. Sex frågor har från “Sällan” till “Väldigt ofta”, och en från “Inte alls” till “Väldigt mycket”.
Svarsdata har kodats så att högre poäng innebär mera besvär/högre risk.
Sektionen i enkäten inleds med meningen: “Några frågor om hur du mår”.
1.4.1 Lista på items
| itemnr | item |
|---|---|
| F88 | Hur ofta har du haft huvudvärk detta läsår? |
| F89 | Känner du dig ledsen och deppig utan att veta varför? |
| F90 | Händer det att du känner dig rädd utan att veta varför? |
| F91 | Hur ofta har du dålig aptit? |
| F92 | Hur mycket skulle du vilja ändra på dig själv? |
| F93 | Hur ofta har du under detta läsår haft ”nervös mage” (t.ex. magknip, magkramper, orolig mage, illamående, gaser, förstoppning eller diarré)? |
| F94 | Hur ofta tycker du att du inget duger till? |
| F95 | Hur ofta har du under detta läsår haft svårt att somna? |
| F96 | Är du nöjd med ditt utseende? |
| F97 | Känner du dig slö och olustig? |
| F98 | Hur ofta har det hänt under detta läsår att du sovit oroligt och vaknat under natten? |
| F99 | Hur ofta tycker du att det är riktigt härligt att leva? |
Det är möjligt att skapa ett index med enbart psykosomatiska items som har acceptabel reliabilitet, bestående av “F88”, “F91”, “F93”, “F95” och “F98”. Detta är samma index som används sedan tidigare i redovisningen av Stockholmsenkäten. Dock betecknas det indexet som “Psykisk hälsa” och omvänds, vilket innebär att låga nivåer av psykosomatiska besvär beskrivs som “god psykisk hälsa”.
Genom att lägga till fyra items kan vi ta fram ett bredare index med bättre mätegenskaper som kan rubriceras som “Psykiska/psykosomatiska besvär”. Det är dessa nio items som är markerade med färg i tabellen ovan.
1.4.2 Svarskategorier som åtgärdats
Vi slår ihop följande svarskategorier:
- För items 89, 90, 91, 94: 1 & 2 och 3 & 4
- För items 95, 97: 0 & 1
- För items 92, 93, 96, 98, 99: 3 & 4
1.4.3 Mätegenskaper
| itemnr | item |
|---|---|
| F88 | Hur ofta har du haft huvudvärk detta läsår? |
| F89 | Känner du dig ledsen och deppig utan att veta varför? |
| F91 | Hur ofta har du dålig aptit? |
| F92 | Hur mycket skulle du vilja ändra på dig själv? |
| F93 | Hur ofta har du under detta läsår haft ”nervös mage” (t.ex. magknip, magkramper, orolig mage, illamående, gaser, förstoppning eller diarré)? |
| F95 | Hur ofta har du under detta läsår haft svårt att somna? |
| F97 | Känner du dig slö och olustig? |
| F98 | Hur ofta har det hänt under detta läsår att du sovit oroligt och vaknat under natten? |
| F99 | Hur ofta tycker du att det är riktigt härligt att leva? |
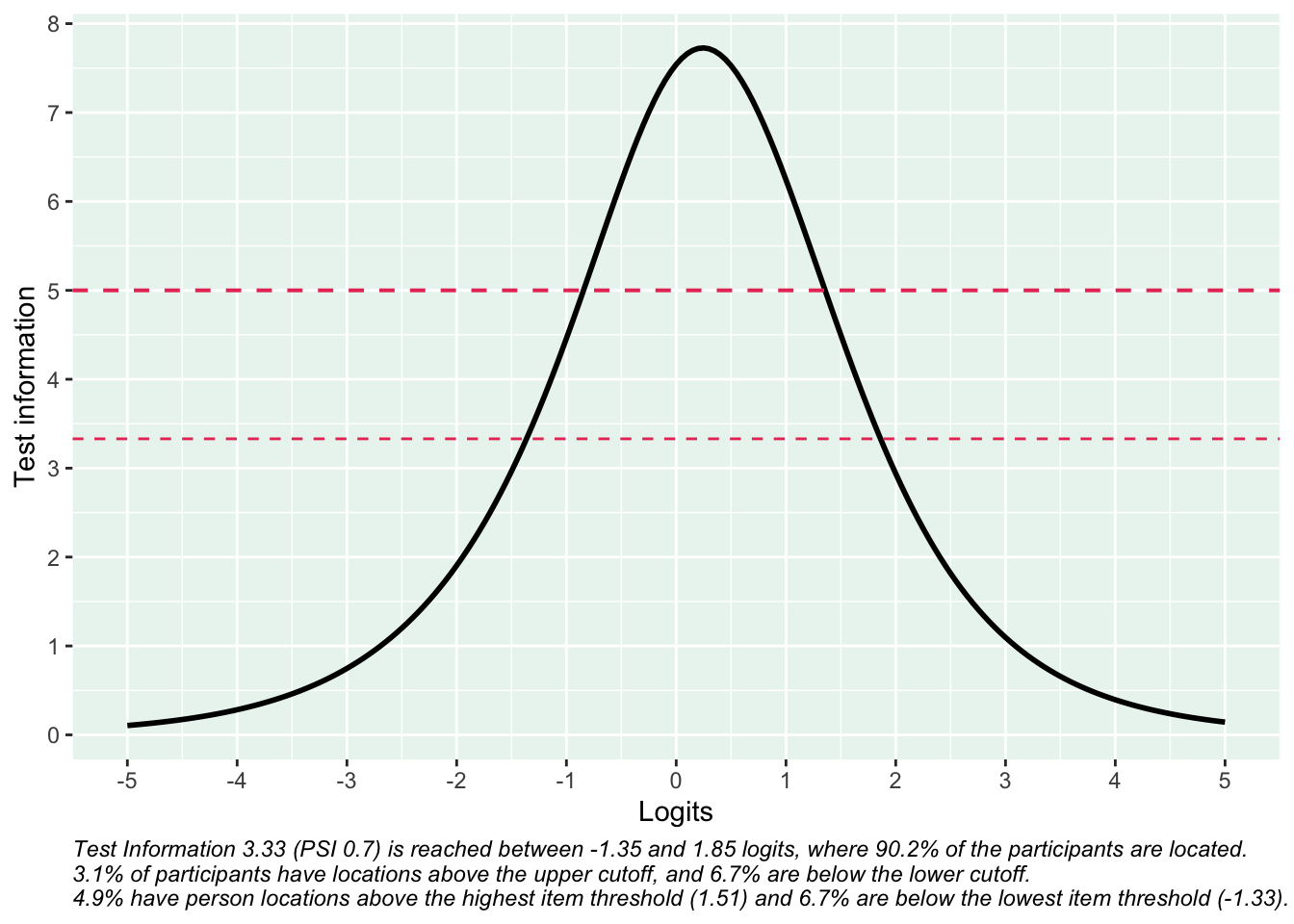
Reliabilitetskurvan visar hur indexets frågor tillsammans ger olika mycket information om respondenterna längs indexets spann. Där kurvan är som högst har indexet bäst mätprecision och kan bäst urskilja olika nivåer av mätvärden.
De streckade linjerna i figuren motsvarar reliabilitet på 0.7 (nedre linjen) och 0.8, på en skala från 0 till 1. Att dessa värden indikeras i figuren beror på att konventionen är att 0.7 är den lägsta nivån som anses acceptabel. Helst bör så många respondenter som möjligt finnas inom det område där indexet/enkätfrågorna sammantaget uppnår reliabilitet på 0.7 eller högre. Figurtexten ger viktig information om hur indexets reliabilitet förhåller sig till respondenternas egenskaper.
Det är viktigt att visa reliabilitet som en kurva snarare en ett enskilt värde (som t.ex. Cronbach’s alpha), eftersom reliabiliteten aldrig är samma över hela skalan.
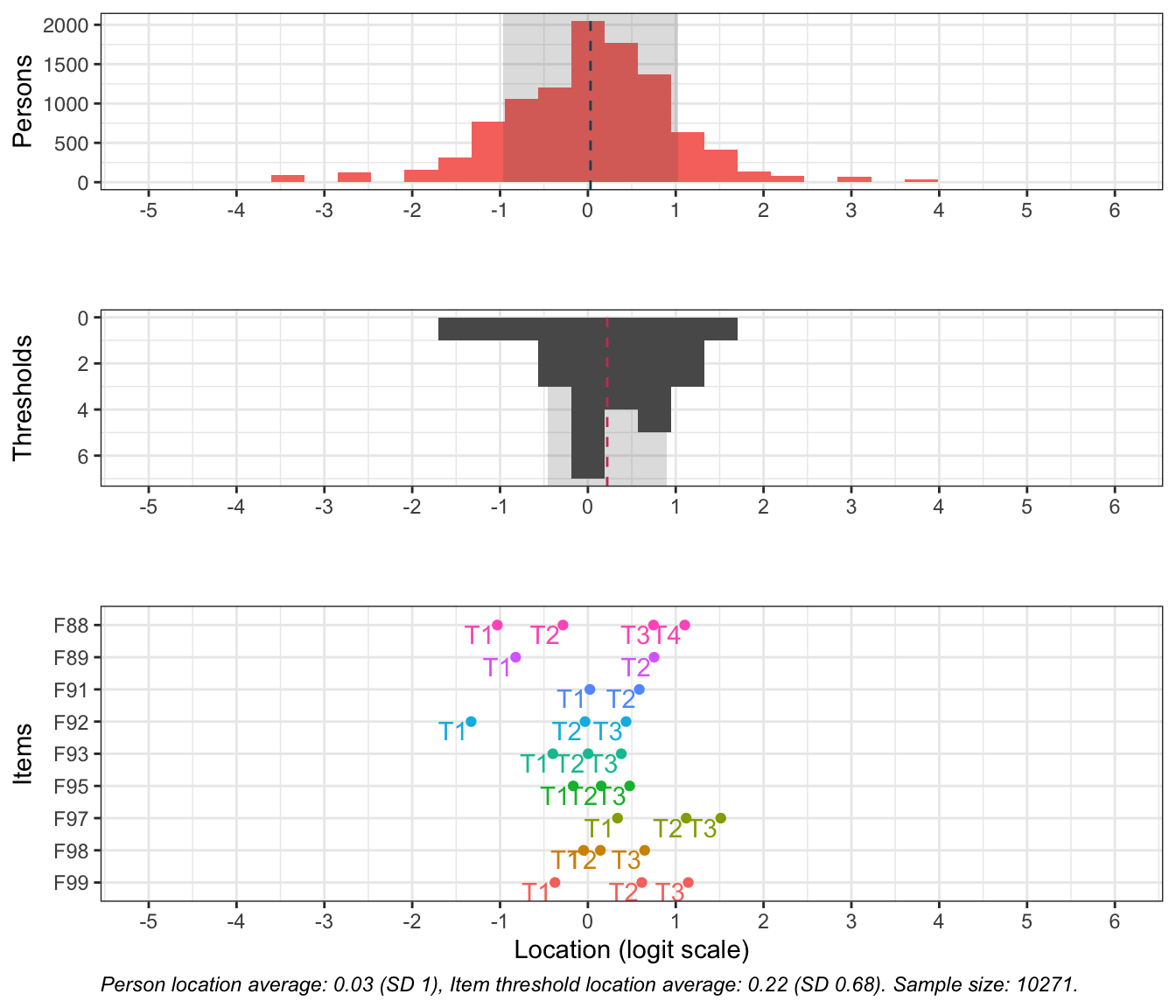
Denna figur visar hur väl items passar respondenterna (de som besvarat enkätfrågorna). Överst syns respondenternas indexvärden, där högre värden motsvarar högre risk.
Nederst finns frågornas tröskelvärden, som beskriver punkten på skalan där en högre svarskategori blir mer sannolik än den lägre. I mitten finns antalet tröskelvärden sammanräknade i staplar.
De två översta delarna visar även medelvärde för respondenter och item-trösklar med en streckad vertikal linje. I idealfallet ligger dessa medelvärden nära varandra, och de rosa och mörkgrå staplarna matchar varandra spegelvänt. Skulle de i stället ligga långt från varandra passar frågorna inte respondenterna.

Denna figur rangordnar items för att tydliggöra vilka frågor som, utifrån svarsdata, ger information om olika nivåer av indexvärdet. Items som ligger högre upp mäter högre nivåer av indexet bättre, och omvänt.
1.5 Föräldrafrågor
Item/frågor har etiketter F79-F82 samt f83a-h i datafilen, och motsvaras av fråga 81-84 samt 85 i PDF-filen med frågor.
Samtliga f83-frågor har fyra svarskategorier: “Stämmer mycket bra, Stämmer ganska bra, Stämmer ganska dåligt, Stämmer mycket dåligt”. Sektionen i enkäten inleds med meningen: “Hur väl stämmer följande påståenden in på hur dina föräldrar/vårdnadshavare är mot dig?”.
F79-81 har fyra svarsalternativ, som varierar med frågan, och F82 har bara två svarsalternativ (“Ja” eller “Nej”).
Svarsdata har kodats så att högre poäng innebär mera problem/högre risk. Svarsalternativet “Vet inte” har kodats som saknat svar.
En enkätfråga som inte tidigare ingått bland föräldrafrågorna har lagts till:
- F58 - “Hur skulle dina föräldrar reagera om du hade skolkat?”
Frågan har svarskategorier från De skulle reagera mycket kraftigt, till De skulle inte reagera alls, och har visat sig vara viktig att inkludera för att nå acceptabel reliabilitet bland föräldrafrågorna.
Analyser av hittills använda delskalor i sammanställningar av Stockholmsenkäten finns under se Sektion 5.19.
1.5.1 Lista på items
| itemnr | item |
|---|---|
| F79 | Vet dina föräldrar/vårdnadshavare var du är när du är ute med kamrater på kvällar? |
| F80 | Vet dina föräldrar/vårdnadshavare vilka kamrater du umgås med på din fritid? |
| F81 | Vet dina föräldrar/vårdnadshavare vad du spenderar dina pengar på? |
| F82 | Om du har ett personligt problem, kan du be någon av dina föräldrar/vårdnadshavare om hjälp? |
| f83a | De ger mig beröm när jag gör något bra. |
| f83b | De hotar med bestraffning för något jag gjort men genomför det inte. |
| f83c | De brukar uppmuntra och stötta mig. |
| f83d | Jag vet inte hur de reagerar när jag gjort något de inte gillar. |
| f83e | De märker när jag gör något bra. |
| f83f | Det humör de är på bestämmer hur de är mot mig. |
| f83g | Jag bryr mig om vad mina föräldrar/vårdnadshavare säger. |
| f83h | Mina föräldrar/vårdnadshavare är en förebild för mig. |
| F58 | Hur skulle dina föräldrar reagera om du hade skolkat? |
1.5.2 Svarskategorier som åtgärdats
De två högsta svarskategorierna slås samman för:
- F79
- f83a, e, och g.
1.5.3 Mätegenskaper
| itemnr | item |
|---|---|
| F80 | Vet dina föräldrar/vårdnadshavare vilka kamrater du umgås med på din fritid? |
| f83b | De hotar med bestraffning för något jag gjort men genomför det inte. |
| f83d | Jag vet inte hur de reagerar när jag gjort något de inte gillar. |
| f83e | De märker när jag gör något bra. |
| f83f | Det humör de är på bestämmer hur de är mot mig. |
| F58 | Hur skulle dina föräldrar reagera om du hade skolkat? |

Reliabilitetskurvan visar hur indexets frågor tillsammans ger olika mycket information om respondenterna längs indexets spann. Där kurvan är som högst har indexet bäst mätprecision och kan bäst urskilja olika nivåer av mätvärden.
De streckade linjerna i figuren motsvarar reliabilitet på 0.7 (nedre linjen) och 0.8, på en skala från 0 till 1. Att dessa värden indikeras i figuren beror på att konventionen är att 0.7 är den lägsta nivån som anses acceptabel. Helst bör så många respondenter som möjligt finnas inom det område där indexet/enkätfrågorna sammantaget uppnår reliabilitet på 0.7 eller högre. Figurtexten ger viktig information om hur indexets reliabilitet förhåller sig till respondenternas egenskaper.
Det är viktigt att visa reliabilitet som en kurva snarare en ett enskilt värde (som t.ex. Cronbach’s alpha), eftersom reliabiliteten aldrig är samma över hela skalan.
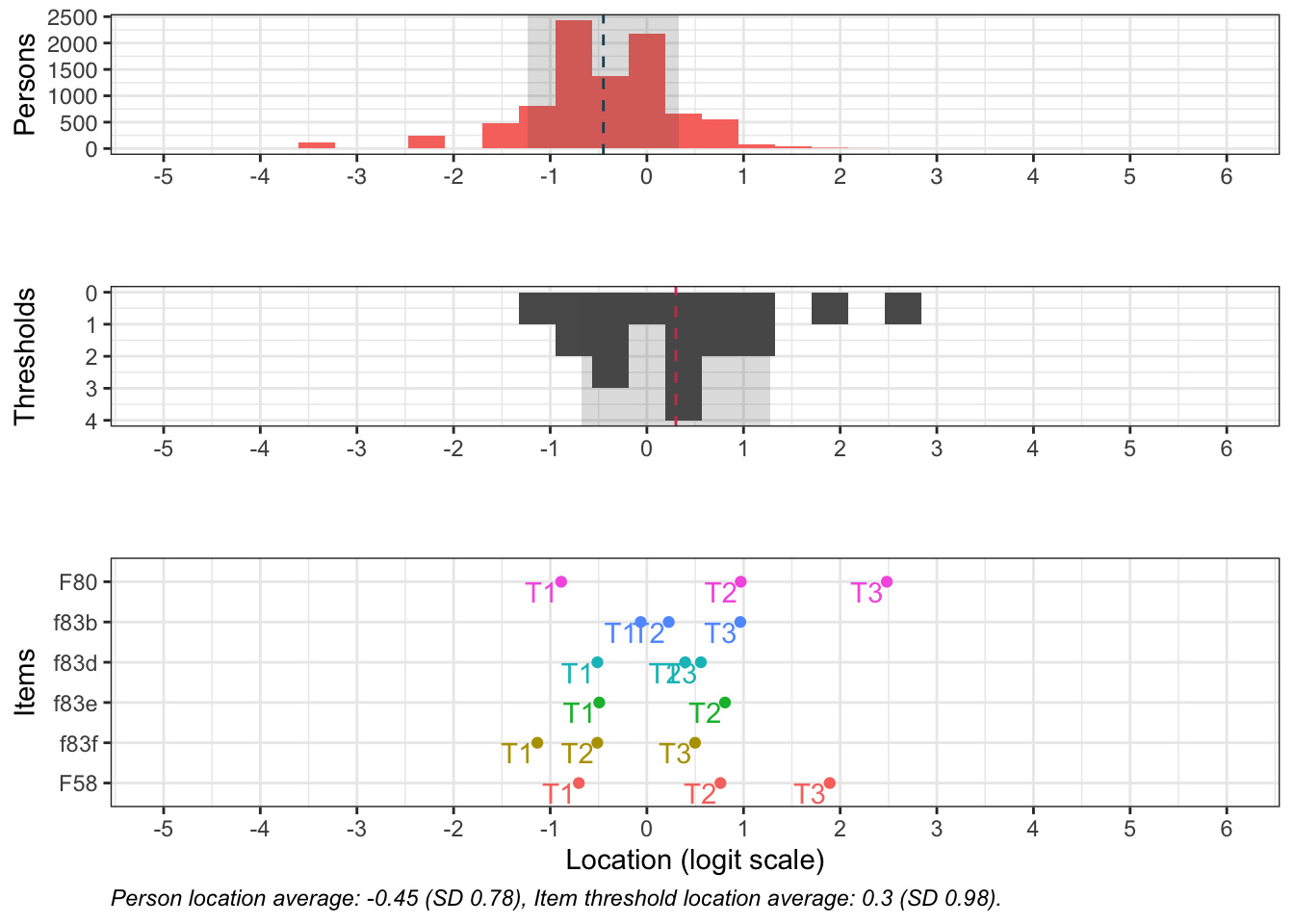
Denna figur visar hur väl items passar respondenterna (de som besvarat enkätfrågorna). Överst syns respondenternas indexvärden, där högre värden motsvarar högre risk.
Nederst finns frågornas tröskelvärden, som beskriver punkten på skalan där en högre svarskategori blir mer sannolik än den lägre. I mitten finns antalet tröskelvärden sammanräknade i staplar.
De två översta delarna visar även medelvärde för respondenter och item-trösklar med en streckad vertikal linje. I idealfallet ligger dessa medelvärden nära varandra, och de rosa och mörkgrå staplarna matchar varandra spegelvänt. Skulle de i stället ligga långt från varandra passar frågorna inte respondenterna.

Denna figur rangordnar items för att tydliggöra vilka frågor som, utifrån svarsdata, ger information om olika nivåer av indexvärdet. Items som ligger högre upp mäter högre nivåer av indexet bättre, och omvänt.
1.6 Kamrater och fritid
Item/frågor har etiketter F70 samt f86a-j i datafilen, och motsvaras av fråga 71 respektive 88 i PDF-filen med frågor.
Bland dessa frågor ingår även “prosocialt index”, som består av fyra items: F70, F86a, c och f.
Samtliga f86-frågor har fyra svarskategorier: “Ingen, Någon enstaka, Ungefär hälften, De flesta”. Sektionen i enkäten inleds med meningen: “Hur många av dina kamrater (inom och utom skolan):”.
F70 har fyra svarsalternativ: “Ofta, Ibland, Sällan, Aldrig”.
Svarsdata har kodats så att högre poäng innebär mera problem/högre “risk”. Svarsalternativet “Vet inte” har kodats som saknat svar.
1.6.1 Lista på items
| itemnr | item |
|---|---|
| F70 | Brukar du delta i någon ledarledd fritidsaktivitet eller träning? |
| f86a | Motionerar och tränar regelbundet? |
| f86b | Har snattat/klottrat/vandaliserat? |
| f86c | Är med i någon förening? |
| f86d | Röker tobak? |
| f86e | Slåss? |
| f86f | Är duktiga i skolan? |
| f86g | Dricker sig berusad på alkohol? |
| f86h | Använder narkotika? |
| f86i | Skolkar? |
| f86j | Har rånat, gjort inbrott eller stulit en bil? |
Analysen visar att items kan delas upp i negativa och positiva, men ingen av dem klarar av att bilda ett fungerande index med adekvat reliabilitet.
1.7 Närsamhälle
Frågorna har beteckning F100 och f101a till f101l i datafilen, och överensstämmer med 102 och 103 i PDF-filen.
F100 ställer frågan “Om du går ut ensam sent en kväll i området där du bor, känner du dig då…” med svarsalternativen:
- Mycket trygg
- Ganska trygg
- Ganska otrygg
- Mycket otrygg
- Går ej ut på kvällen av oro för att utsättas för brott <— kodas som missing/NA pga ej användbart i ordinala data. Skulle ev. kunna ses som likvärdigt som Mycket Otrygg, eller som ännu “värre” (ordinalt ett steg över), men det är diskutabelt.
- Går ej ut på kvällen av andra orsaker <— kodas som missing/NA pga ej användbart i ordinala data. Det är alltför oklart vad “andra orsaker” är.
Ovanstående frågor kodas om till siffror 0-3, där hög siffra är Mycket otrygg.
f101-frågorna föregås av frågan “Hur väl stämmer följande påståenden in på ditt bostadsområde?”. Samtliga frågor har samma fyra svarskategorier:
- ‘Stämmer mycket dåligt’
- ‘Stämmer ganska dåligt’
- ‘Stämmer ganska bra’
- ‘Stämmer mycket bra’
Frågorna är blandat negativt och positivt formulerade, och vid omkodning från ovanstående svarskategorier till siffror 0-3 har positiva frågor vänts så att höga värden alltid innebär högre risk.
1.7.1 Lista på items
| itemnr | item |
|---|---|
| F100 | Om du går ut ensam sent en kväll i området där du bor, känner du dig då... |
| f101a | Vandalism (klotter, olaglig graffiti, förstörelse) är vanligt i bostadsområdet. |
| f101b | Om en vuxen såg mig göra något olagligt i mitt bostadsområde skulle nog mina föräldrar få reda på det. |
| f101c | Vuxna skulle ingripa om någon helt öppet försökte sälja narkotika till ungdomar. |
| f101d | Det finns personer som säljer narkotika i bostadsområdet. |
| f101e | På vardagskvällar finns det många berusade utomhus i bostadsområdet. |
| f101f | Så fort jag kan vill jag flytta till ett annat bostadsområde. |
| f101g | Det är ovanligt med våldsbrott (misshandel, rån, våldtäkt) i det här bostadsområdet. |
| f101h | Vuxna skulle ingripa om det blev ett slagsmål framför mitt hus. |
| f101i | Om jag blev rånad på en allmän plats i bostadsområdet skulle vuxna ingripa. |
| f101j | Mina grannar brukar heja/hälsa på mig när vi möts. |
| f101k | Jag trivs bra i mitt bostadsområde. |
| f101l | Om jag var tvungen att flytta skulle jag sakna bostadsområdet jag bor i. |
Vi har arbetat med två index utifrån frågorna om Närsamhälle, där det ena inte kunde uppnå adekvat reliabilitet, men det andra kunde det, även om reliabiliteten är låg och främst gäller de som har högre nivåer av risk.
1.7.2 Svarskategorier som åtgärdats
f101k och j har fått mittenkategorierna hopslagna.
1.7.3 Mätegenskaper
| itemnr | item |
|---|---|
| f101b | Om en vuxen såg mig göra något olagligt i mitt bostadsområde skulle nog mina föräldrar få reda på det. |
| f101c | Vuxna skulle ingripa om någon helt öppet försökte sälja narkotika till ungdomar. |
| f101g | Det är ovanligt med våldsbrott (misshandel, rån, våldtäkt) i det här bostadsområdet. |
| f101i | Om jag blev rånad på en allmän plats i bostadsområdet skulle vuxna ingripa. |
| f101j | Mina grannar brukar heja/hälsa på mig när vi möts. |
| f101l | Om jag var tvungen att flytta skulle jag sakna bostadsområdet jag bor i. |
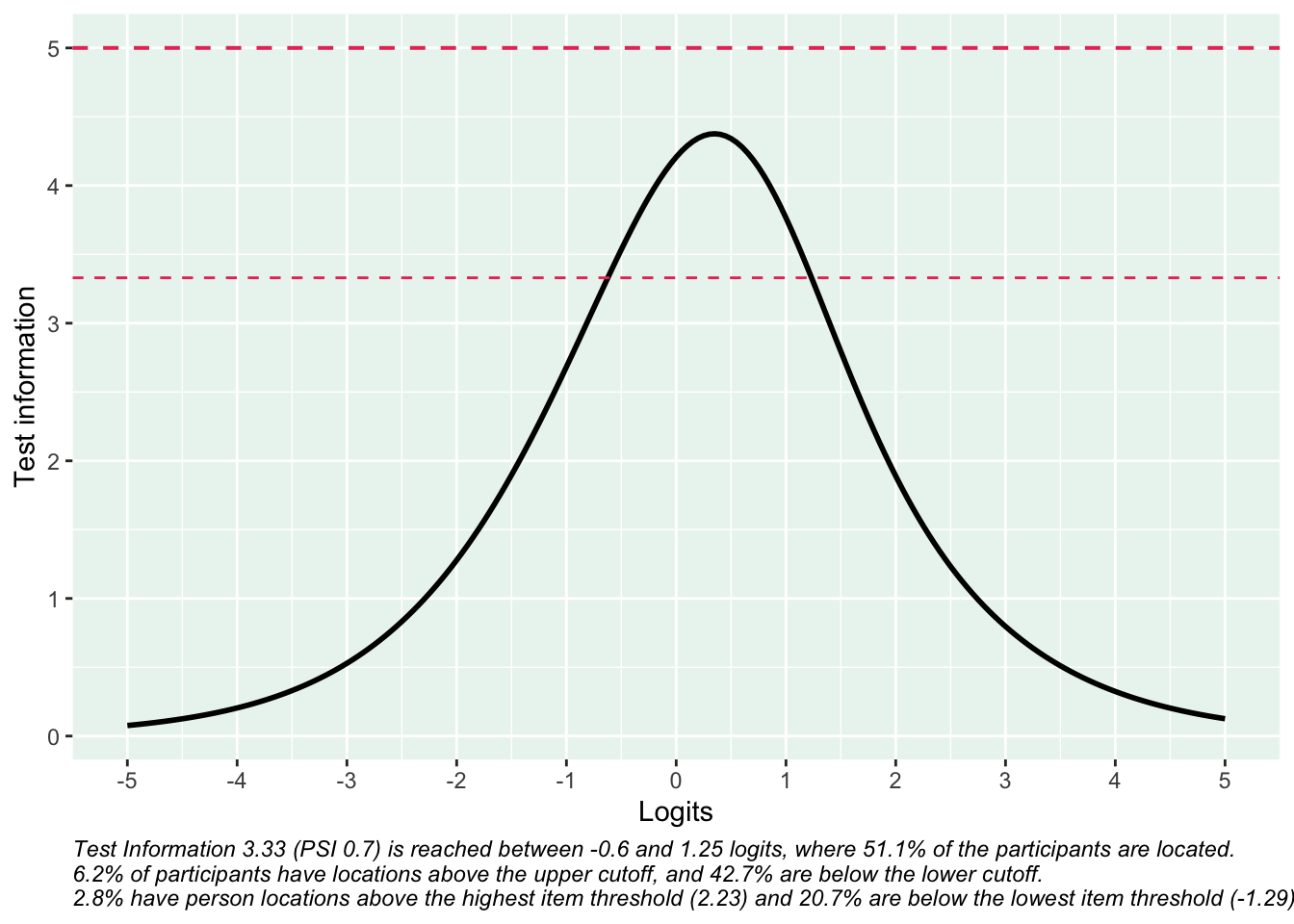
Reliabilitetskurvan visar hur indexets frågor tillsammans ger olika mycket information om respondenterna längs indexets spann. Där kurvan är som högst har indexet bäst mätprecision och kan bäst urskilja olika nivåer av mätvärden.
De streckade linjerna i figuren motsvarar reliabilitet på 0.7 (nedre linjen) och 0.8, på en skala från 0 till 1. Att dessa värden indikeras i figuren beror på att konventionen är att 0.7 är den lägsta nivån som anses acceptabel. Helst bör så många respondenter som möjligt finnas inom det område där indexet/enkätfrågorna sammantaget uppnår reliabilitet på 0.7 eller högre. Figurtexten ger viktig information om hur indexets reliabilitet förhåller sig till respondenternas egenskaper.
Det är viktigt att visa reliabilitet som en kurva snarare en ett enskilt värde (som t.ex. Cronbach’s alpha), eftersom reliabiliteten aldrig är samma över hela skalan.
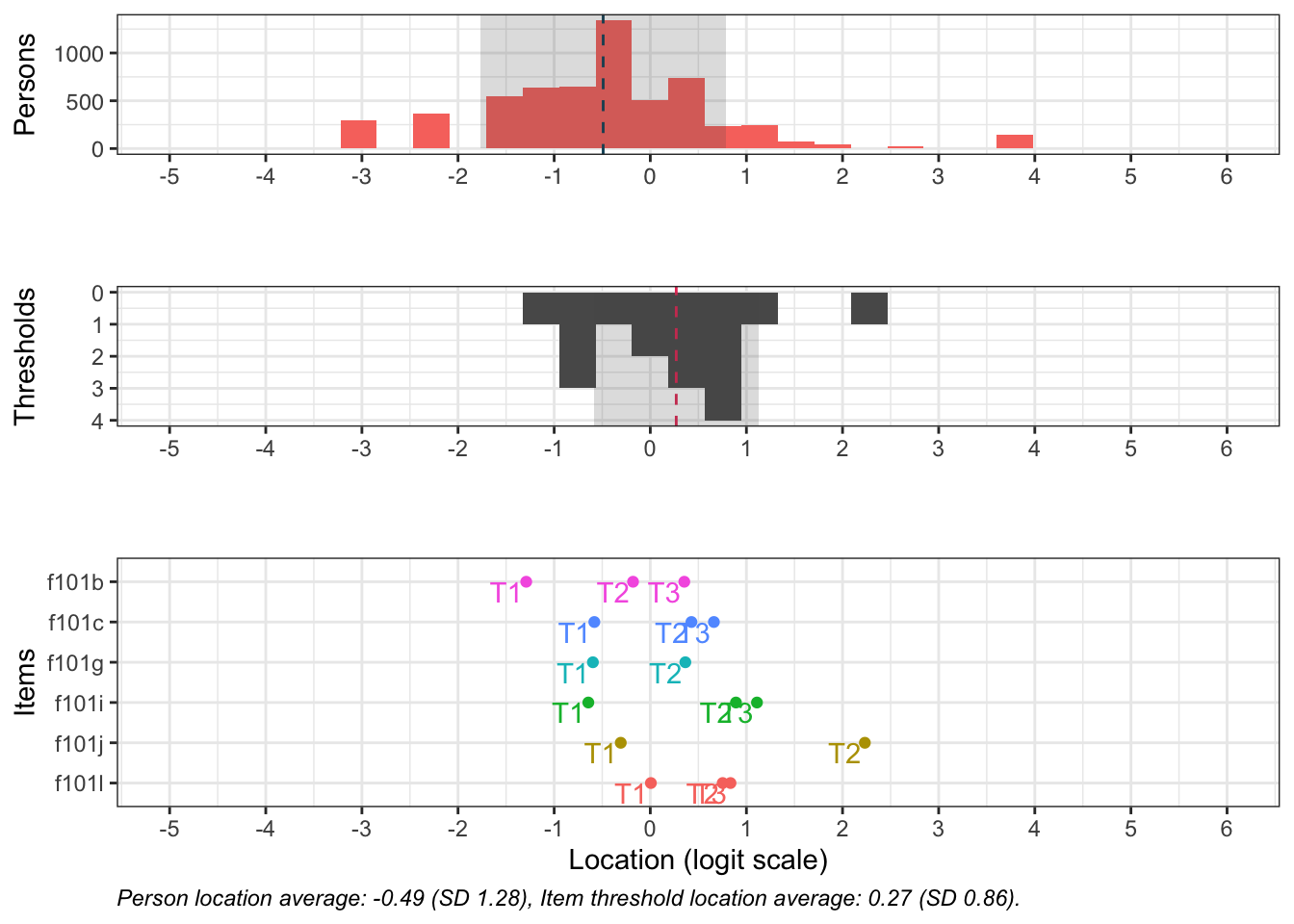
Denna figur visar hur väl items passar respondenterna (de som besvarat enkätfrågorna). Överst syns respondenternas indexvärden, där högre värden motsvarar högre risk.
Nederst finns frågornas tröskelvärden, som beskriver punkten på skalan där en högre svarskategori blir mer sannolik än den lägre. I mitten finns antalet tröskelvärden sammanräknade i staplar.
De två översta delarna visar även medelvärde för respondenter och item-trösklar med en streckad vertikal linje. I idealfallet ligger dessa medelvärden nära varandra, och de rosa och mörkgrå staplarna matchar varandra spegelvänt. Skulle de i stället ligga långt från varandra passar frågorna inte respondenterna.
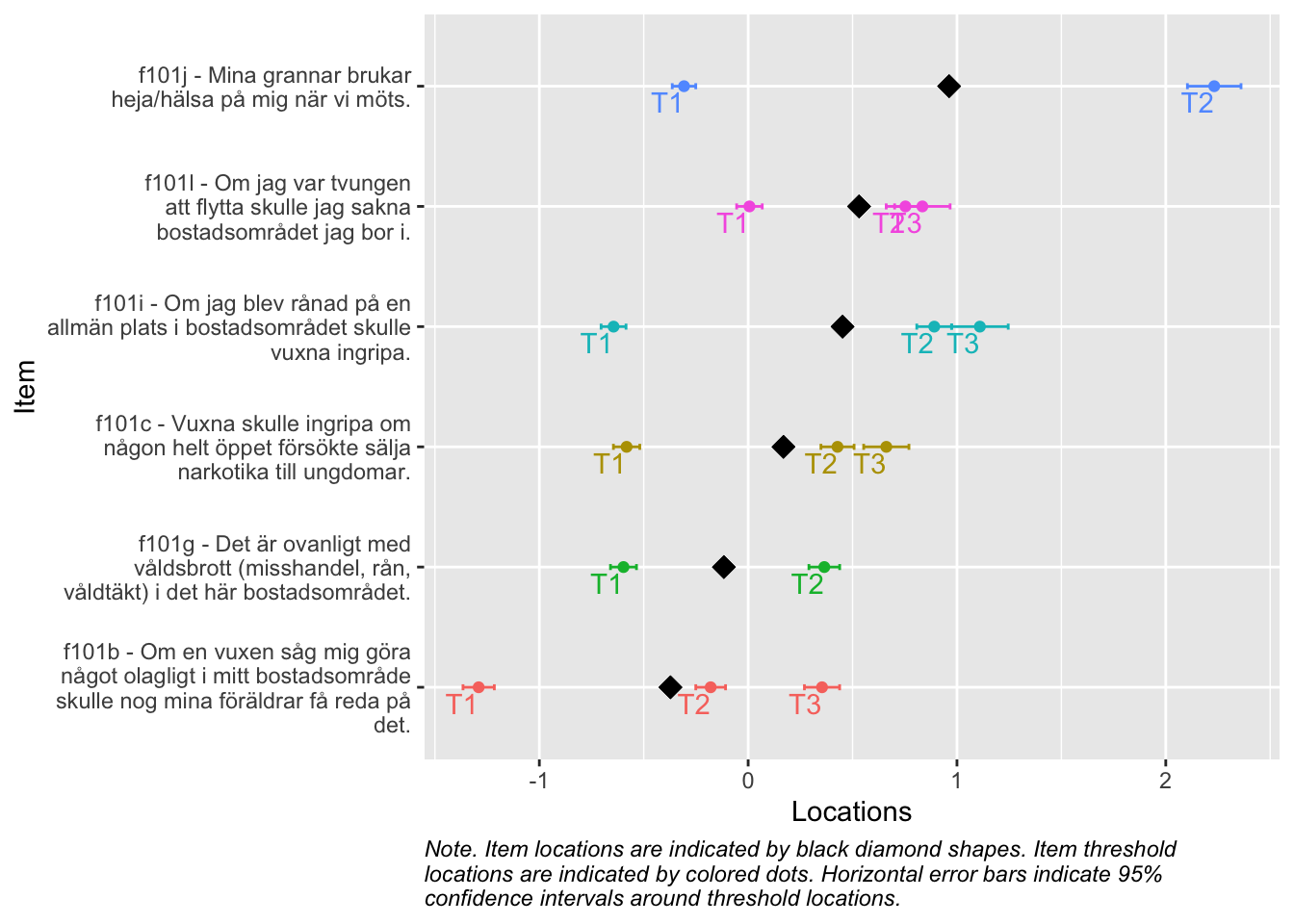
Denna figur rangordnar items för att tydliggöra vilka frågor som, utifrån svarsdata, ger information om olika nivåer av indexvärdet. Items som ligger högre upp mäter högre nivåer av indexet bättre, och omvänt.
1.8 Välbefinnande
Utifrån befintliga frågor har en explorativ analys genomförts för att undersöka möjligheten att ta fram ett index för välbefinnande. Det befintliga index som använts under rubriken “Psykisk hälsa” består av fem frågor om psykosomatiska besvär. Frånvaron av besvär har därmed varit underlag till uppskattning om “god psykisk hälsa”, vilket inte ter sig optimalt.
En uppsättning frågor från flera olika kontexter har använts för att försöka skapa ett brett mått på välbefinnande. Det är alltså befintliga frågor som använts i ny sammansättning, vilket gör att det går att ta fram indexvärden även bakåt i tiden. Dock har de två frågorna om framtidstro bara funnits med i enkäten sedan 2016.
1.8.1 Lista på items
| itemnr | item | Index |
|---|---|---|
| f54n | Jag ser fram emot att gå till lektionerna. | Skola |
| F92 | Hur mycket skulle du vilja ändra på dig själv? | Psykiska/psykosomatiska besvär |
| F99 | Hur ofta tycker du att det är riktigt härligt att leva? | Psykiska/psykosomatiska besvär |
| f83e | De märker när jag gör något bra. | Föräldraskap |
| F70 | Brukar du delta i någon ledarledd fritidsaktivitet eller träning? | Kamrater och fritid |
| f86a | Motionerar och tränar regelbundet? | Kamrater och fritid |
| f101j | Mina grannar brukar heja/hälsa på mig när vi möts. | Närsamhälle |
| F67 | Tycker du att det är viktigt vad du kommer att jobba med när du blir stor eller spelar det ingen roll? | Framtidstro |
| F68 | Om du jämför dina framtidsutsikter med de flesta andras i din ålder, tror du då att dina är sämre, lika bra, eller bättre? | Framtidstro |
Notera att f86a avser kamraters motion, medan F70 avser respondentens aktivitet.
Frågorna som ingår i detta index använder sig av tidigare genomförda justeringar av svarskategorier, där det är applicerbart.
Viktigt att komma ihåg att frågorna är vända så att höga svar = lågt välbefinnande. Detta kommer ändras i en framtida version av denna sammanfattning, men i dagsläget innebär det att figurerna nedan behöver “tänkas om”. Exempelvis kommer item-hierarkin att ha de items som bäst mäter höga nivåer av välbefinnande lägst i hierarkin.
1.8.2 Mätegenskaper
| itemnr | item |
|---|---|
| f54n | Jag ser fram emot att gå till lektionerna. |
| F92 | Hur mycket skulle du vilja ändra på dig själv? |
| F99 | Hur ofta tycker du att det är riktigt härligt att leva? |
| f83e | De märker när jag gör något bra. |
| F70 | Brukar du delta i någon ledarledd fritidsaktivitet eller träning? |
| f86a | Motionerar och tränar regelbundet? |
| f101j | Mina grannar brukar heja/hälsa på mig när vi möts. |
| F67 | Tycker du att det är viktigt vad du kommer att jobba med när du blir stor eller spelar det ingen roll? |
| F68 | Om du jämför dina framtidsutsikter med de flesta andras i din ålder, tror du då att dina är sämre, lika bra, eller bättre? |

Reliabilitetskurvan visar hur indexets frågor tillsammans ger olika mycket information om respondenterna längs indexets spann. Där kurvan är som högst har indexet bäst mätprecision och kan bäst urskilja olika nivåer av mätvärden.
De streckade linjerna i figuren motsvarar reliabilitet på 0.7 (nedre linjen) och 0.8, på en skala från 0 till 1. Att dessa värden indikeras i figuren beror på att konventionen är att 0.7 är den lägsta nivån som anses acceptabel. Helst bör så många respondenter som möjligt finnas inom det område där indexet/enkätfrågorna sammantaget uppnår reliabilitet på 0.7 eller högre. Figurtexten ger viktig information om hur indexets reliabilitet förhåller sig till respondenternas egenskaper.
Det är viktigt att visa reliabilitet som en kurva snarare en ett enskilt värde (som t.ex. Cronbach’s alpha), eftersom reliabiliteten aldrig är samma över hela skalan.
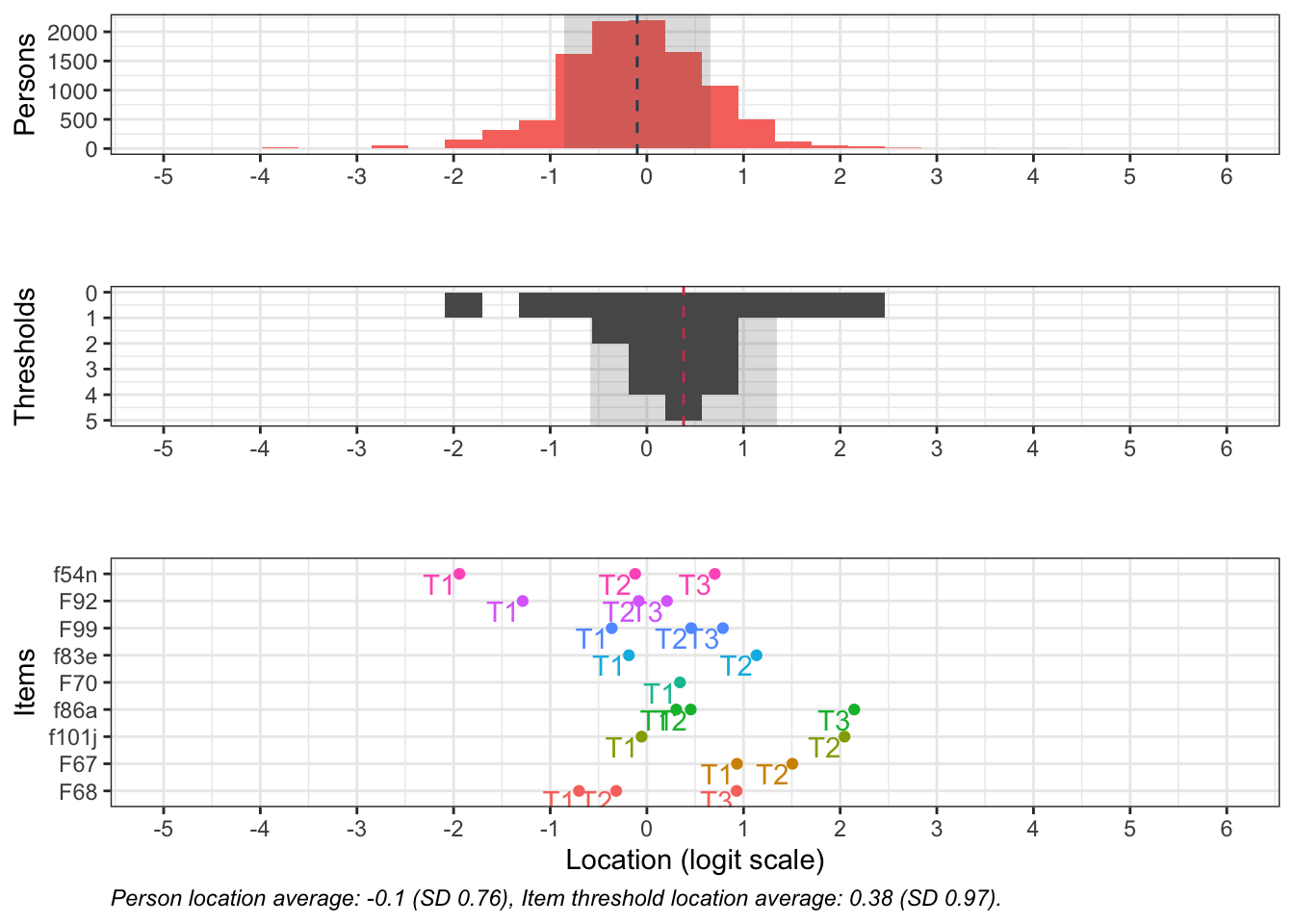
Denna figur visar hur väl items passar respondenterna (de som besvarat enkätfrågorna). Överst syns respondenternas indexvärden, där högre värden motsvarar högre risk.
Nederst finns frågornas tröskelvärden, som beskriver punkten på skalan där en högre svarskategori blir mer sannolik än den lägre. I mitten finns antalet tröskelvärden sammanräknade i staplar.
De två översta delarna visar även medelvärde för respondenter och item-trösklar med en streckad vertikal linje. I idealfallet ligger dessa medelvärden nära varandra, och de rosa och mörkgrå staplarna matchar varandra spegelvänt. Skulle de i stället ligga långt från varandra passar frågorna inte respondenterna.
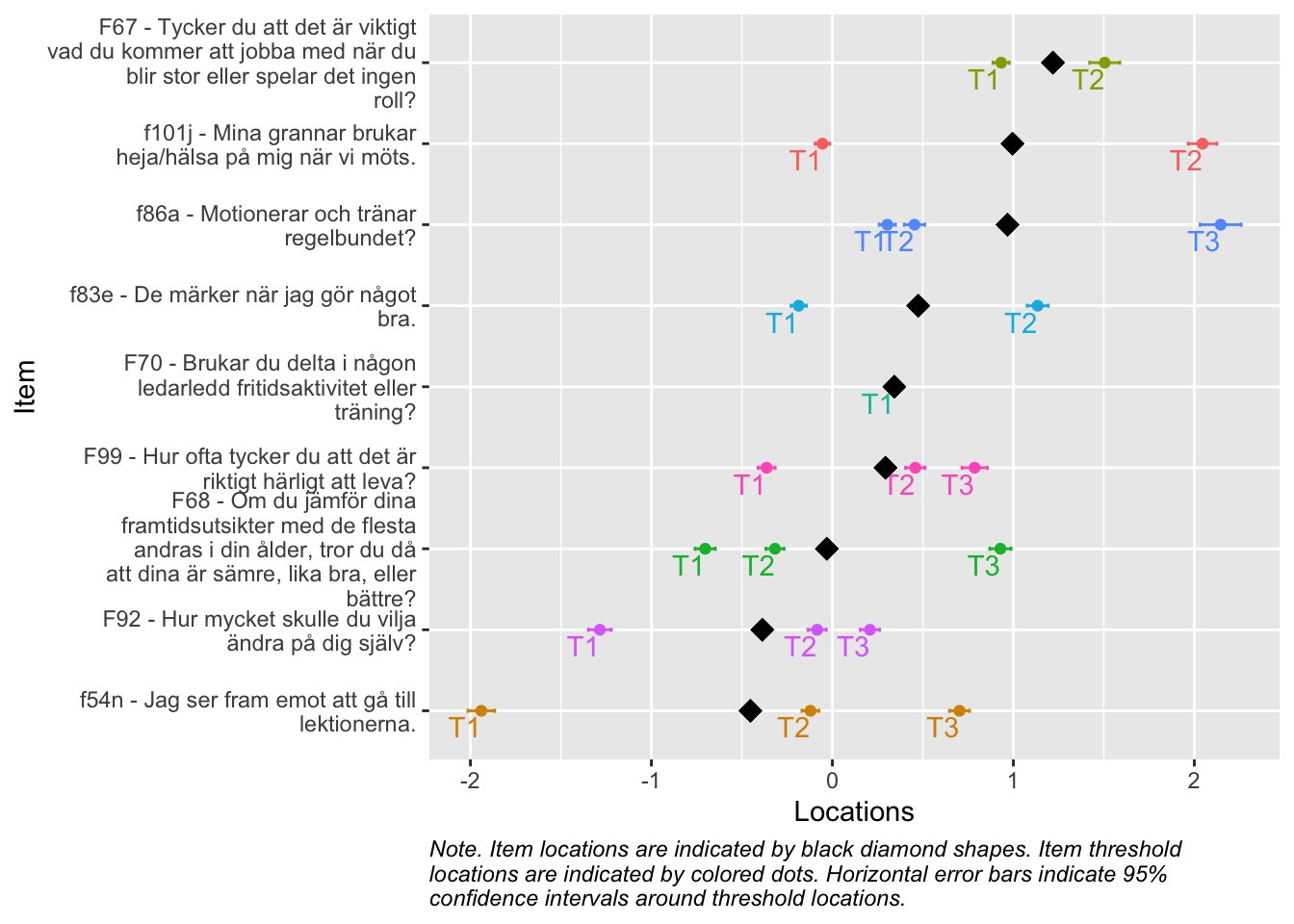
Denna figur rangordnar items för att tydliggöra vilka frågor som, utifrån svarsdata, ger information om olika nivåer av indexvärdet. Items som ligger högre upp mäter högre nivåer av indexet bättre, och omvänt.
1.9 Programvara som använts för att genomföra analyser och skapa denna rapport
| Package | Version | Citation |
|---|---|---|
| arrow | 11.0.0.3 | Richardson et al. (2023) |
| base | 4.2.3 | R Core Team (2023) |
| car | 3.1.1 | Fox and Weisberg (2019) |
| cowplot | 1.1.1 | Wilke (2020) |
| eRm | 1.0.2 | Mair and Hatzinger (2007b); Mair and Hatzinger (2007a); Hatzinger and Rusch (2009); Rusch, Maier, and Hatzinger (2013); Koller, Maier, and Hatzinger (2015); Debelak and Koller (2019); Mair, Hatzinger, and Maier (2021) |
| formattable | 0.2.1 | Ren and Russell (2021) |
| ggrepel | 0.9.3 | Slowikowski (2023) |
| glue | 1.6.2 | Hester and Bryan (2022) |
| kableExtra | 1.3.4 | Zhu (2021) |
| knitr | 1.42 | Xie (2014); Xie (2015); Xie (2023) |
| matrixStats | 0.63.0 | Bengtsson (2022) |
| mirt | 1.37.1 | Chalmers (2012) |
| psych | 2.3.3 | William Revelle (2023) |
| psychotree | 0.16.0 | Trepte and Verbeet (2010); Strobl, Wickelmaier, and Zeileis (2011); Strobl, Kopf, and Zeileis (2015); Komboz, Zeileis, and Strobl (2018); Wickelmaier and Zeileis (2018) |
| reshape | 0.8.9 | Wickham (2007) |
| RISEkbmRasch | 0.1.14.3 | Johansson (2023) |
| rmarkdown | 2.21 | Xie, Allaire, and Grolemund (2018); Xie, Dervieux, and Riederer (2020); Allaire et al. (2023) |
| tidyverse | 2.0.0 | Wickham et al. (2019) |
1.10 Referenser
Allaire, JJ, Yihui Xie, Christophe Dervieux, Jonathan McPherson, Javier Luraschi, Kevin Ushey, Aron Atkins, et al. 2023. rmarkdown: Dynamic Documents for r. https://github.com/rstudio/rmarkdown.
Bengtsson, Henrik. 2022. matrixStats: Functions That Apply to Rows and Columns of Matrices (and to Vectors). https://CRAN.R-project.org/package=matrixStats.
Chalmers, R. Philip. 2012. “mirt: A Multidimensional Item Response Theory Package for the R Environment.” Journal of Statistical Software 48 (6): 1–29. https://doi.org/10.18637/jss.v048.i06.
Debelak, Rudolf, and Ingrid Koller. 2019. “Testing the Local Independence Assumption of the Rasch Model With Q3-Based Nonparametric Model Tests.” Applied Psychological Measurement. https://doi.org/10.1177/0146621619835501.
Fox, John, and Sanford Weisberg. 2019. An R Companion to Applied Regression. Third. Thousand Oaks CA: Sage. https://socialsciences.mcmaster.ca/jfox/Books/Companion/.
Hatzinger, Reinhold, and Thomas Rusch. 2009. “IRT models with relaxed assumptions in eRm: A manual-like instruction.” Psychology Science Quarterly 51.
Hester, Jim, and Jennifer Bryan. 2022. glue: Interpreted String Literals. https://CRAN.R-project.org/package=glue.
Johansson, Magnus. 2021. Risk- och skyddsfaktorer vad vet vi och vad kan göras med kunskapen? RISE rapport 2022:34. Stockholm: RISE Research Institutes of Sweden. http://urn.kb.se/resolve?urn=urn:nbn:se:ri:diva-59175.
———. 2023. RISEkbmRasch: Psychometric Analysis in r with Rasch Measurement Theory. https://github.com/pgmj/RISEkbmRasch.
Johansson, Magnus, Marit Preuter, Simon Karlsson, Marie-Louise Möllerberg, Hanna Svensson, and Jeanette Melin. 2023. “Valid and Reliable? Basic and Expanded Recommendations for Psychometric Reporting and Quality Assessment.” https://doi.org/10.31219/osf.io/3htzc.
Johansson, Magnus, Hanna Svensson, and Jeanette Melin. 2021. Mätning av mjuka värden - hur får vi bra beslutsunderlag? RISE rapport 2022:35. Stockholm: RISE Research Institutes of Sweden. https://www.diva-portal.org/smash/record.jsf?dswid=3541.
Koller, Ingrid, Marco Johannes Maier, and Reinhold Hatzinger. 2015. “An Empirical Power Analysis of Quasi-Exact Tests for the Rasch Model: Measurement Invariance in Small Samples.” Methodology 11. https://doi.org/10.1027/1614-2241/a000090.
Komboz, Basil, Achim Zeileis, and Carolin Strobl. 2018. “Tree-Based Global Model Tests for Polytomous Rasch Models.” Educational and Psychological Measurement 78 (1): 128–66. https://doi.org/10.1177/0013164416664394.
Mair, Patrick, and Reinhold Hatzinger. 2007a. “CML based estimation of extended Rasch models with the eRm package in R.” Psychology Science 49.
———. 2007b. “Extended Rasch modeling: The eRm package for the application of IRT models in R.” Journal of Statistical Software 20. https://www.jstatsoft.org/v20/i09.
Mair, Patrick, Reinhold Hatzinger, and Marco Johannes Maier. 2021. eRm: Extended Rasch Modeling. https://cran.r-project.org/package=eRm.
Preuter, Marit, Magnus Johansson, and Tomas Bokström. 2022. Strukturer och indikatorer för uppföljning av föräldraskapsstöd. RISE rapport 2022:70. RISE Research Institutes of Sweden. http://urn.kb.se/resolve?urn=urn:nbn:se:ri:diva-59978.
R Core Team. 2023. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.
Ren, Kun, and Kenton Russell. 2021. formattable: Create “Formattable” Data Structures. https://CRAN.R-project.org/package=formattable.
Richardson, Neal, Ian Cook, Nic Crane, Dewey Dunnington, Romain François, Jonathan Keane, Dragoș Moldovan-Grünfeld, Jeroen Ooms, and Apache Arrow. 2023. arrow: Integration to “Apache” “Arrow”. https://CRAN.R-project.org/package=arrow.
Rusch, Thomas, Marco Johannes Maier, and Reinhold Hatzinger. 2013. “Linear logistic models with relaxed assumptions in R.” In Algorithms from and for Nature and Life, edited by Berthold Lausen, Dirk van den Poel, and Alfred Ultsch. Studies in Classification, Data Analysis, and Knowledge Organization. New York: Springer. https://doi.org/10.1007/978-3-319-00035-0_34.
Slowikowski, Kamil. 2023. ggrepel: Automatically Position Non-Overlapping Text Labels with “ggplot2”. https://CRAN.R-project.org/package=ggrepel.
Strobl, Carolin, Julia Kopf, and Achim Zeileis. 2015. “Rasch Trees: A New Method for Detecting Differential Item Functioning in the Rasch Model.” Psychometrika 80 (2): 289–316. https://doi.org/10.1007/s11336-013-9388-3.
Strobl, Carolin, Florian Wickelmaier, and Achim Zeileis. 2011. “Accounting for Individual Differences in Bradley-Terry Models by Means of Recursive Partitioning.” Journal of Educational and Behavioral Statistics 36 (2): 135–53. https://doi.org/10.3102/1076998609359791.
Trepte, Sabine, and Markus Verbeet, eds. 2010. Allgemeinbildung in Deutschland – Erkenntnisse Aus Dem SPIEGEL Studentenpisa-Test. Wiesbaden: VS Verlag.
Wickelmaier, Florian, and Achim Zeileis. 2018. “Using Recursive Partitioning to Account for Parameter Heterogeneity in Multinomial Processing Tree Models.” Behavior Research Methods 50 (3): 1217–33. https://doi.org/10.3758/s13428-017-0937-z.
Wickham, Hadley. 2007. “Reshaping Data with the Reshape Package.” Journal of Statistical Software 21 (12). https://www.jstatsoft.org/v21/i12/.
Wickham, Hadley, Mara Averick, Jennifer Bryan, Winston Chang, Lucy D’Agostino McGowan, Romain François, Garrett Grolemund, et al. 2019. “Welcome to the tidyverse.” Journal of Open Source Software 4 (43): 1686. https://doi.org/10.21105/joss.01686.
Wilke, Claus O. 2020. cowplot: Streamlined Plot Theme and Plot Annotations for “ggplot2”. https://CRAN.R-project.org/package=cowplot.
William Revelle. 2023. psych: Procedures for Psychological, Psychometric, and Personality Research. Evanston, Illinois: Northwestern University. https://CRAN.R-project.org/package=psych.
Xie, Yihui. 2014. “knitr: A Comprehensive Tool for Reproducible Research in R.” In Implementing Reproducible Computational Research, edited by Victoria Stodden, Friedrich Leisch, and Roger D. Peng. Chapman; Hall/CRC.
———. 2015. Dynamic Documents with R and Knitr. 2nd ed. Boca Raton, Florida: Chapman; Hall/CRC. https://yihui.org/knitr/.
———. 2023. knitr: A General-Purpose Package for Dynamic Report Generation in r. https://yihui.org/knitr/.
Xie, Yihui, J. J. Allaire, and Garrett Grolemund. 2018. R Markdown: The Definitive Guide. Boca Raton, Florida: Chapman; Hall/CRC. https://bookdown.org/yihui/rmarkdown.
Xie, Yihui, Christophe Dervieux, and Emily Riederer. 2020. R Markdown Cookbook. Boca Raton, Florida: Chapman; Hall/CRC. https://bookdown.org/yihui/rmarkdown-cookbook.
Zhu, Hao. 2021. kableExtra: Construct Complex Table with “kable” and Pipe Syntax. https://CRAN.R-project.org/package=kableExtra.